If you’ve been studying data science, it’s likely you know how to perform machine learning tasks in languages like Python, R, and Julia. But what can you do when speed is the key, the hardware is limited, or the company you work for treats SQL as the only option for predictive analytics? In-database machine learning is the answer.
We’ll use Oracle Cloud for this article. It’s free, so please register and create an instance of the OLTP database (Version 19c, has 0.2TB of storage). Once done, download the cloud wallet and establish a connection through SQL Developer — or any other tool.
This will take you 10 minutes at least but is a fairly straightforward thing to do, so I won’t waste time on it.
We’ll use Oracle Machine Learning (OML) to train a classification model on the well-known Iris dataset. I’ve chosen it because it doesn’t require any preparation — we only need to create the table and insert the data.
Let’s do that next.
Data preparation
As mentioned, we need to create a table for holding the Iris dataset, and then we need to load data to it. OML requires one column to be used as row ID (sequence), so let’s keep that in mind:
CREATE SEQUENCE seq_iris;
CREATE TABLE iris_data(
iris_id NUMBER DEFAULT seq_iris.NEXTVAL,
sepal_length NUMBER,
sepal_width NUMBER,
petal_length NUMBER,
petal_width NUMBER,
species VARCHAR2(16)
);Awesome! Now we can download the data and load it:


When a modal window pops-up simply provide a path to the downloaded CSV and click Next a couple of times. SQL Developer should get things right without your assistance.
Once done, we have our dataset loaded and prepared:

Let’s continue with the fun part now.
Model training
Now we can get our hands dirty with the fun stuff, and that’s training the classification model. This is broken down into multiple steps, such as train/test split, model training, and model evaluation. Let’s start with the simplest one.
Train/test split
Oracle likes this step done with two views — one for training data and one for testing data. We can easily create those with a bit of PL/SQL magic:
BEGIN
EXECUTE IMMEDIATE
‘CREATE OR REPLACE VIEW
iris_train_data AS
SELECT * FROM iris_data
SAMPLE (75) SEED (42)’;
EXECUTE IMMEDIATE
‘CREATE OR REPLACE VIEW
iris_test_data AS
SELECT * FROM iris_data
MINUS
SELECT * FROM iris_train_data’;
END;
/This script does two things:
- Creates a train view — has 75% of data (
SAMPLE (75)) split at the random seed 42 (SEED (42)) - Creates a test view — as a difference of the entire dataset and the training view
Our data is stored in views named iris_train_data and iris_test_data — you guess which one holds what.
Let’s quickly check how many rows are in each:
SELECT COUNT(*) FROM iris_train_data;
>>> 111
SELECT COUNT(*) FROM iris_test_data;
>>> 39
We are ready to train the model, so let’s do that next.
Model training
The easiest method for model training is through DBMS_DATA_MINING package, with a single procedure execution, and without the need for creating additional settings tables.
We’ll use the Decision Tree algorithm to train our model. Here’s how:
DECLARE
v_setlst DBMS_DATA_MINING.SETTING_LIST;
BEGIN
v_setlst(‘PREP_AUTO’) := ‘ON’;
v_setlst(‘ALGO_NAME’) := ‘ALGO_DECISION_TREE’;
DBMS_DATA_MINING.CREATE_MODEL2(
‘iris_clf_model’,
‘CLASSIFICATION’,
‘SELECT * FROM iris_train_data’,
v_setlst,
‘iris_id’,
‘species’
);
END;
/The CREATE_MODEL2 procedure (curious why it wasn’t named CREATE_MODEL_FINAL_FINAL89) accepts a lot of parameters. Let’s explain the ones we entered:
iris_clf_model— simply the name of your model. Can be anythingCLASSIFICATION— type of machine learning task we’re doing. Must be uppercase for some reasonSELECT * FROM iris_train_data— specifies where the training data is storedv_setlst— above declared settings list for our modeliris_id— name of the sequence type column (each value is unique)species— name of the target variable (what we’re trying to predict)
Executing this block will take a second or two, but once done it’s ready for evaluation!
Model evaluation
Let’s use this script to evaluate our model:
BEGIN
DBMS_DATA_MINING.APPLY(
‘iris_clf_model’,
‘iris_test_data’,
‘iris_id’,
‘iris_apply_result’
);
END;
/It applies iris_clf_model to the unseen test data iris_test_data and stores evaluation results into a iris_apply_result table. Here’s how this table looks like:


It has many more rows (39 x 3), but you get the point. This still isn’t the most straightforward thing to look at, so let’s show the results in a slightly different way:
DECLARE
CURSOR iris_ids IS
SELECT DISTINCT(iris_id) iris_id
FROM iris_apply_result
ORDER BY iris_id;
curr_y VARCHAR2(16);
curr_yhat VARCHAR2(16);
num_correct INTEGER := 0;
num_total INTEGER := 0;
BEGIN
FOR r_id IN iris_ids LOOP
BEGIN
EXECUTE IMMEDIATE
‘SELECT species FROM
iris_test_data
WHERE iris_id = ‘ || r_id.iris_id
INTO curr_y;
EXECUTE IMMEDIATE
‘SELECT prediction
FROM iris_apply_result
WHERE iris_id = ‘ || r_id.iris_id ||
‘AND probability = (
SELECT MAX(probability)
FROM iris_apply_result
WHERE iris_id = ‘ || r_id.iris_id ||
‘)’ INTO curr_yhat;
END;
num_total := num_total + 1;
IF curr_y = curr_yhat THEN
num_correct := num_correct + 1;
END IF;
END LOOP;
DBMS_OUTPUT.PUT_LINE(‘Num. test cases: ‘
|| num_total);
DBMS_OUTPUT.PUT_LINE(‘Num. correct : ‘
|| num_correct);
DBMS_OUTPUT.PUT_LINE(‘Accuracy : ‘
|| ROUND((num_correct / num_total), 2));
END;
/Yes, it’s a lot, but the script above can’t be any simpler. Let’s break it down:
CURSOR— gets all distinct iris_ids (because we have them duplicated iniris_apply_resultstablecurr_y,curr_yhat,num_correct,num_totalare variables for storing actual species and predicted species at every iteration, number of correct classifications, and total number of test items- For every unique
iris_idwe get the actual species (fromiris_test_data, where ids match) and the predicted species (where prediction probability is the highest iniris_apply_resultstable) - Then it’s easy to check if the actual and predicted values are identical — which indicates the classification is correct
- Variables
num_totalandnum_correctare updated at every iteration - Finally, we print the model’s performance to the console
Here’s the output for this script:
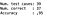

Awesome! To interpret:
- The test set has 39 cases
- Of these 39, 37 were classified correctly
- Which results in the 95% accuracy
And that’s pretty much it for the model evaluation.
Before you go
And there you have it — machine learning project written from scratch in SQL. Not all of us have the privilege to work with something like Python on our job, and if a machine learning task comes on your desk you now know how to solve it via SQL.
This was just a simple classification task, of course, and scripts can be improved further, but you get the point. I hope you’ve managed to follow along. For any questions and comments, please refer to the comment section.
Thanks for reading.
Originally published at https://www.betterdatascience.com on September 6, 2020.




No comments:
Post a Comment