This small tutorial will help you understand how a trained machine learning model is used in production.
Nowadays you can find lots of tutorials, MOOCs and videos for learning Data Science and Machine Learning. But none of them explain what happens to your machine learning model after you train and optimize one at your local system in jupyter notebook or other IDE.
In a production environment, no one sits in front of the system giving input and checking the output of the model you have created.
So in this tutorial, we will create a simple RESTful web service in flask to serve our machine learning model output as an API response and later deploy the app in Google Cloud Platform’ App engine.
Setup and Requirements:
- Python 3.6
- Text editor
- Google Cloud Platform Account
- Jupyter Notebook
Also, please install below specified libraries:
Required libraries for creating RESTful API in Flask
Training a sample Machine Learning Model:
I am going to train a sample linear regression model on the Boston housing dataset both are available in the Scikit-learn library, at the end I am saving the trained model in a file using Joblib.
Below is the sample python code:
## Importing required Librariesimport pandas as pd import numpy as np ## for sample dataset from sklearn.datasets import load_boston ## for splitting data into train and test from sklearn.model_selection import train_test_split ## LinearRegression model from sklearn.linear_model import LinearRegression ## For saving trained model as a file from sklearn.externals import joblib## Getting sample dataset boston_dataset = load_boston() boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names) boston['MEDV'] = boston_dataset.target## Preparing variable X = pd.DataFrame(np.c_[boston['LSTAT'], boston['RM']], columns = ['LSTAT','RM']) Y = boston['MEDV']## splitting train and test data X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state=5) #print(X_train.shape) #print(X_test.shape) #print(Y_train.shape) #print(Y_test.shape)## Training Model lin_model = LinearRegression() lin_model.fit(X_train, Y_train)## Saving trained model joblib.dump(lin_model, 'test_model')
Creating a simple flask application:
Now we will create a simple RESTful app that will serve our model output as an API response. Our app will do the below tasks:


Below is the code for the flask app. You can also get it from GitHub, using this link.
from flask import Flask,request from flask_restful import Resource,Api from sklearn.externals import joblib import pandas as pdapp=Flask(__name__) api=Api(app)class Test_index(Resource): def post(self): loaded_model = joblib.load('./model/test_model') test_data=request.get_json() input_df=pd.DataFrame([test_data]) input_df.rename(columns={"input_lstat":'LSTAT',"input_rm":'RM'},inplace=True) print(input_df) y_train_predict = loaded_model.predict(input_df) test_output=pd.DataFrame(y_train_predict,columns={'output'}) output=test_output.to_dict(orient="list") return outputapi.add_resource(Test_index,"/test") if __name__=='__main__': app.run(debug=True)
Testing our application(local or dev environment):
After writing our application we will test it out in a local or development environment before moving it to production in Google Cloud Platform.
I am using Gunicorn, a WSGI application server for running our app.
Just open the project directory in terminal and run below command:
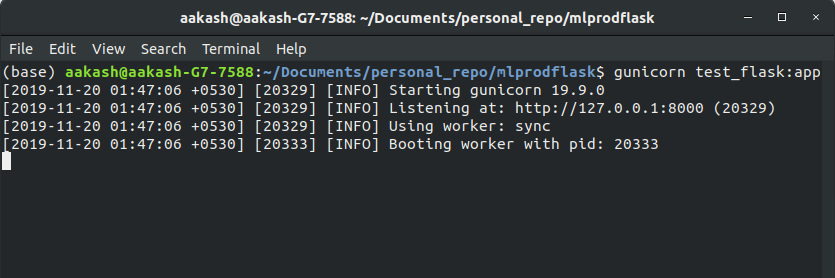
$ gunicorn test_flask:app
we will get the detail of the local port on which our application is running:
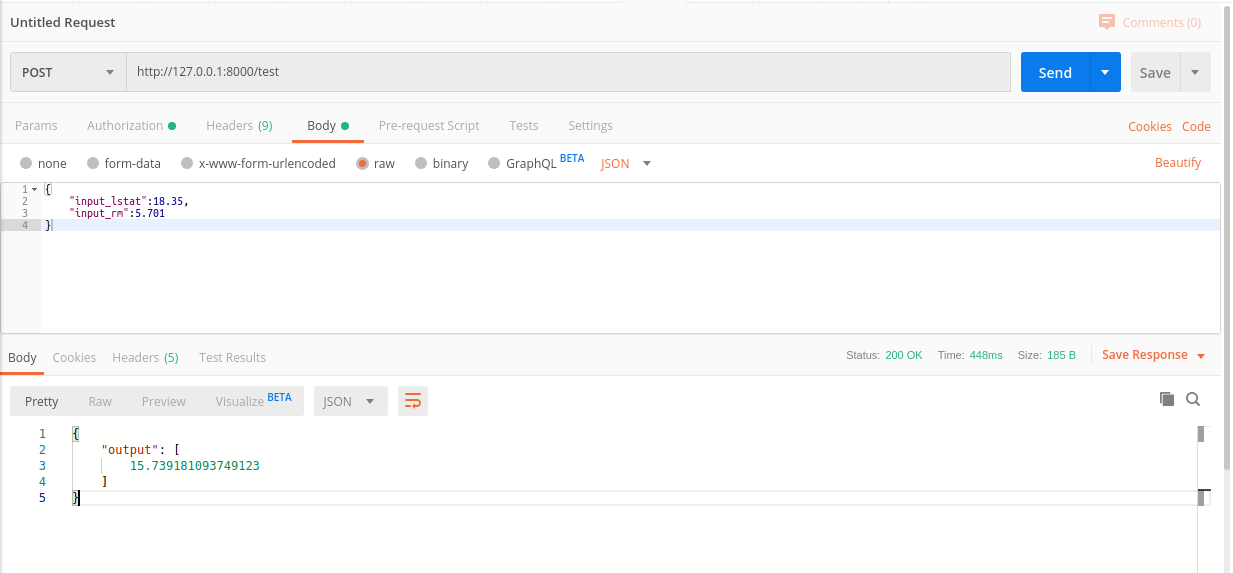
Let’s test the API response with the postman application. We are going to make a POST request to our application endpoint passing a JSON request body containing input parameter and if there is no error then we will get a response as a JSON object containing model’s prediction as a result.
Deploying App to Production In Google Cloud Platform:
The App that we have tested was deployed in the local system. To make our system accessible globally we need to deploy it in some server having a global URL for assessing our app.
For this, we are going to use the Google Cloud platform’s App Engine.
Note: Before the next steps please check you have the Google Cloud Platform account and google cloud SDK is set up in your system. You can find the details for setting up google SDK here.
Google App Engine requires a deployment descriptor file called ‘app.yaml’ for deploying our app in google cloud.
Below is the content of the deployment descriptor, app.yaml file:
Content of app.yaml file
Now create a directory structure as given below:

Finally, open the same directory folder in the terminal, and use the below command to deploy the app in Google cloud.
$ gcloud app deploy --version 1
Google Cloud SDK will check the proper permission and then read the deployment descriptor file, ‘app.yaml’ and ask for the confirmation. Type ‘Y’.

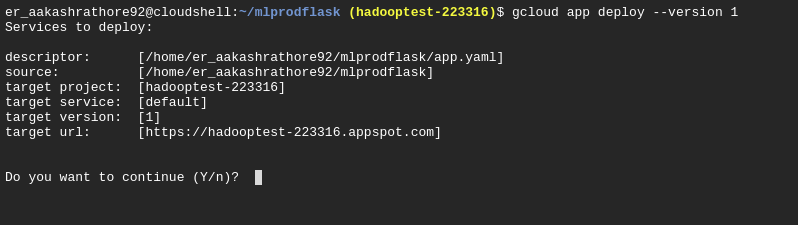
After getting confirmation Google cloud SDK will copy all the required files in APP engine instance and if there are no errors, then we will get the global endpoint of our application.

In our case, the global endpoint URL is: “https://hadooptest223316.appspot.com”
Testing our application(Production Environment):
Again let’s test our API response with the postman application. We are going to make a POST request to our global endpoint URL:

Again we got the required model’s prediction as an API response.
Conclusion:
In this article, we saw how a machine learning model is used in production. Although this is a very basic use case. But this will give you some idea of how the machine learning models are put into production in the cloud server inside different applications.
You're following Towards Data Science.
You’ll see more from Towards Data Science across Medium and in your inbox.

WRITTEN BY




1 comment:
Training Data Sets for AI and Machine learning Engines
Training Data Sets for World’s Leading AI and Machine Learning Companies.Cognegica Networks was a dream realized early in 2018 as an enterprise that amalgamated technology with rural development.
to get more - https://www.cognegicanetworks.com/
Post a Comment