Writing Google Sheets Data to MySQL using Python
In data jobs, we often use different methods of writing and analyzing data. Google sheets is a great way to collaboratively enter and share data. For larger datasets, Google sheets becomes painfully slow to work with, and one way around that is to create a new worksheet when there are too many rows. One project my team is working on creates 3000 rows a week, which isn’t much data by most standards, but it gets bogged down after a few weeks. Team members started archiving worksheets, which made it very difficult to do any aggregation on the data. I decided it was a better idea to write all our data to a MySQL table, which also allows other teams to join our data to other tables they are working with. I will walk you through the process of doing this using Python. For this project, I will be using Jupyter Notebook, Python 3.7.1, and MySQL Workbench 8.0 on a Windows machine.
Data in Google Sheets
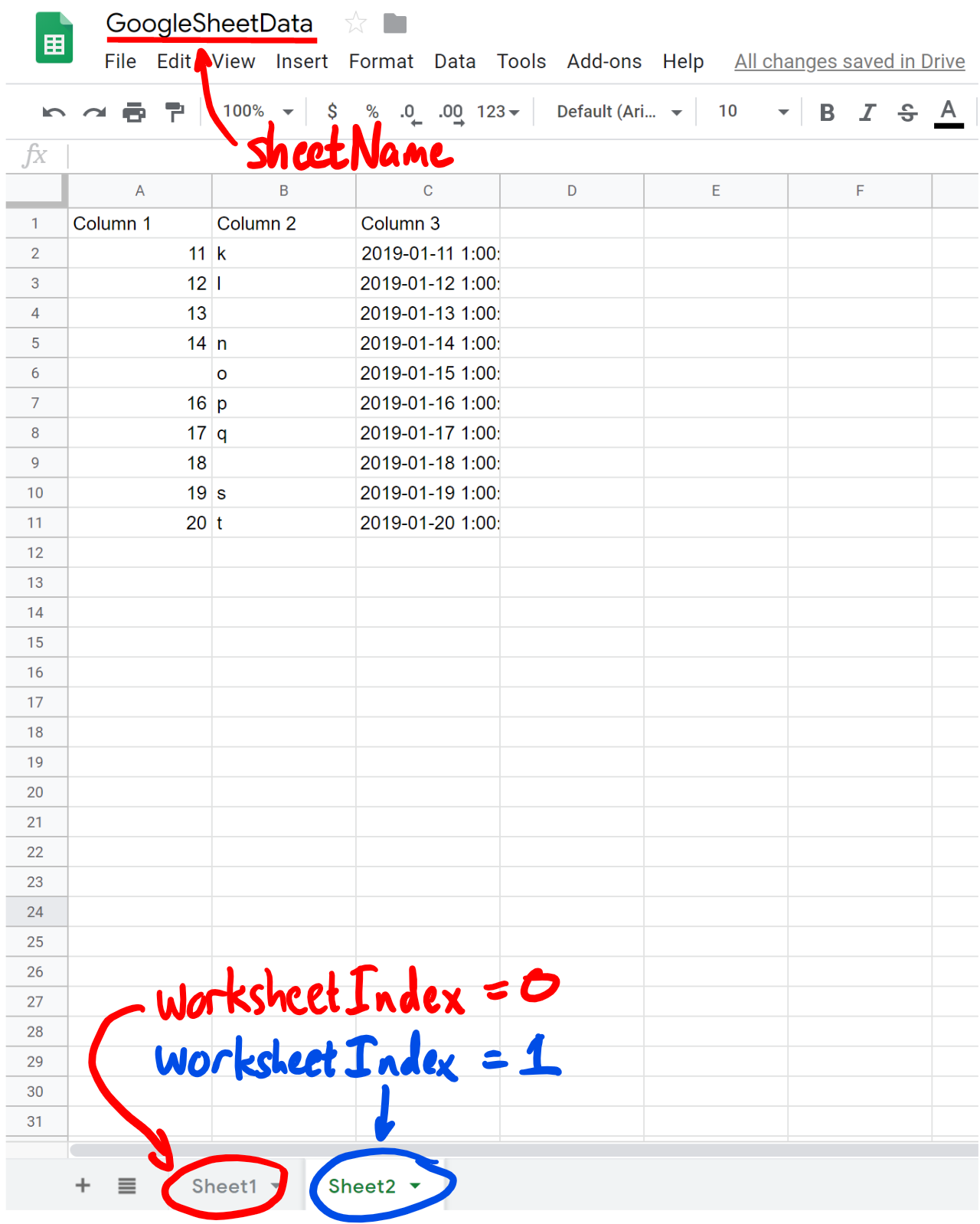
I created a small dataset for this project using Google sheets. I included two worksheets, the first looks like:


Notice that I have intentionally left two cells blank in Column 2. This will be for an example later. The second worksheet (a second tab at the bottom) looks like:

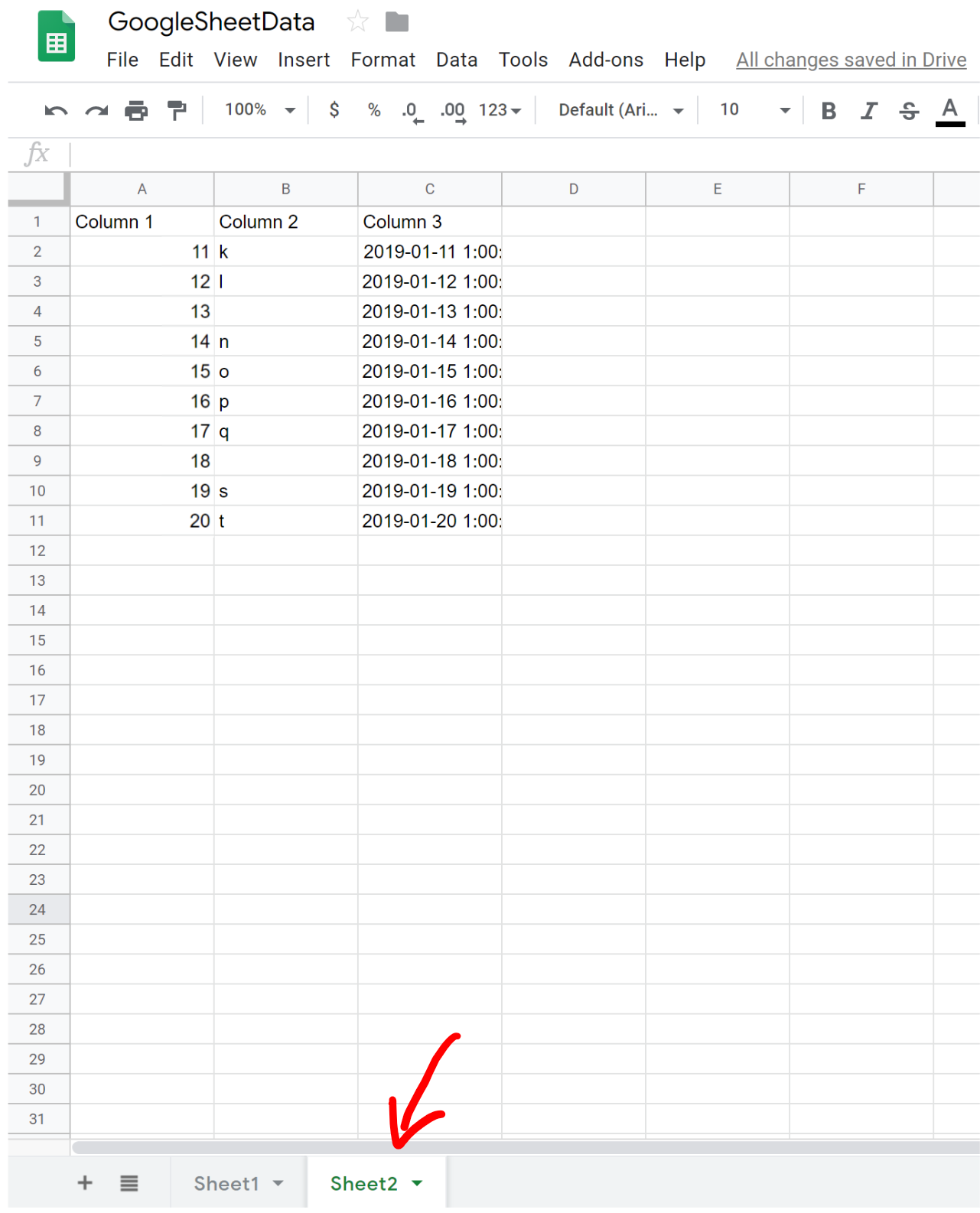
Connecting Google Sheets to Python
The first thing we need to do is access the Google developers console using this link. Create a new project by clicking on the “CREATE PROJECT” link at the top of the page:

Name the project something relevant, as shown below.


Next, we need to create a service account for the project. Click on the navigation menu at the top left of the page (3 horizontal lines, often called a hamburger), and select “Service Accounts”:
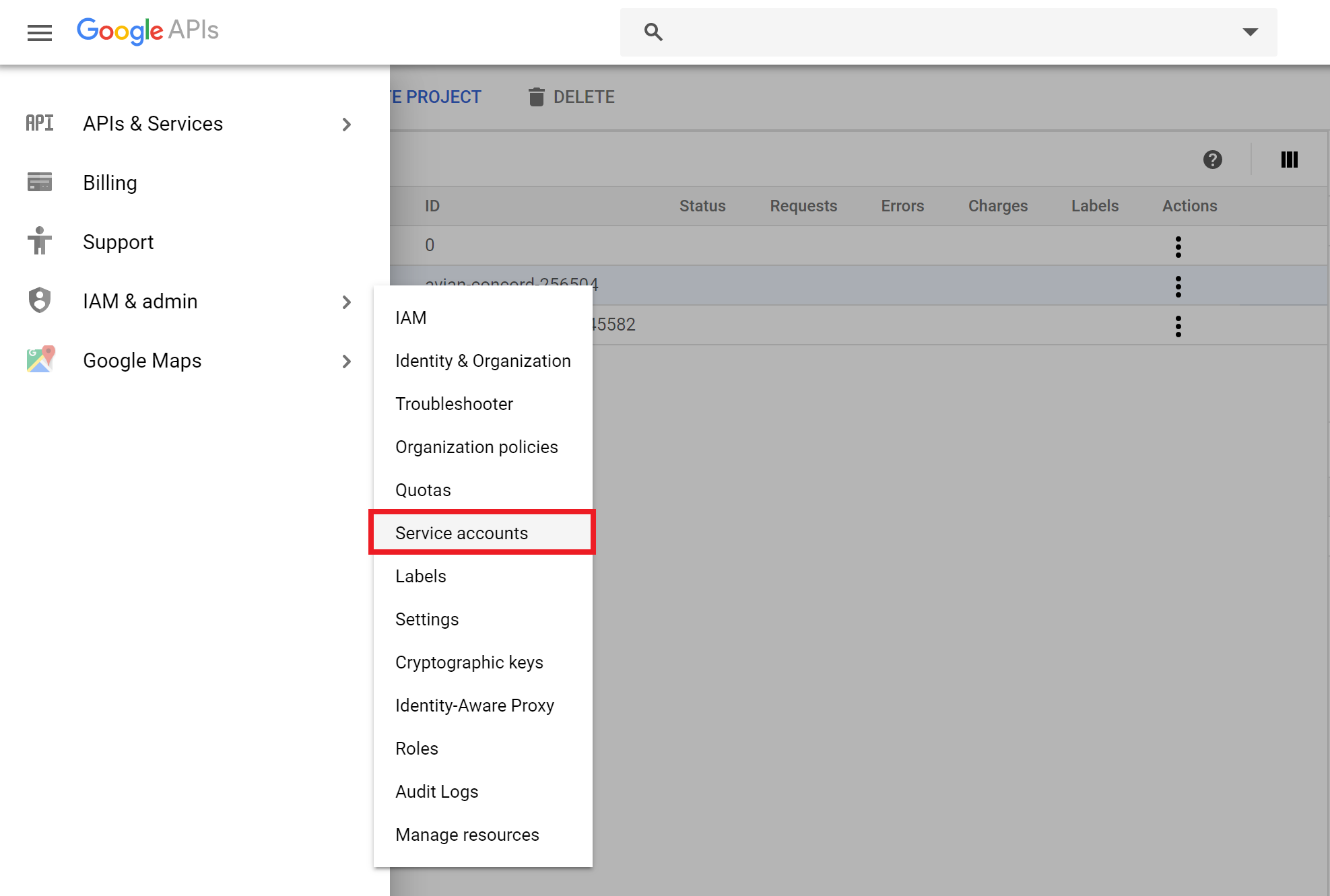
You will need to select your project from the top of the page (a) and then hit “CREATE SERVICE ACCOUNT” (b).

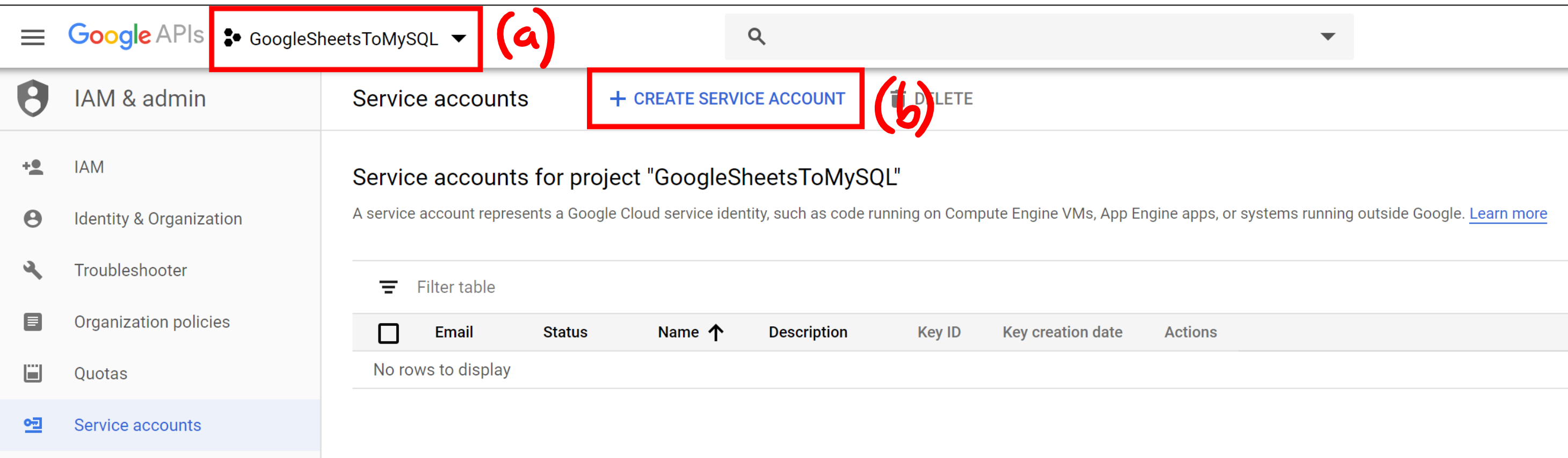
Give the service account a meaningful name and click “CREATE”. Next we will set the service account permissions role to owner and click “CONTINUE”. On the next page we will skip the “grant users access to this service account” section, and move on to the “Create key” section below. This will open up a side bar that allows us to select a key type. Select “JSON” and hit “CREATE”. This will save the JSON file to your computer, and we will be using this file to grab some information out of.
Open the JSON file using something like Notepad++. Find the line which contains “Client email”, and copy the entire email address (between the quotes) to your clipboard. Next, go back to your Google sheet which contains the data you want to write to a MySQL table. Click on the green button labeled “Share” in the upper right of the spreadsheet. Paste the email address from the JSON file into the field and click “Send”. This will allow our Python program to access this Google sheet.
Setting Up Jupyter Notebook
Now that everything is set up, we can move on to Python! For this tutorial, I am using Jupyter Notebook and Python 3.7.1. If you do not have Python installed on your machine, you will need to do so. Jupyter Notebook comes with Anaconda, which is a great package for Python. You can launch Jupyter Notebook by typing into the search bar (in Windows, on the taskbar) “Jupyter Notebook”, or you can launch the Anaconda prompt, and once the prompt is open, type “Jupyter Notebook” without the quotes, but we will need the Anaconda prompt later so I suggest using the first method described.
Jupyter Notebook will launch in your browser. You will be directed to your working directory. You can navigate to a different folder, but for now we will create a new notebook by clicking “New” in the upper right of the page and selecting a Python 3 notebook:


Let’s rename the notebook to “GoogleSheetsToMySQL” by clicking on the notebook name (Untitled) at the top of the page. Next, we need to move the JSON file we downloaded to our working directory. I believe the default directory is under “C://users//your_username”.
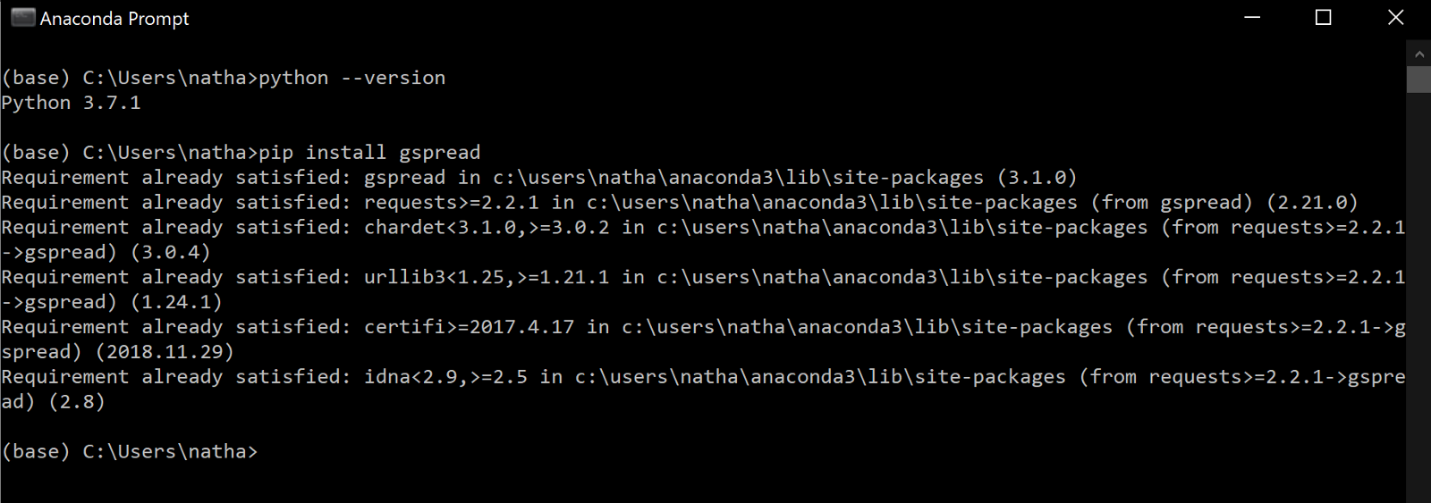
Before we can start coding, we will need to install a few modules. To install the modules we need, open the Anaconda prompt (you can find this in the Windows search bar on the taskbar). In the Anaconda prompt, you will need to install the following modules. Use pip by typing the following commands and hitting enter after each:
- pip install gspread
- pip install oauth2client
- pip install mysql-connector
I have these already installed, as shown by the output of the command prompt (when attempting to install gspread):

Since we will be accessing a MySQL database, it is important not to expose our login credentials in our code. We will create a Python file (.py) and store these credentials there. We can then import them into our Jupyter Notebook script easily. The quickest way to create your .py file is with Notepad++. I used PyCharm for this, but use whichever IDE you prefer. Open your IDE and create a file called “MySQLCredentials.py”. In this file, we just need to type 4 lines and save it to our working directory. We need:
user = (your username)password = (your password)host = (hostname)database = (database schema you will be using)
Save the file and drop it into your working directory.
Coding In Jupyter Notebook
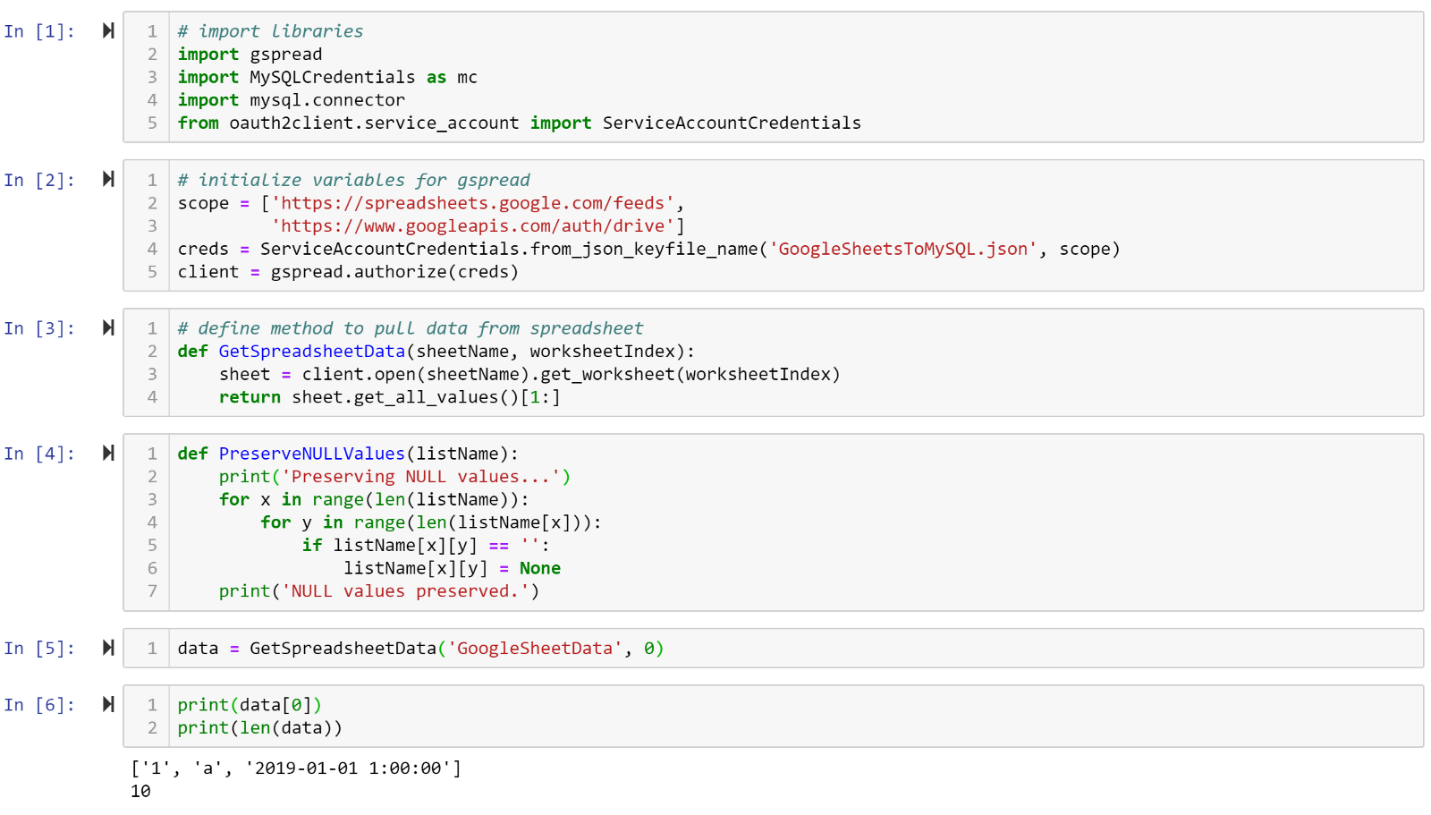
Now, back to your notebook. We need to import the modules we will be using by entering into our first cell the following:
# import librariesimport gspreadimport MySQLCredentials as mcimport mysql.connectorfrom oauth2client.service_account import ServiceAccountCredentials
Run the cell and if you don’t get any errors, great! Next we need to initialize some variables to use with gspread:
# initialize variables for gspreadscope = [‘https://spreadsheets.google.com/feeds',‘https://www.googleapis.com/auth/drive']creds = ServiceAccountCredentials.from_json_keyfile_name(‘GoogleSheetsToMySQL.json’, scope)client = gspread.authorize(creds)
If you named your JSON file something different, just make sure the name is correct in the code above. Now we need to define a method which will pull data from the Google sheet:
# define method to pull data from spreadsheetdef GetSpreadsheetData(sheetName, worksheetIndex): sheet = client.open(sheetName).get_worksheet(worksheetIndex) return sheet.get_all_values()[1:]
We are defining a method with two parameters. We need to tell it what sheet name we are referencing, and the worksheet index. The worksheet index refers to which sheet tab we are referencing. The first tab has an index of 0, the second tab has an index of 1, and so on. We won’t need these values until we call the method, so we will get back to that shortly. The return type for this method is a list, and it will return all values on that sheet. We then slice the list using [1:] which will remove the first element of the list. Since the Google sheet has a header with column names, this will drop that so we only pull the data from the sheet.
Before we move on, let’s check that this method can grab data from our sheet.

In a new cell in the notebook, enter
data = GetSpreadsheetData(‘GoogleSheetData’, 0)
You might get an error saying you need to enable the Drive API. It will provide a link which you can click on to enable the Drive API. Now rerun the cell and make sure you don’t get any errors. I had to run it a few times to enable 2 separate APIs and had to wait a minute before it ran without giving me an error. You should not need to do this again. OK, now check that you have the data you expect. You can check the first row of the list, as well as the length of the list (in this case, how many rows of data):
print(data[0])
print(len(data))
which should return
[‘1’, ‘a’, ‘2019–01–01 1:00:00’]
10
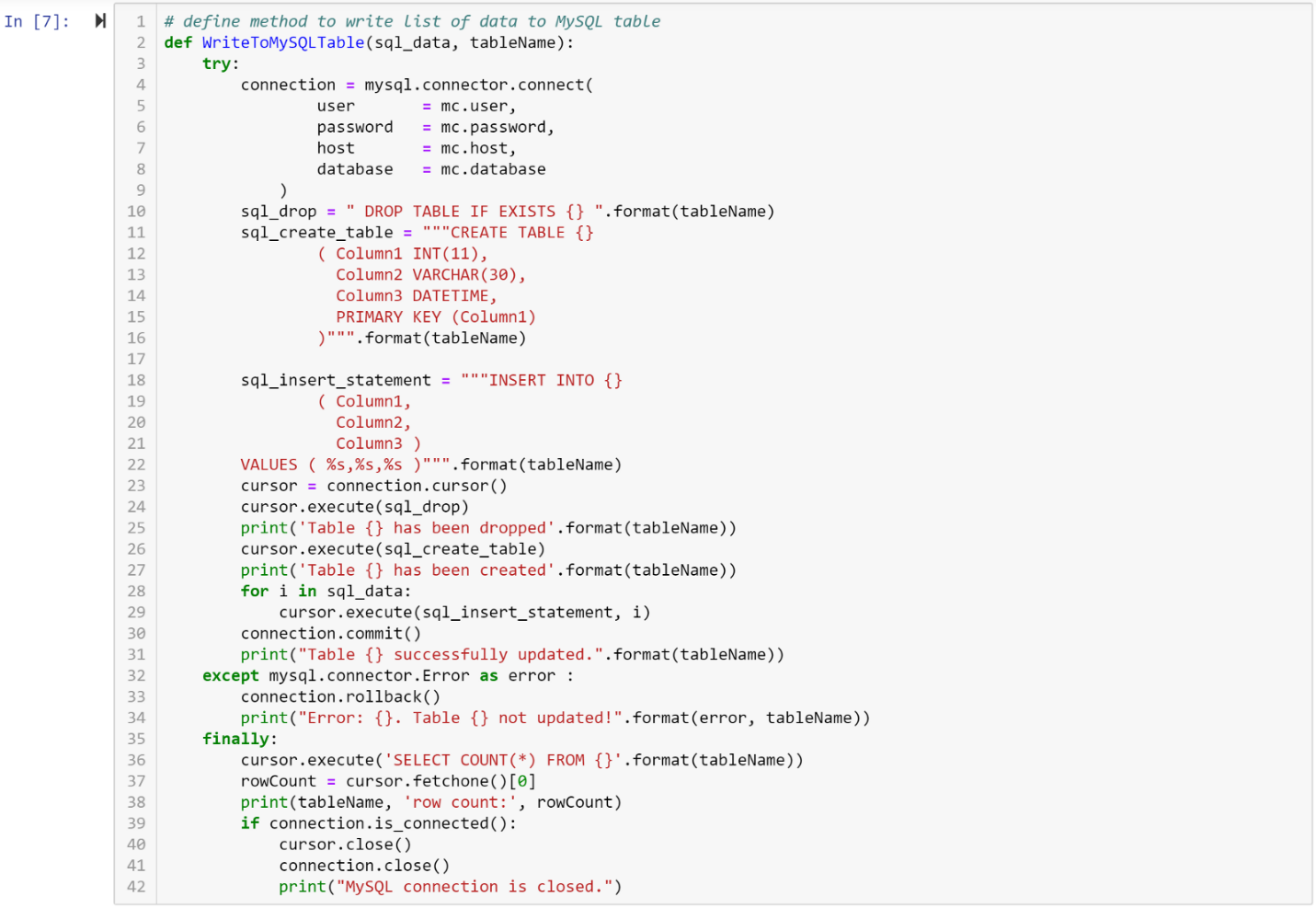
Now we need to set up a method to write this data to MySQL. Using a try-except-finally block will be useful here. There are several blocks of comments, indicated by having # in front of them, which are only for clarification:
# define method to write list of data to MySQL tabledef WriteToMySQLTable(sql_data, tableName):# we are using a try/except block (also called a try/catch block in other languages) which is good for error handling. It will “try” to execute anything in the “try” block, and if there is an error, it will report the error in the “except” block. Regardless of any errors, the “finally” block will always be executed. try:# Here we include the connection credentials for MySQL. We create a connection object that we pass the credentials to, and notice that we can specify the database which is ‘sys’ in the MySQLCredentials.py file because I’m using since I’m using the default database in MySQL Workbench 8.0. connection = mysql.connector.connect( user = mc.user, password = mc.password, host = mc.host, database = mc.database )# This command will drop the table, and we could just have the table name hardcoded into the string, but instead I am using the name of the table passed into the method. {} is a placeholder for what we want to pass into this string, and using .format(blah) we can pass the string name from the variable passed into the method here. sql_drop = “ DROP TABLE IF EXISTS {} “.format(tableName)# Now we will create the table, and the triple quotes are used so that when we go to the next line of code, we remain in a string. Otherwise it will terminate the string at the end of the line, and we want ALL of this to be one giant string. When injecting data into VALUES, we use the placeholder %s for each column of data we have. sql_create_table = “””CREATE TABLE {}( Column1 INT(11), Column2 VARCHAR(30), Column3 DATETIME, PRIMARY KEY (Column1) )”””.format(tableName) sql_insert_statement = “””INSERT INTO {}( Column1, Column2, Column3 ) VALUES ( %s,%s,%s )”””.format(tableName)# Here we create a cursor, which we will use to execute the MySQL statements above. After each statement is executed, a message will be printed to the console if the execution was successful. cursor = connection.cursor() cursor.execute(sql_drop) print(‘Table {} has been dropped’.format(tableName)) cursor.execute(sql_create_table) print(‘Table {} has been created’.format(tableName))# We need to write each row of data to the table, so we use a for loop that will insert each row of data one at a time for i in sql_data: cursor.execute(sql_insert_statement, i)# Now we execute the commit statement, and print to the console that the table was updated successfully connection.commit() print(“Table {} successfully updated.”.format(tableName))# Errors are handled in the except block, and we will get the information printed to the console if there is an error except mysql.connector.Error as error : connection.rollback() print(“Error: {}. Table {} not updated!”.format(error, tableName))# We need to close the cursor and the connection, and this needs to be done regardless of what happened above. finally: cursor.execute(‘SELECT COUNT(*) FROM {}’.format(tableName)) rowCount = cursor.fetchone()[0] print(tableName, ‘row count:’, rowCount) if connection.is_connected(): cursor.close() connection.close() print(“MySQL connection is closed.”)
To test this, let’s run the following command (you will have needed to run the GetSpreadsheetData() method or you will not have “data” defined.
WriteToMySQLTable(data, ‘MyData’)
The output should be:
Table MyData has been dropped
Table MyData has been created
Table MyData successfully updated.
MyData row count: 10
MySQL connection is closed.
Checking the data in MySQL Workbench looks successful, but there is one issue that needs to be addressed. Here is the table in MySQL Workbench:

Notice that we have 2 possible issues. The very last row is all NULL, which we most likely do not expect this row to be included. But more importantly, the missing values in Column2 are NOT NULL! This is because Python is reading the sheet data and sees a blank value, which is most likely interpreted as an empty string. We probably do not want empty strings here and expect NULL values instead. So let’s write a method to cleanup the empty string values and write them as NULL values.
def PreserveNULLValues(listName):
print(‘Preserving NULL values…’)
for x in range(len(listName)):
for y in range(len(listName[x])):
if listName[x][y] == ‘’:
listName[x][y] = None
print(‘NULL values preserved.’)
What this does is check for empty string values (‘’) and replace them with the Python keyword “None”, which will be written to MySQL as a NULL value. Let’s check this:
data = GetSpreadsheetData(‘GoogleSheetData’, 0)
PreserveNULLValues(data)
WriteToMySQLTable(data, ‘MyData’)
Let’s check in MySQL Workbench to see what this looks like:
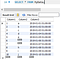

Much better! I don’t normally get a NULL row at the end, but we can drop this if we need to.
Now let’s say we wanted to update the table with our second worksheet, with worksheet index = 1. This time we don’t want to drop the table, we just want to insert into it. We can define a new method called UpdateMySQLTable. We are going to use the same method described above (WriteToMySQLTable) except we will delete the following lines of code:
sql_drop = …
sql_create_table = …
Run this method with the new worksheet index:
data = GetSpreadsheetData(‘GoogleSheetData’, 1)
PreserveNULLValues(data)
UpdateMySQLTable(data, ‘MyData’)
And you will now have a table with 20 rows, 10 from each sheet. Here is what the resulting table looks like in MySQL Workbench:

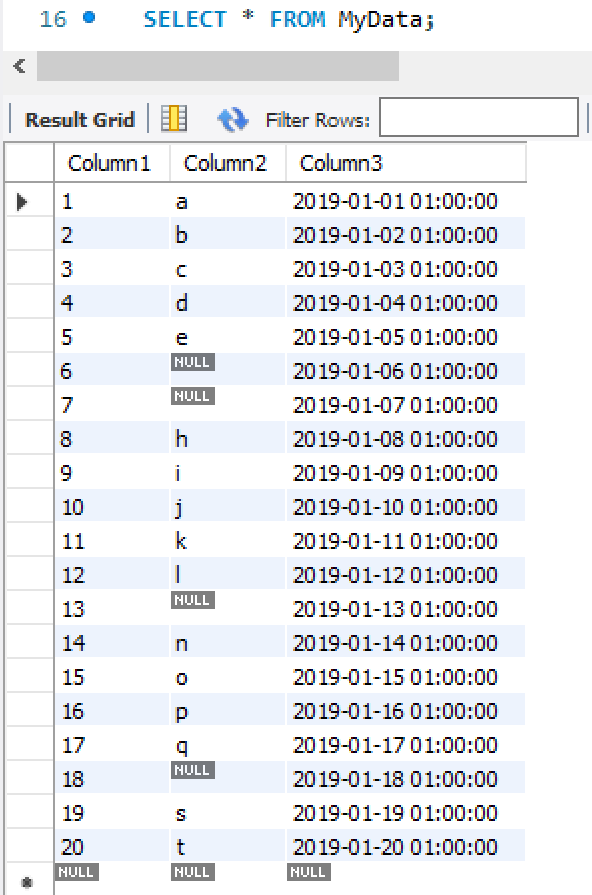
Just make sure that the column names and orders match, otherwise you will have to arrange them so that they do. For my team’s data, sometimes we will write in a new column if our methodology changes, and I will go back and insert empty columns into the older tabs and re-import all the data. Now you can take advantage of having a database in MySQL with the functionality of Google sheets! Here is what my code looks like in Jupyter Notebook. Happy coding!








No comments:
Post a Comment