

I learnt pandas mainly through Ted Petrou’s Cookbook. And now, Ted has come up with another interesting project: Building our own pandas like library. It contains a series of steps that one needs to complete in order to build a fully-functioning library similar to pandas, called pandas_cub. The library will have the most useful features of pandas.
Things I love about the project
- Size of the project: The project offers an amazing opportunity for people familiar with Python to code something big.
- Setting up environments: The project helps you learn how to create a separate environment for your project. This is done using
condapackage manager. - Test driven development: You also learn test driven development which means you first write tests and then you write code to pass them. You will learn the python library
pytestin the process.
The prerequisites and setups can be found on the project’s Github page but I’d still provide a quick walk through for the same.
Step 1: Fork the repository
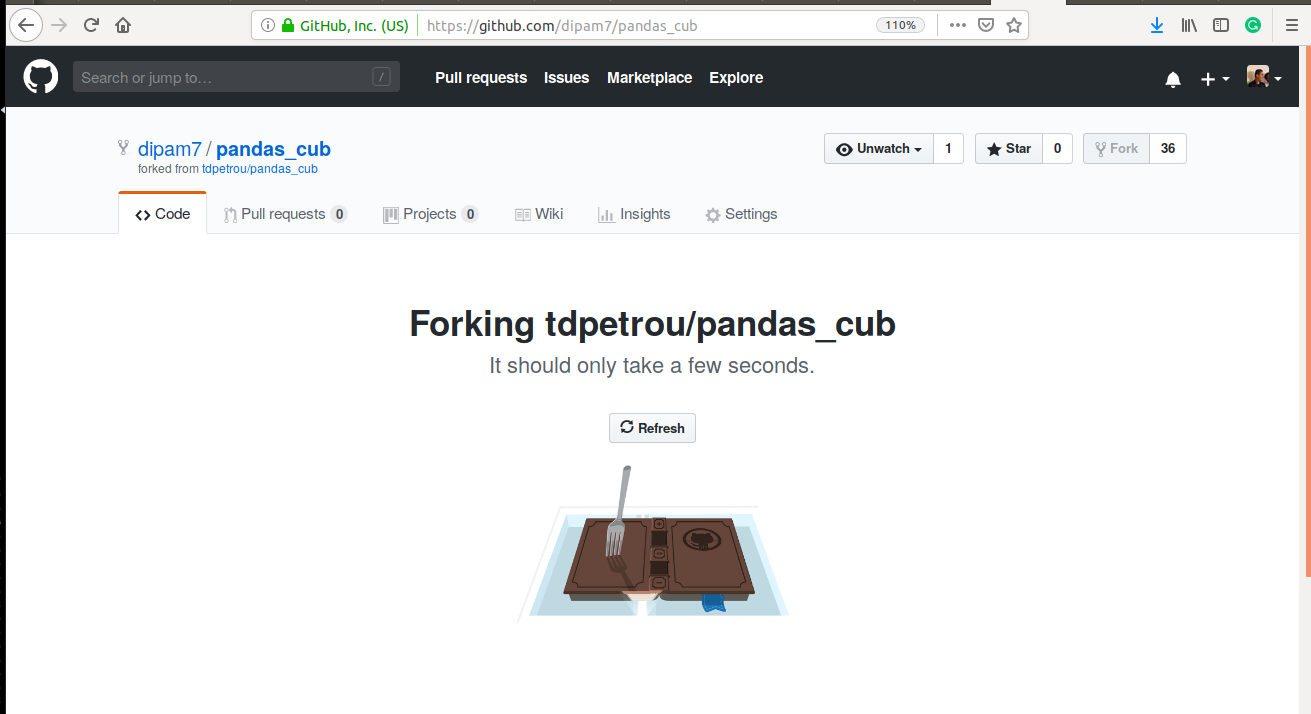



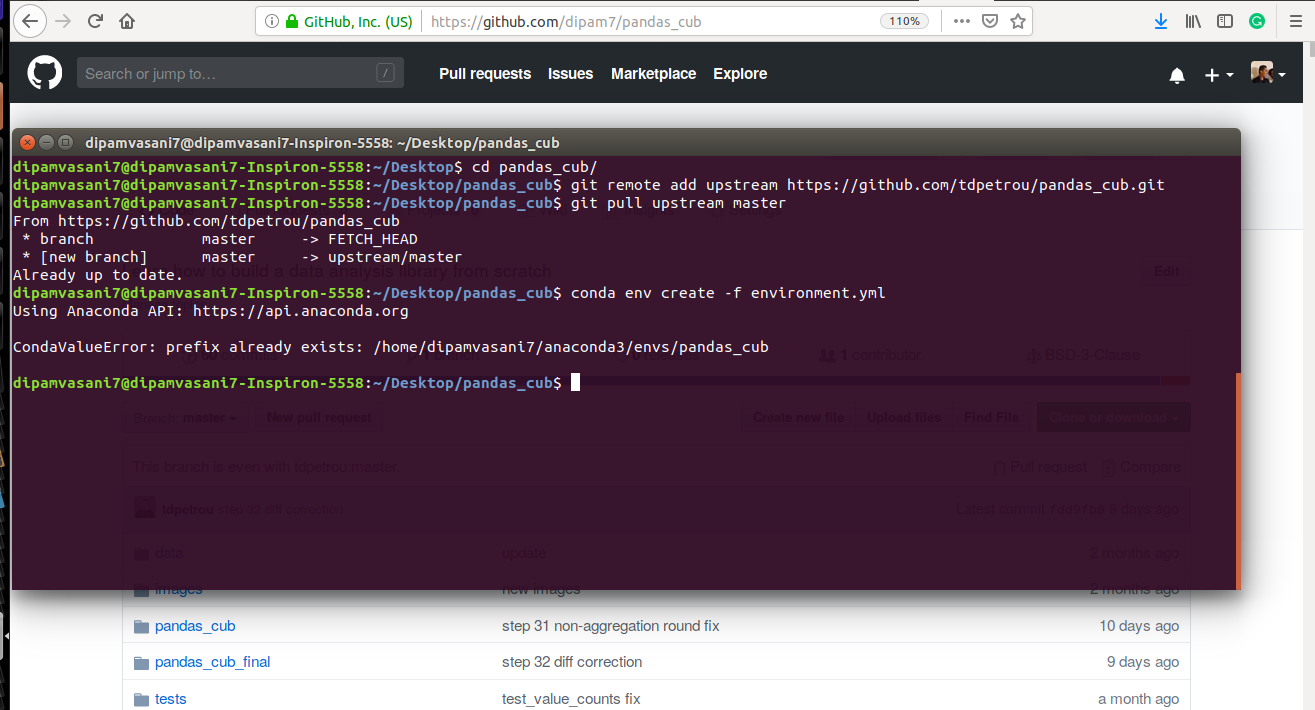
Right. Now we can fill in our code and push it to our copy of the project. However, what if the creator of the project modifies the original project. We want those modifications in our forked version as well. For this, we can add a remote called
upstream to the original repository and pull from there whenever we want to sync the two. However, this is not required for this project.

Step 3: Environment setup
This means downloading the specific set of libraries and tools required to build this project. The project has a file called
environment.yml which lists all these libraries. A simple conda env create -f environment.yml will install them for us. I have already installed them.
We can now use
conda activate pandas_cub and conda deactivate to activate and deactivate our environment.
Step 4: Checking tests
All the tests are included in a file called
test_dataframe.py located in the tests directory.
Run all the tests:
$ pytest tests/test_dataframe.py
Run a particular class of tests:
$ pytest tests/test_dataframe.py::ClassName
Run a particular function of that class:
$ pytest tests/test_dataframe.py::ClassName::FuncName
Finally, you need to make sure Jupyter is running in the right environment.
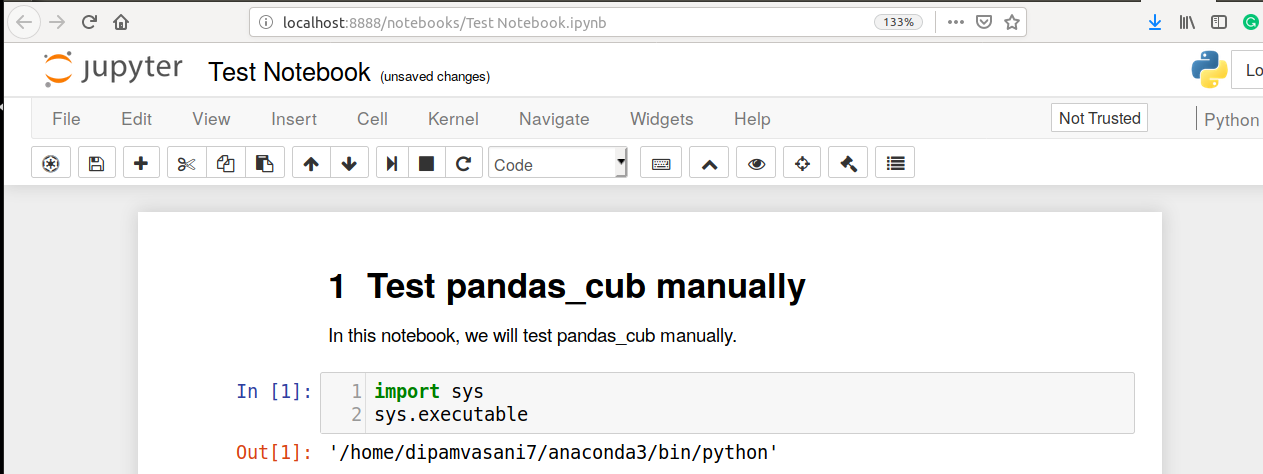
Step 5:
__init.py__
Once everything is set up, let’s start by inspecting
__init.py__ which is the file we will be editing throughout the project. The first task requires us to check if the input provided by the user is in the correct format.

Let’s start by raising a
TypeError if data is not a dictionary. We do this as follows:

To test this case we will open a new Jupyter notebook (you can also use the existing Test Notebook) and do the following:
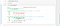

Note: Make sure you have these magic lines of code on top of your notebook. They will ensure that whenever you edit the library code, it will reflect in your notebook without having to restart.


Now let’s pass a dictionary and see if it works.


And sure it does. Once we code all the cases we can run the tests from the
test_dataframe.py to see if all of them pass. Overall, this seems like a really fun project and provides a lot to learn. Go through it and tell me if you like it. Also tell me other fun projects you’ve worked on.
~happy learning.




No comments:
Post a Comment