Preface
I know a lot of people get nervous in interviews. Similarly, 8 out of 10 times in my interviews, I get ants in my pants. This meant forgetting the usual tricks I have in my pocket or missing some of the key knowledge I should have known. Recently, I did an on-site technical interview for a Business Intelligence internship role, and guess what? It was all: Pandas! Though the interview did not go as smoothly as I expected, I wanted to turn this experience into a reflection on what I think is crucial in Pandas, typically text data manipulation.
Overview
This article will be on “Working with Text Data in Pandas,” mainly functions in the “pandas.Series.str”. Most of the problem settings are similar to what I experience during the interview. As you go over the article, you will get the opportunity to review what you have learned and receive a friendly reminder if you are looking forward to a technical interview. If you are new to Pandas, I hope you can add the tricks illustrated in this article to your data science toolkit. Let’s get started and clean our way towards more structured data.


FYI:
- The article will be sorted into small problem sets and possible solutions following those problems (or what I used to tackle each problem).
- This data set is a made-up sales data of “The Fruit” company to illustrate the possible scenarios you will be challenged in interviews, jobs, or data projects.


- The data is preloaded and saved in df, and don’t forget to:
import pandas as pdWithout further ado, let’s get started!
To start off, the interviewer handed you a dataset of The Fruit’s sales division. You were asked to tackle problems in each column with your technical ability in Python. What did you find?
Sales_ID: Weird Exclamation Mark and Redundant Spaces
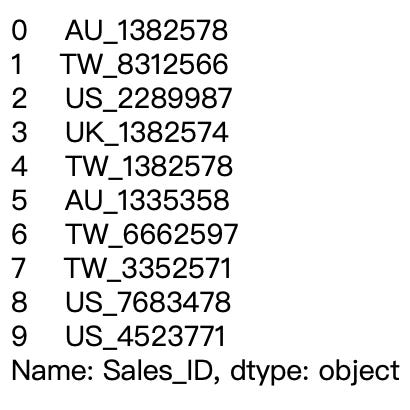
If we take a look at the first row in the Sales_ID column, you will find that it contains unnecessary spaces and an exclamation mark for the ID itself. That is a problem since we don’t need those redundant characters in the Sales_ID column.
df[ 'Sales_ID'][0]Out: 'AU_1382578 !'
What we can do is utilize the pandas.Series.str.strip method in Pandas! strip() trims off the leading and trailing characters of the column. There are also small variants like rstrip() for right strip and lstrip() for left strip.
It is very useful to use strip() when you have unessential characters and symbols on two sides of the data. Here we first right strip the “!” and then strip spaces on both sides.
df['Sales_ID'] = df['Sales_ID'].str.rstrip('!').str.strip()
Congrats on cleaning the Sales_ID column!
Sales_Branch: Missing? A little Feature Engineering
Seems like the Sales_Branch column is totally missing! The interviewer asked you to fix it with hints from the Sales_ID column. After a quick check, you find that sales are assigned to branches of The Fruit based on the first 2 words of the Sales_ID.
We can use the pandas.Series.str.slice method to slice the key elements of the string. For instance: ‘AU_1382578’ in Sales_ID → ‘AU’ in Sales_Branch.
slice() contains 3 parameters:
- start: where to start with a default of 0
- stop: where to stop (exclusive)
- step: how far a step with a default of 1
df['Sales_Branch'] = df['Sales_ID'].str.slice(stop=2)

Congrats on feature engineering the Sales_Branch column!
Product_Description: Long Descriptions containing which Products are Sold
Probably on most occasions, the company’s system produces a transaction log with long sentences. But the sentences contain valuable information that your interviewer is asking for.
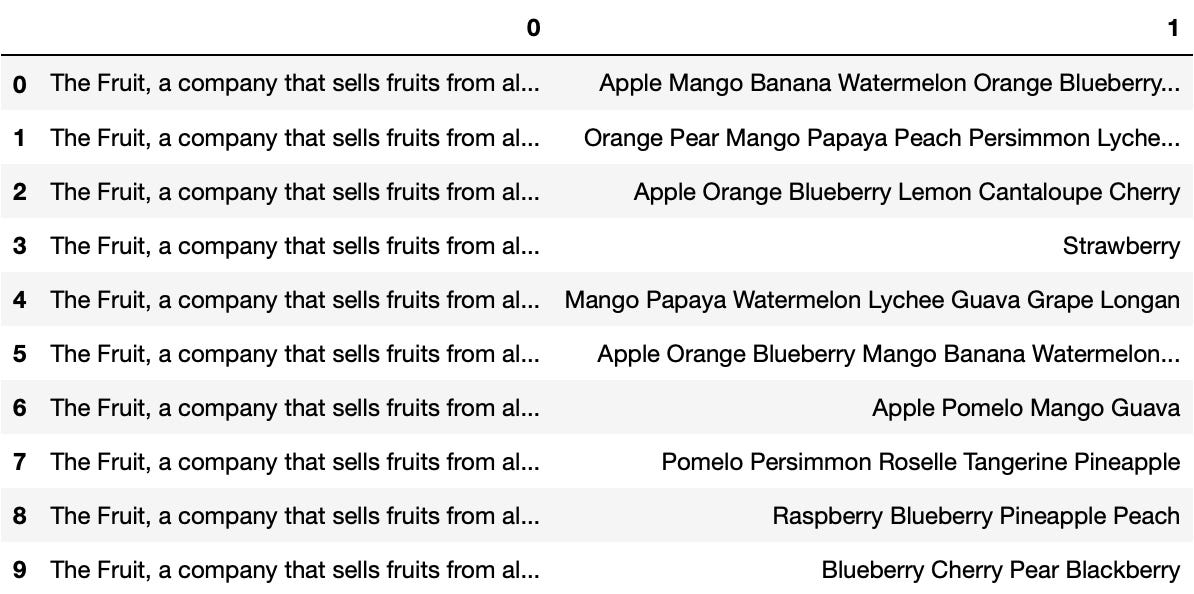
df['Product_Description'][0]Out: 'The Fruit, a company that sells fruits from all over the world, has branches in Australia, the United Kingdom, the United States, and Taiwan. Product: Apple Mango Banana Watermelon Orange Blueberry Banana Watermelon Kiwifruit'
We can see that while all of the first sentences were identical, we can split this into 2 columns: Description and Product. This is where the pandas.Series.str.split method comes into play.
split() contains 3 parameters:
- pat: what to split on with a default of white space ‘ ’
- n: the users can specify how many splits they want
- expand: when expand=True, the splits are put into individual columns
df['Product_Description'].str.split(' Product: ', expand=True)
We can assign the 0 and 1 to Description and Product in 2 ways:
df['Description'] = df['Product_Description'].str.split(' Product: ', expand=True)[0]
df['Product'] = df['Product_Description'].str.split(' Product: ', expand=True)[1]or
df[['Description', 'Product']] = df['Product_Description'].str.split(': ', expand=True)Now, the interviewer gets picky and added an additional requirement: sort the list of products in the Product column.
No need to feel anxious! This can be done by first splitting values in the Product column with split() and then apply the sorted function in Python.
df['Product'] = df['Product'].str.split().apply(sorted)

Congrats on getting information out of the Product_Description column!
Product_Count: The Number of Fruits for each Salesperson
The interviewer wanted to get a sense of the variety of fruits that their salespeople are selling. It’s good to know that you can also use the pandas.Series.str.len method to get the length of lists in the Product column.
df['Product_Count'] = df['Product'].str.len()Let’s find out who sells the most variety of fruits in The Fruit!
df[df['Product_Count'] == max(df['Product_Count'])]

It seems like the Australian representatives who sell 10 different fruits is the winner!
Congrats on counting the variety of fruits in the Product_Count column!
Product: More than just lists of Products
So after getting Product out of Product_Description, there is another challenge in your way! The interviewer asked if you could split up the Product column in 2 manners:
- Split the column into Product_1, Product_2, …
- Do one-hot encoding on each product
1. Split this column into Product_n
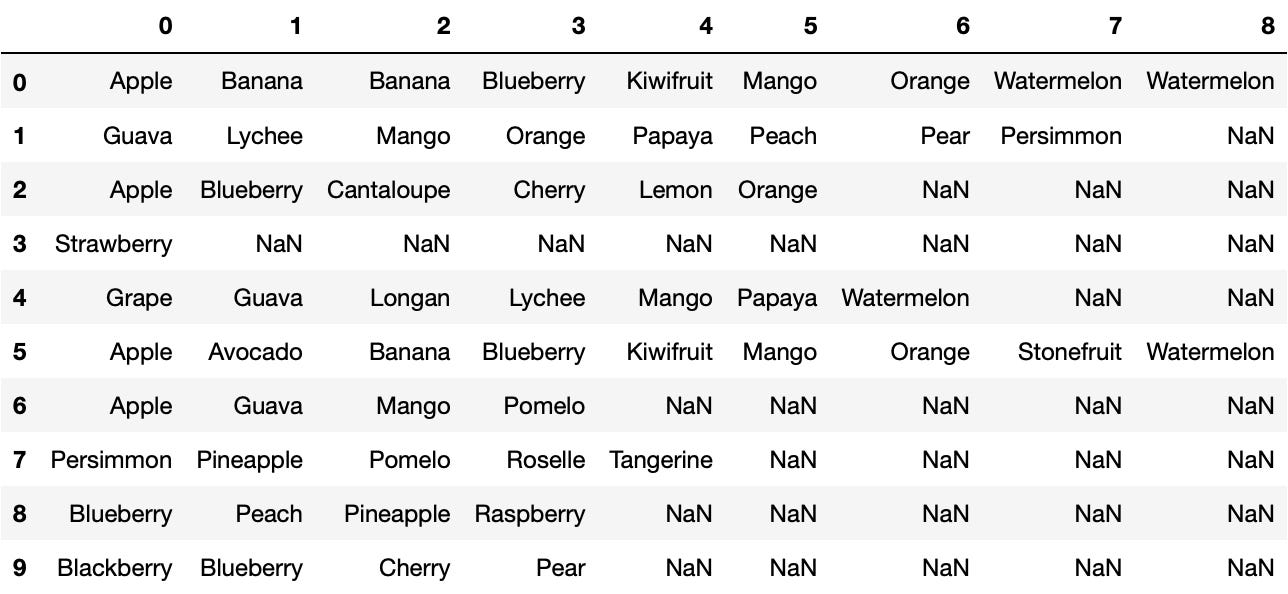
We can easily cope with this challenge by utilizing pd.Series, which we can turn a list of products into pandas.core.frame.DataFrame.
Products = df['Product'].apply(pd.Series)
Products
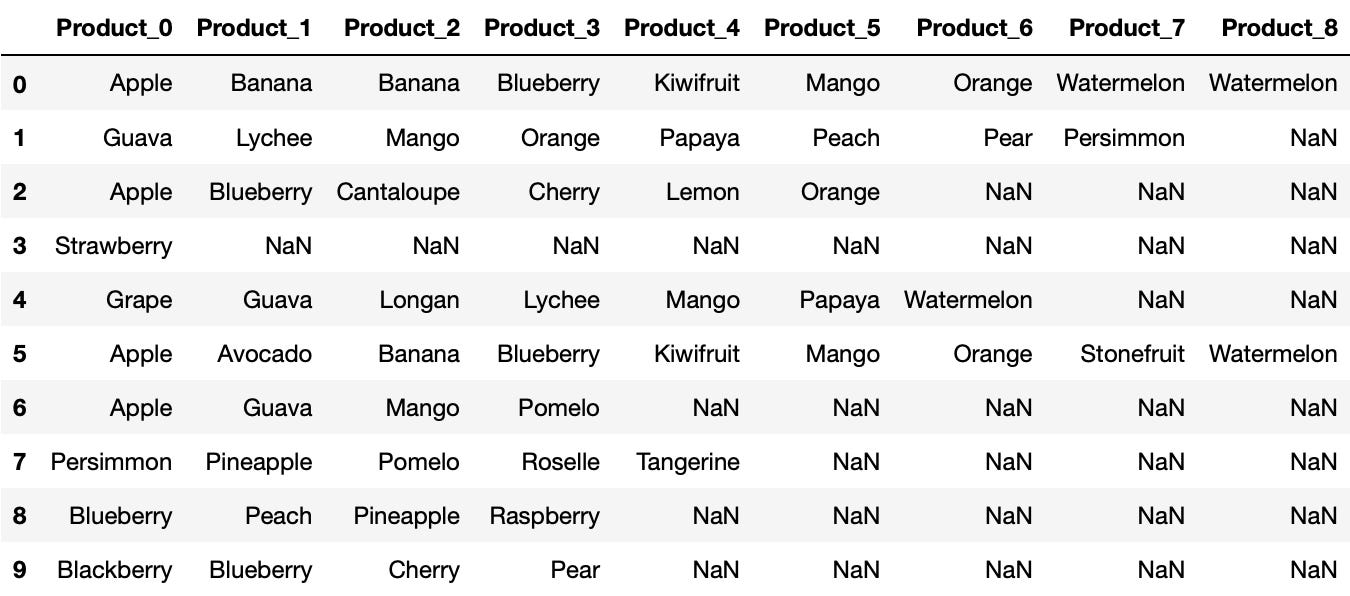
Then we finish our work by renaming the column names!
Products = Products.rename(columns=lambda x: 'Product_'+str(x))
Products
2. Do one-hot encoding on each product
One-hot encoding in Pandas is called pandas.Series.str.get_dummies, which is used to give each product a column of its own.
get_dummies() has only 1 parameter:
- sep: what to split on with a default of ‘|’
We are using the original form from the split because we can use whitespace to separate them. (Fill free to try using the list form with a loop!)
df['Product_Description'].str.split(': ', expand=True)[1]

By applying get_dummies(), we get the 10 rows × 27 columns of each fruit from the operation (that is huge!).
Products2 = df['Product_Description'].str.split(': ', expand=True)[1].str.get_dummies(' ')
Products2
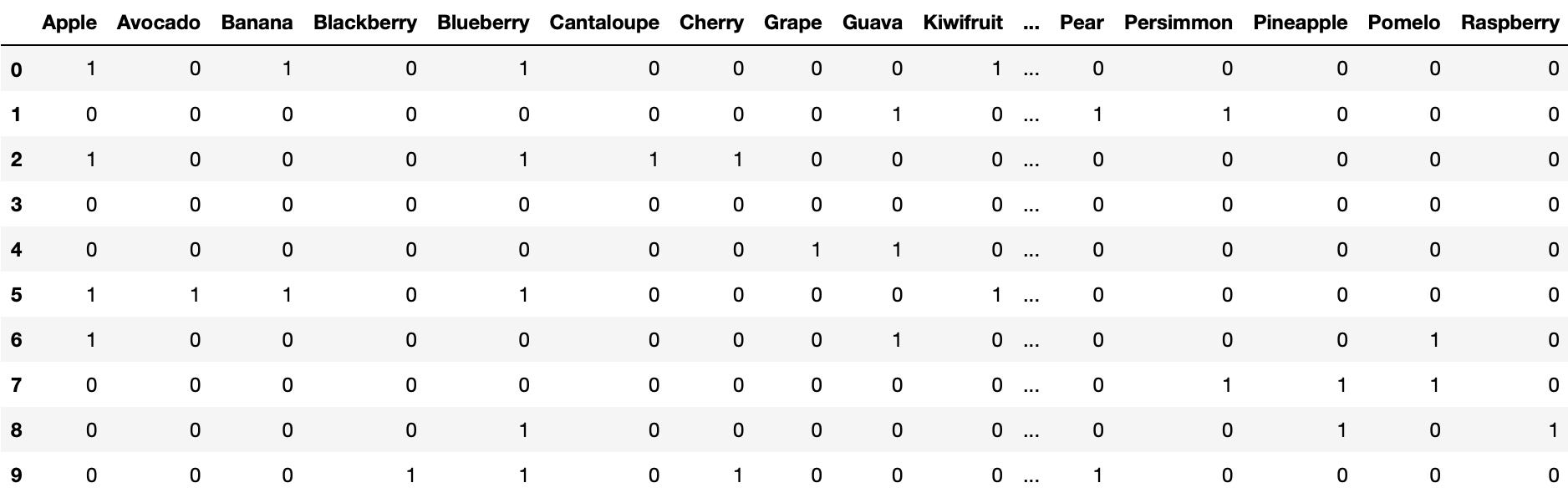
After acing the 2 requirements, the interviewer finally decided to pick option 1 as the final version. We can merge Products (option 1) with the original data frame df, resulting in a shape of 10 rows × 17 columns.
df = pd.concat([df, Products], axis=1)FYI:
The scikit-learn library also provides a “MultiLabelBinarizer” with the same function, but that is another story.
Congrats on separating each fruit from the Product column!
Recent_Sales_Date: Just Year-Month-Day
We are almost done with our interview, one last task is on data time duties. The interviewer asks you to turn the Recent_Sales_Date column into a “year-month-day” format. That is to further prevent future operations in selecting dates with different output times.
First, we cut out the dates we want, which can be accomplished in 2 ways:
Dates = df['Recent_Sales_Date'].str[:10]or
Dates = df['Recent_Sales_Date'].str.slice(stop=10)Second, simply wrap it inside pd.to_datetime().
df['Recent_Sales_Date'] = pd.to_datetime(Dates)

Congrats on reformatting date time in the Recent_Sales_Date column!
Epilogue
The interview process is officially over! Congrats! I hope that this article provides you with the experience that I had with my 1st technical interview. Though I did not do that well on this one, this won’t be the last one as well! Now, we are more confident in text data manipulation in Pandas. Thank you all for joining in the ride!
For a short review, the strip(), slice(), split() methods are all useful tools when dealing with text data: You could choose to strip off irrelevant parts on two sides, slice the essential parts that could be used, and divide the data according to a splitting criterion.
Here is the Github repo for all the codes in the article!
I love to learn about data and reflect on (write about) what I’ve learned in practical applications. You can contact me via LinkedIn and Twitter if you have more to discuss. Also, feel free to follow me on Medium for more data science articles to come!
Come play along in the data science playground!




No comments:
Post a Comment