Introducing Expert Data Scientists Skills Along With The Best Practices & Successful Data Science Project Steps
Data Science is a hot topic nowadays. Organizations consider data scientists to be the Crème de la crème. Everyone in the industry is talking about the potential of data science and what data scientists can bring in their BigTech and FinTech organizations. It’s attractive to be a data scientist.
This article will outline everything we need to know to become an expert in the Data Science field.


During tough times, data scientists are required even more because it’s crucial to be able to work on projects that cut costs and generate revenue. Data science projects have been possible mainly because of the advanced computing power, data availability, and cheap storage costs.
A quantitative analyst, software engineer, business analyst, tester, machine learning engineer, support, DevOps, project manager to a sales executive can all work within the data science field.
Article Aim
These are the four sections of this article:
- Data Scientists — The Magicians
- Essential Skills Of Expert Data Scientists
- Data Science Project Stages
- Data Science Common Pitfalls
- Data Science Best Practices
This article will provide an understanding of what data science is and how it works. I will also outline the skills that we need to become a successful data scientist. Furthermore, the article will outline the 10 stages of a successful data science project. The article will then mention the biggest problems we face in data science model-building projects along with the best practices that I recommend everyone to be familiar with.
I will also highlight the skills that are required to become an expert data scientist. At times, it’s difficult to write everything down but I will be attempting to provide all of the information which I recommend to the aspiring data scientists.
1. Data Scientists — The Magicians
Expert data scientists can use their advanced programming skills, their superior statistical modeling know-how, domain knowledge, and intuition to come up with project ideas that are inventive in nature, can cut costs, and generate substantial revenue for the business.
All we need to do is to find the term Data Science in Google Trends to visualise how popular the field is. The interest has grown over time and it is still growing:


Data Science projects can solve problems that were once considered impossible to solve.
Data science-focused solutions have pushed technology to a higher level. We are seeing solutions that are attempting to model volatility, prices, and entities’ behavior. Many companies have implemented fantastic data science applications that are not limited to the FinTech or BigTech only.
In my view, the umbrella of data science requires individuals with a diverse set of skills; from development, analysis to DevOps skills.
2. Essential Skills Of Expert Data Scientists
It’s necessary to have the right foundation to be a successful expert data scientist.
First thing first, the subject of data science is a branch of computer science and statistics. Hence it involves one to acquire computer science and statistical knowledge. There are no two ways about it. Although the more knowledge the better but we can’t learn everything all at once. Some of the areas are more important than the others. This article will only focus on the must-know skills.

In this section, I will aim to outline the required skills. In my view, there are only 4 main skills.
1. Domain Knowledge
Before we can invent a solution, we need to understand the problem. Understanding the problem requires knowing the domain really well.
The must-know skills of this section are:
- Understanding the current problems and solutions within the domain to highlight the inefficiencies
- Solid understanding of how users work
- How revenue is generated and where the cost can be saved
- An understanding of who the decision-makers are and what the pain-points are
The users of the domain are the best teachers of that domain. It takes years to become an expert in a domain. And in my view, the best way to understand the domain is to code a data science application for the users that solves the most painful problem within the domain.
2. Story Telling
I can’t emphasise enough that the most important skill for a data scientist is the ability to tell and then sell a story. The must-know skills within story-telling are:
- Being imaginative
- Open to experiment
- Confidently articulating ideas clearly and concisely to the point
- Having the power of persuasion
- Being confident to seek guidance from the domain experts
- Presenting the data and methodology
Most importantly, the key ingredient is genuinely believing in your idea.
Therefore, the most important skill is essentially a soft-skill. And believe me, given the right training, all of us can master it.
The story should concisely and clearly explain the problem that the proposed data science solution is intending to solve. The decision-makers should be able to determine that the problem does exist and the proposed solution can help them cut costs and generate further revenue.
Without storytelling, it’s nearly impossible to get projects funded by the business, and without projects, data scientists’ skills can end up rotting.
The usual questions that the stakeholders enquire about are around the timelines which are heavily dependent on the required data. Therefore, it’s crucial to help them understand what those required data sets are and where to fetch them.
During the project lifecycle, the solution is usually presented to several users. Hence one should be able to confidently present his/her ideas.
Therefore, the key skill is the ability to tell a story of your data science project and pitch it with the right detail to the target audience.
3. Technical Skills:
We need to be able to prepare a prototype at a minimum and later productionise it into a production-quality software.
The must-know technical skills are the ability to:
- Create classes, functions, call external APIs, and a thorough understanding of the data structures.
- Expertise in loading and saving data from various sources via programming (SQL + Python)
- Ability to write functions to transform data into the appropriate format
It’s obvious that an understanding of designing scalable technological solutions using micro-services architecture, with the knowledge of continuous integration and deployment is important but I am intentionally avoiding the mention of these skills for now and I am only concentrating on the must-know skills. Again, the more knowledge the better but here, let’s concentrate on the must-know only.
Although we can use R programming language and I have written articles on R but I recommend and prefer to use the Python programming language. Python has started to become the De-facto of choice for Data Scientists. Plus, there is huge community support. I have yet to find a question on Python that has not been answered already.
Google trends shows that the popularity of Python is ever increasing:


Therefore the first key skill within the technology section is to have a solid grip on the Python programming language.
I highly recommend reading this article:
It’s a known fact that data scientists spend a large amount of their time designing solutions to gather data. Most of the data is either text-based or numerical in nature. Plus the datasets are usually unstructured. There is an unlimited number of Python packages available and it’s near-to-impossible to learn about all of them. There are 3 packages that I always recommend everyone: Pandas, Numpy and Sci-kit Learn.
Numpy is a widely used package within the data science ecosystem. It is extremely efficient and fast at number crunching. Numpy allows us to deal with arrays and matrices.
It’s important to understand how to:
- Create collections such as arrays and matrices.
- How to transpose matrices
- Perform statistical calculations along with saving the results.
I highly recommend this article. It is sufficient to understand Numpy:
Finally, as most of our time is spent on playing with data, we rely heavily on databases and Excel spreadsheets to reveal the hidden secrets and trends within the data sets.
To find those patterns, I recommend the readers to learn the Pandas library. Within Pandas features, it’s essential to understand:
- What a dataframe is
- How to load data into a dataframe
- How to query a data frame
- How to join and filter dataframes
- Manipulate dates, fill the missing values along with performing statistical calculations.
I recommend this article that explains just that:
As long as we can manipulate and transform data into the appropriate structures, we can use Python to call any machine learning library. I recommend everyone to read on the interfaces to the Scikit-learn library.
4. Statistics And Probability Skills
Calling the machine learning models is technical in nature but explaining and enhancing the models requires the knowledge of probability and statistics.
Let’s not see machine learning models as black-boxes as we’ll have to explain the workings to the stakeholders, team-members and improve on the accuracy in the future.
The must-know skills within the statistics and probability section are:
- Probability distributions
- Sampling techniques
- Simulation techniques
- Calculation of the moments
- Thorough understanding of accuracy measures and loss functions
- Regression and Bayesian models understanding
- Time series knowledge
Once we have the data, it’s important to understand the underlying characteristics of the data. Therefore, I recommend everyone to understand statistics and probability. In particular, the key is to get a good grip on the various probability distributions, what they are, how sampling works, how we can generate/simulate data sets, and perform hypothesis analysis.
Unless we understand the area of statistics, the machine learning models can appear to be a black-box. If we acknowledge how statistics and probability work then we can understand the models and explain them confidently.
There are two must-read articles that I recommend everyone to read to get a solid grip on Statistics and Probability.
The first article will explain the key concepts of Probability:
The second article provides an overview of the Statistical inference techniques:
Although the knowledge of neural networks, activation functions, couplas, Monte-Carlo simulations, and Ito calculus is important, I want to concentrate on the must-know statistical and probability skills.
As we start working on more projects, we can look into advanced/expert level architecture and programming skills, understand how deep learning models work and how to deploy and monitor data science applications but it’s necessary to get the foundations right.
3. Data Science Project Stages
Let’s start by understanding what a successful data science project entails.
We can slice and dice a data science project in a million ways but in a nutshell, there are 10 key stages.
I will explain each of the stage below.

1. Understanding The Problem
This is the first stage of a data science project. It requires acquiring an understanding of the target business domain.
It involves data scientists to communicate with business owners, analysts, and team members. The current processes in the domain are first understood to discover whether there are any inefficiencies and whether the solutions already exist within the domain. The key is to present the problem and the solution to the users earlier on.
2. Articulating The Solutions
The chosen solution(s) are then presented clearly to the decision-makers. The inputs, outputs, interactions, and cost of the project is decided.
This skill at times takes a long time to master because it requires sales and analysis skills. One needs to understand the domain extremely well and sell the idea to the decision-makers.
The key is to evaluate the conceptual soundness, write down, and agree on all of the assumptions and benchmark results. Always choose a benchmark process. It could be the current process and the aim is to produce a solution that is superior to the current benchmark process. Benchmark processes are usually known and understood by the users. Always keep a record of how the benchmark solution works as it will help in comparing the new solutions.
It’s important to mention the assumptions, note them down, and get users validation as the output of the application will depend on these assumptions.
3. Data Exploration
Now that the problem statement is determined, this step requires exploring the data that is required in the project. It involves finding the source of the data along with the required quantity, such as the number of records or timeline for the historic data and where we can source it from.
Consequently, it requires business and quantitative analytical skills.
4. Data Gathering
This stage is all about interfacing with the data teams and sourcing the required data. It requires building tools using advanced programming techniques to gather the data and saving the data into a repository such as files or databases. The data can be extracted via web service calls, databases, files, etc.
This requires technical skills to call the APIs and saving them in the appropriate data structures. I also recommend everyone to get a solid understanding of the SELECT SQL statements.
5. Data Transformation
This stage requires going over each feature and understanding how we need to fill the missing values, which cleaning steps we need to perform, whether we need to manipulate the dates, if we need to standarise or normalise the data, and/or create new features from the existing features.
This stage requires understanding data statistical probability distributions.

6. Model Selection and Evaluation
This stage requires feeding the data to the statistical machine learning models so that they can interpret the data, train themselves, and output the results. Then we need to tune the parameters of the selected models to obtain the highest accuracy. This stage requires an understanding of statistical models and accuracy measures. There are a large number of models available, each with their benefits and drawbacks.
Most of the machine learning models have been implemented in Python and they are publicly available
The key is to be able to know which model to call, with what parameters, and how to measure its accuracy.
It’s crucial to split the input data into three parts:
- Train — which is used to train the model
- Test — that is used to test the accuracy of the trained model
- Validation — used to enhance the model accuracy once the model hyper-parameters are fine-tuned
I highly recommend this article. It explains the end-to-end machine learning process in an intuitive manner:
It is also advisable to choose a simple model first which can give you your expected results. This model is known as the benchmark model. Regression models are traditionally good benchmark models.
The regression models are simple and can reveal errors in your data sets at earlier stages. Remember overfitting is a problem and the more complex the models, the harder it is to explain the outcomes to the users. Therefore, always look into simpler models first and then apply regularisation to prevent over-fitting. We should also utilise boosting and bagging techniques as they can overweight observations based on their frequency and improve model predictivity ability. Once we have exhausted the simple models, only then we should look into advanced models, such as the deep learning models.
To understand how neural networks work, read this article:
7. Testing Application
This stage requires testing the current code to ensure it works as expected to eliminate any model risk. We have to have a good understanding of testing and DevOps skills to be able to implement continuous integration build plans that can run with every check-in.
The build plans should perform a check-out of the code, run all of the tests, prepare a code coverage report, and produce the required artifacts. Our tests should involve feeding the application the unexpected data too. We should stress and performance test the application and ensure all of the integration points work. The key is to build unit, integration, and smoke tests in your solution. I also recommend building a behavior-driven testing framework which ensures that the application is built as per the user requirements. I have used behave Python package and I recommend it to everyone.
8. Deployment And Monitoring Application
This stage involves deploying the code to an environment where the users can test and use the application. The process needs to run without any human intervention. This involves DevOps skills to implement continuous deployment. It should take the artifacts and deploy the solution. The process should run a smoke test and notify the users that the application is deployed successfully so that everything is automated.
We are often required to use microservices architecture within containers to deploy the solution horizontally across servers.
Once the solution is up, we need to monitor it to ensure it’s up and running without any issues. We should log all of the errors and implement heart-beat endpoints that we can call to ensure that the application is running successfully.
Data science projects are not one-off projects. They require continuous monitoring of the acquired data sets, problems, and solutions to ensure that the current system works as desired.
I highly recommend this article that aims to explain the Microservices architecture from the basics:
9. Application Results Presentation
We are now ready to present the results. We might want to build a web user interface or use reporting tools such as Tablaue amongst other tools to present the charts and data sets to the users.
It comes back to the domain and story-telling skills.
10. Backtesting Application
Lastly, it’s crucial to back-test the application. Once the model is live, we want to ensure that it is always working as we expect it to work. One way of validating the model is to feed it historical data and validate the results quantitatively and qualitatively.
The current project becomes the benchmark for the next phases. The next phases might involve changing data sets, models, or just fine tuning the hyper-parameters.
It’s scarce to find one person who can work on all of the stages independently but these super-stars do exist in the industry and they are the expert data scientists. It takes many years of hard work to gain all of the required skills and yes it is possible with the right projects and enough time. It is absolutely fine to be more confident in one stage than the other but the key is to have a good enough understanding of each of the stage.
4. Data Science Common Pitfalls
Whilst working on data science projects, it’s important to remember common pitfalls.
This section will provide an overview of the pitfalls.


Bad input data
Ensure your input data is of good quality otherwise, you will end up spending a lot of time in producing a solution that won’t benefit the users.
Bad parameters
A model is essentially a set of functions. The parameters of the functions are often calibrated and decided based on intuition and knowledge. It’s important to ensure that the parameters are right and the data that is passed in the parameters is good.
Wrong assumptions
It is important to get the assumptions about the data and the model along with its parameters verified. Wrong assumptions can end up wasting a lot of time and resources.
The wrong choice of models
Sometimes we choose the wrong model and feed it the right data set to solve the right problem. Expectedly, the application produces invalid results. Some models are good to solve only particular problems. Therefore, do ensure that the chosen model is appropriate for the problem you are attempting to solve.
Programming errors
Data science projects require a lot of coding at times. The errors can be introduced into the projects whilst implementing incorrect mappings, data structures, functions, and general coding bugs. The key is to build unit, integration, and smoke tests in your solution. I also recommend building a behavior-driven testing framework.
A software engineer/analyst/manager or anyone can all become an expert data scientist as long as they continously work on the data science stages
5. Data Science Best Practices
Lastly, I wanted to outline the best practices of data science projects.

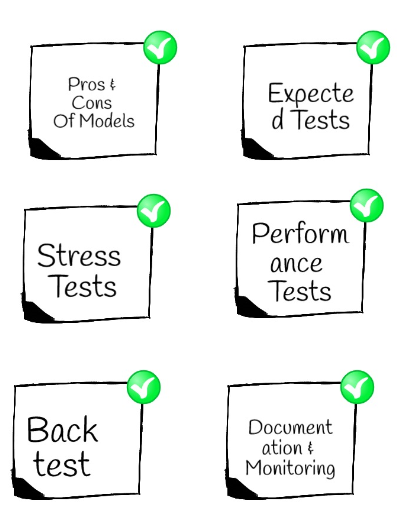
- Be aware of the pros and cons of the models. Not all models can solve all of the problems. If you have chosen smoothing techniques then ensure you understand the decay factors and whether the methodology is valid. Always choose a simple benchmark model and present the results to the end-users earlier on. Plus split the data into Train, Test, and Validation set.
- Always build a benchmark model and show the results to the domain experts. Test the project on expected inputs to ensure the results are expected. This will clarify most of the issues with the assumptions and input data sets.
- Test the project on unexpected inputs to ensure the results are not unexpected. Stress-testing the projects is extremely important.
- Performance test the application. It is essential to ensure it can handle large data sets and requests. Build CI/CD plans at the start.
- Always backtest your model on historic data. It’s important to feed in the historic data to count the number of exceptions that are encountered. As history does not repeat itself, the key is to remember that backtesting can validate the assumptions which were set when the project was implemented. Hence, always backtest the model.
- Document and evaluate the soundness of the proposed methodology and monitor the application. Ensure the business users of the domain are involved at earlier stages and throughout the various stages of the project. Constantly monitor the application to ensure that it’s responsive and working as expected.
Summary


Data science is an extremely popular subject nowadays. This article outlined the skills we need to acquire to become a successful expert data scientist. It then provided an overview of the biggest problems we face in data science model-building projects along with the best practices.
With time, we can start gathering more data such as running the code in parallel or building containers to launch the applications or simulating the data to forecast models. However, the key point here was to outline the must-know skills.
Let me know what your thoughts are.




No comments:
Post a Comment