As a former instructor for General Assembly’s Data Science Immersive, I taught over a thousand students how to solve problems with data, and the privilege to author and curate a sizable chunk of the schools’ curriculum from the beginning. For the record, I don’t endorse any of the available data science bootcamps or educational programs at present. However, I have advice for anyone who has taken a data science bootcamp wondering what to study next (or aspiring data scientists).
Why Bootamps?


Let’s take, for instance, a popular college program such as UC Berkeley’s Master of Information and Data Science. To attend and earn a data science master’s from UCB requires an excess of $60k, prerequisites in calculus, linear algebra, a piece of paper called a bachelor’s degree in a related quantitative field, and good grades in basic collegiate-level engineering classes. This is reflective of the majority of college programs today. College isn’t as accessible if you are self-taught, or are without more formal math, statistics, and engineering background.
Indeed, there are better options for the money if you want to follow the college route (i.e., Georgia Tech’s Online Master of Science in Analytics).
Data science bootcamps frequently come in 2 flavors:
- Part-time: 10–12 Weeks @ ~6 hours / per week at night
- Full-time: 10–12 weeks @ 40 hours / per week 9am–5pm
The idea sold, and sometimes strongly implied, to prospective students is that one can become a data science expert in a short period of dedicated study. For the $2–6k you spend to attend a part-time class or $16k+ for full-time, while still committing quite a bit of time and resources, in either case, is still less than you would otherwise commit to for a full-on masters program. Also, many data science bootcamps offer to finance, so along with having fewer prerequisites to attend a bootcamp; these are compelling reasons on paper when you weigh the cost-benefit of such an opportunity.
The softer prerequisites of data science bootcamps are also an aspect this route provides, which is both advantageous but also guarantees variances in the knowledge and capabilities of your potential classmates. Mainly, what’s offered, depending on the school, is some form of assessment that measures prerequisite knowledge and your ability with math, statistics, and essential Python or R fundamentals. The results of the evaluation are authoritative to a list of materials and shorter form classes on the specific subjects that you are required to study. This admissions process, which directs students to specific areas of study, contrasts with a traditional college program in that a bootcamp admissions process allows you to study a very concise set of topics, based on your assessment, to prepare for the first day of class. At the end of the day, a bootcamp is a private for-profit school at the end of the day and has an interest in your admission.
Commonly, students who don’t complete the prerequisite work is that they drop the bootcamp after two weeks for a refund once they realize the pace and breadth of the classes are more intense than they expected. In my opinion, the pace of the class is similar to drinking out of a firehose. However, classes are concise, with a focus on hands-on application. Concepts build on top of each other very quickly; however, it leaves very little room to slow down or miss any classes.
The most prevalent question prospective students would ask me is if they can genuinely be “hireable” as an analyst or data scientist after a 12-week intense class. I would say yes, but it depends on your previous background. Someone without any experience in programming, statistics, math, or machine learning is going to have a hard time with only a single data science project under their belts with nothing else related to data science on their resumes after graduation.
To find a job after completing your final class project is not an impossible task, and there are many ways I’ve seen students navigate challenging job markets, but most have successful outcomes. Students accept jobs like data scientists, data engineers, analysts, and other data science roles.
Who’s in your class?
Your classmates are quantitative finance analysts, biologists, actuaries, former high school math teachers, venture capitalists, accountants, engineers, or anyone else without ties to engineering or data. Most of these students have either qualitative degrees or applied engineering backgrounds mixed with students who have neither.
One of the hardest problems to solve as an instructor is teaching a class with students with a dynamic range of abilities with stats, math, and engineering. Even though I do think the overall average of students’ knowledge and programming ability affects the quality of instruction to a degree, it’s also an excellent opportunity to learn from more knowledgable classmates if you’re growth-minded.
Since each cohort contains a wide variety of people with different backgrounds, beliefs, and abilities, everyone comes with various challenges. Generally, students either have an easier time with the theoretical concepts presented or the programming aspect. Some students struggle with everything with a background in neither, but I tend to believe these students adopt a discipline about leaning into the unknown and consequently survive just fine.
Generally, students with quantitative backgrounds help more engineering-minded students and vice-versa. One shared experience everyone has in bootcamp-style programs is a substantial struggle with a concept or two at one point or another. The ideas students struggle with are unique and different for everyone.

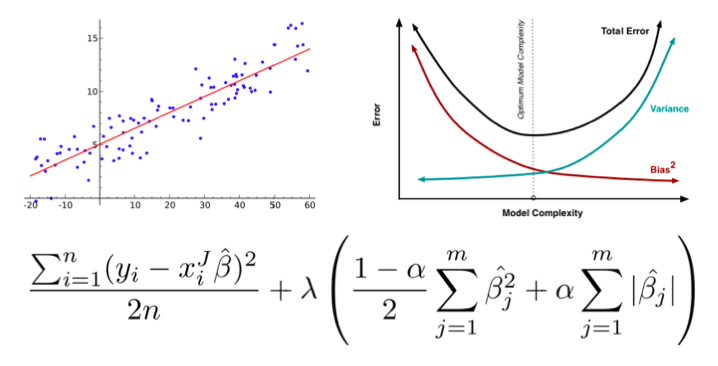
Just learned linear regression? Great, now let’s learn linear regressions many regularized forms, how colinearity may affect the quality of your models, and impact of the bias-variance tradeoff implied within this domain of modeling that you just learned. These concepts that I just mentioned are several months or years of study in a traditional setting, but students get the “gist” of everything in about a week if they pay attention in a bootcamp-style class.
What do you learn?
You receive a tour-de-force overview of the classic machine learning algorithms and a basic understanding of how to implement them. If you take a part-time class, you will learn how to:
- Import libraries
- Clean and transform data with some form of data frames
- Train and evaluate models
- Use databases (minimally)
You will also learn to work within the application of the most essential ML domains including:
- Supervised and unsupervised learning
- Regression
- Classification
- NLP Bayes
- Time series
- Neural networks
- “be aware” of “some” big data toolsets
The big differentiator with the full-time “immersive” from part-time classes are more coding ML models from scratch, more hands-on projects, more lectures, and a lot more practice overall. The full-time programs are going to be a lot better value if you look at the cost per hour but especially since you can ask the instructors for 1:1 time and possibly job-placement (outcomes) support depending on the school.
Will you learn how to do machine learning? Yes. Will you learn how to code better? Yes. Will you understand statistics enough to be useful? Very likely. Will you learn enough to continue to learn on your own and stay current? Definitely. It will also be one of the hardest but rewarding educational experiences of your life. It is but one of many paths available depending on your tolerance to stress and growth vs cost savings alternatives of attending college.

Will you know how to interview effectively? Unlikely because this area of most programs is not rigorous enough. The gap between a real-life data science salary and a post-bootcamp candidate will be much smaller at the end of 12-weeks, but the gating factor may not just be knowing enough statistics, math, or machine learning. You also have to be able to code the level of a mid-level engineer (my opinion), but that’s achievable with the right level of focus and preparation. I believe the majority of students land positions in data science after attending a data science bootcamp. Still, it’s not without a bit more effort which isn’t typically advertised before your first day of class.
My most critical assessment of these types of programs is the gap between what is taught versus what you need to do to be hirable. Bootcamps try to teach you how to use the data science process but instead focus more on instructing you on how to conduct proper ML experiments. Data science is so much more than knowing machine learning. The data science job market is still defining itself, but it’s become a lot more clear what roles exist and what the market expects at this point. Businesses are hiring candidates who are not only good at engineering, stats, and ML but also capable of interfacing with non-technical managers while relating to business needs.
What You Won’t Learn
There’s so much I want to write about how fun and exciting data science in the real world is. There are tons of cool tools available to do worthwhile model evaluations aren’t in scikit-learn or R Studio not covered in class for instance. You might think that after 12-ish weeks data science is all about modeling but in all honesty, data scientists don’t spend all day training models except perhaps if you’re in research. Modeling comprises 10–20% of most projects’ scope and the rest will be looking at data, cleaning that data, and relentlessly asking questions to define the hell out of an incredibly vague set of assumptions.
Machine learning only gets more interesting the more you learn but that’s not what will land most jobs in data science initially unless the position is exclusively research. There are significant blind spots in almost all data science bootcamp programs because data science isn’t just about modeling.
1. How to scope projects that demonstrate business impact


The biggest skill that differentiates candidates interviewing for data scientist roles is the ability to clearly define a problem where lots of ambiguity exists while explaining the end-results in a way that connects real business value. Data science is a process. It has to justify its approach and advocate for its existence in the real world at every step, which includes training models and optimizing hyperparameters but also how to examine data and ask the right questions from it.
After taking a 12 week class on data science, most students believe modeling is the most crucial step in a project. In the real world, we have to justify how the data and model work together to measurably solve a problem. Most of your time should be spent looking at data, cleaning data, and measuring the certainty of your projects’ impact, not just tinkering with machine learning models.
Granted, not everyone can fit the latest ensemble method or neural network for a classification problem and measure 80% accuracy on validation with accompanying plots that explain model performance tradeoffs. What should a business do with that information? What does a false positive mean in terms of risk if classification? Granted, it’s not easy to define data science problems in terms that are business-value focused but it’s essential you justify your work and accurately report the risks that exist given the potential for error and bias.
To scope a problem technically and at the same time connect potential business impact is not something you will learn to be effective at within 12 weeks. It’s possible to go 12 weeks without so much of a mention of defining non-technical value through communication.
By far, scoping a problem from nothing is the toughest skill to learn for new data scientists. Bootcamps do not do a great job of training for this. Still, you can do yourself a favor and choose final projects that focus on clearly defining project scope with accompanying success metrics that also have a business outcome in mind. Tell a story with data and why it matters.
Businesses are hungry for data scientists that can think deeply and thoroughly about a problem. Businesses want someone that can explain what success is, justify model selection, and assert hard facts to a non-technical audience while defending their work as good and bad data impact it. The only way to get good at this is to ask the right questions, listen to key stakeholders, and ask for help from mentors and more experienced team members.
Gaining experience might sound like a catch-22 for instance “how do I get experience scoping problems?”. My advice is to do more projects that clearly define a problem, set key metrics, measure impact, concluding with what’s likely and recommended next actions. Ask for help. Seek the wisdom of those more experienced.
Recommended reading
- Data Science Life Cycle 101 for Dummies like Me, by Sangeet Moy Das.
The first point Sangeet makes is an excellent start in understanding how to start scoping problems. His recommendations for “1. Business Understanding” has some great jumping-off points. Also the section with the same name, “8. Business Understanding” and everything that comes before it is an excellent lead-in to the importance of the bigger picture concerning members of a data science team. - The Data Science Process: What a data scientist does day-to-day, by Raj Bandyopadhyay.
This, 1000%. This is such a great article about how to apply the data science process in a very relatable way. My favorite passage:
The VP of Sales is passing by, notices your excitement and asks, “So, do you have something for me?” And you burst out, “Yes, the predictive model I created with logistic regression has a TPR of 95% and an FPR of 0.5%!”She looks at you as if you’ve sprouted a couple of extra heads and are talking to her in Martian.
- 5 Steps on How to Approach a New Data Science Problem
by Matt Warcholinkski.
Matt says, “The problem should be clear, concise, and measurable. Many companies are too vague when defining data problems..”. I absolutely loved reading this article and couldn’t agree more with Matt’s point of view on this topic.
2. Knowing enough SQL to pass job interviews

SQL is the standard exchange of modern business. To be able to work with a team that interacts with data at any level, sooner or later you will be putting data in a database or taking it out. While not everyone adopts a relational database for every aspect of their app or business, you will most likely be writing an SQL query that exceeds 2–3 whole pages in an editor. Most bootcamps have minimal breadth when it comes to covering enough SQL to confidently get past the first interview screen.
As far as SQL skills go, you will want to be comfortable with the following topics:
- Aggregation and grouping
- “Having” qualifiers
- Basic date-time functions
- Partitioning
- Window functions
- Subqueries
- Deriving SQL joins given an ERD or even a simple text-based schema definition
Some great SQL resources to self-study:
- SQL Course 2 — Great resource but more advanced-beginner or mid-level.
- Dataflair SQL Tutorials — This is a fantastic resource with straight forward examples. Individually, check out Stored Procedures, Index, Normalization and Normal Forms, Constraints in addition to the other topics I’ve mentioned above. These are concepts that are important to understand with relational database systems as you work with real-world problems.
- Essential SQL — Kris Wenzel put together a vast collection of videos and SQL resources.
3. Working with “big data”


In the real world, data is dirty, it’s in the wrong format you need, and there is lots of it. I mean lots! So much data that won’t fit on your laptop. Big data is as much about the tools as it is about the infrastructure and operations of services supporting it. Knowing how to at least work within Google Cloud or AWS ecosystem will be a bare minimum expectation for most tech companies, but also any company that has a real-world application that depends on data backed by modern infrastructure.
The expectation of new hires to at least be able to use some form of big data system to sample their own data for experiments is common enough. What’s typical these days are modern data warehouse systems like Redshift on AWS, and Bigquery on Google, or one of the many available tools from Apache such as Hadoop, Spark, or Hive. Many big data systems have a warehouse component as part of their data management lifecycle and it’s important to know how they are related.
Over the last two years alone 90 percent of the data in the world was generated. — Bernard Marr, Forbes 2018
There’s a lot of variability in the big data ecosystem these days. Still, almost all bootcamps hardly touch on this topic in a way that would make one confident enough to work independently on big data problems end-to-end. Good data science ideas frequently end with scalable solutions and that usually entails lots of ETL and cleaning of data beforehand.
To be fair, there are a lot of hurdles to setting up big data curriculum but there are even fewer instructors that have a background working with any big data. Maybe this isn’t true for all bootcamp instructors or curriculum developers, but from my assessment of the top 3–4 data science bootcamps, depth of big data content lacks as does the talent to teach it.
Working in education, the pay is much less than working in the industry. Top paid professionals in data science that specialize in big data are scarce. This reason could explain why it’s so hard to hire in education for this specialty.
What you can learn about big data online
This area is not difficult to learn at least for the main concepts, however, learning the lower level details takes time. Most of what you need to learn should reinforce the fact that large-scale infrastructure and programming frameworks are how industry enables scalable data applications.
The first link below is an excellent resource for a general look at the world of big data. Spark is an industry-standard framework worth learning if you know Python or Scala. Dask is an emerging technology that provides distributed dataframes that are very complimentary to Pandas if you’re familiar with Python (the author of Pandas is an advisor to Dask).
- Introduction to Big Data, by Coursera, has a decent set of offerings to get a great overview of the most essential concepts and tools at a deeper level.
- Awesome Spark, “A curated list of awesome Apache Spark packages and resources.”
- Dask Documentation, a nice collection of Dask tutorials.
Big data is more than I can adequately convey how to learn but I feel these are good starting points. I may write a more detailed follow-up regarding how to get started with big data.
4. General engineering and software development lifecycle management


At the risk of sounding like a cranky old man, I find there to be a real aversion in some academic circles to the reality of the practice of data science as a function of engineering or at least a branch of it. Some of the best engineers are the best data scientists. Models and plotting frameworks we use in R and Python are software. Deploying models into a production system that enables the prediction of data in consumable applications is software.
The practice of software development includes collaborative change control, design patterns, asymptotic analysis, unit tests, deployment, workflows, design. Being able to configure and manage your development environment then effectively sling code with version control within a team should be second nature. Knowing what the common branch strategies with version control that most companies adopt are and at least how and why they are used is not even touched in most programs.
- 4 branching workflows for git by Patrick Porto
This article does a great job of explaining common branching strategies development teams of all kinds adopt.
Another essential aspect that should be considered in terms of model selection and any data management pipeline is the time and space efficiency implied with data and processing it. It’s all too easy to import sklearn libraries and forget there are tradeoffs with models in terms of efficiency that could spell the difference between what’s possible and what’s not at a larger scale than your laptop. For instance, K-Nearest Neighbors classifier, which seems simple enough in theory, actually has a lot of complex optimizations when it comes to searching for points to measure distances. In class, you learn the brute-force method of neighbor searches which is O[DN²] (D = dimension) but not understand why it may be possible to set hyperparameters that allow alternatives search methods that are more like O[DNlog(N)] but also know why they are better as the size of your dimensions and data increase. You will not learn why O(N) < O(log(N)) < O(N²) and yes it matters if you want to evaluate the tradeoffs and capabilities of your models and pipelines.
The O mentioned above refers to Big-O notation. A great short introduction to this topic on Youtube, from William Fiset:
While it takes months to become proficient at programming efficiency in practice, you can still take a few classes on this topic or study on your own if you’re disciplined enough. One of my favorite series on programming efficiency is from MIT professor Eric Grimson. Eric’s lectures on this topic are engaging and easy to watch.
I recommend these lectures specifically:
- #10. Understanding Programming Efficiency, Part 1
- #11. Understanding Programming Efficiency, Part 2
- #12. Searching and Sorting
5. ETL and workflow automation toolsets


In the real world, modeling is usually a brief but essential piece of the puzzle. Surprisingly, most of the time spent on projects isn’t so much about training models. As mentioned earlier, data is dirty but it’s also not in the form you expect or as fresh as you need it to be for your projects. Somewhat related to general engineering but the process of extracting, transforming, and loading your data is where much of your time will be spent at some scale.
Designing processes that format data to a level of consistency, and in turn, can be modeled, takes time and thought. ETL could entail (but not limited to) joining database tables, merging data from different formats, aggregations, feature engineering, or simply sampling an appropriate amount of data for an experiment. Granted you could do most of these in your language of choice (Python), but given the plethora of options available off the shelf in terms of ETL frameworks and workflow management tools, designing data integration pipelines are best done with purpose-built libraries and services.
Some popular toolsets you could become familiar with that are used in industry include:
To get a better idea of what ETL tools exist, check out this handy repo on Github: Awesome ETL.
What can you do to bridge the knowledge gap
Fortunately, we live in a time where there are lots of great resources to learn anything. A lot of schools are aware of their shortcomings as well and offer additional classes such as advanced SQL and even data engineering workshops so take advantage of those offerings before and after if you find yourself in one of the many data science bootcamp offerings. Youtube is also fantastic for learning how to set up anything big data. Meetups offer opportunities to learn directly from luminaries in the industry if you live in any metropolitan area in the world. Offer to work on an open-source project by helping with documentation and use the opportunity to ask for help from more experienced contributors. There are more ways to learn than at any other time in the past. Don’t wait.
To this day, I find the more I learn about working with data, the more I feel like it was the right decision to pursue this career path because of the constant learning involved across domains. Anyone having the right mindset can achieve employment in data science. If your goal is to become employable as a data scientist or a related role, don’t wait for opportunities to come to you. Be proactive. Don’t be afraid to fail or show your limitations. Learning is a result of “almost” and “not quite” as you approach new knowledge from new opportunities. Be humble. Ask for help. Help others. Don’t wait.
You're following Towards Data Science.
You’ll see more from Towards Data Science across Medium and in your inbox.
WRITTEN BY




No comments:
Post a Comment