f you are a Data Analyst or Data Scientist, you must know the Pandas library in Python that has already become the standard of data wrangling/cleansing tool in Python. However, there are some small tricks in Pandas that I bet you might not know all of them.
In this article, I’ll share some Pandas tricks that I know. I believe they will expedite our jobs and make our life easier sometimes. Now we should begin!
1. Create DataFrame from Clipboard


Well, you must know that Pandas can easily read from CSV, JSON and even directly from the database using SQLAlchemy, but do you know that Pandas can also read from the clipboard of our operating system?
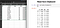
Suppose we have an Excel file with multiple datasheets. Now, we want to have partial data from one sheet to be processed in Python. What we usually might do to implement this?
- Copy the data that we need to be processed in Python from the datasheet.
- Paste it into another datasheet.
- Save the current sheet into CSV file.
- Get the path of the new CSV file.
- Go to Python, use
pd.read_csv('path/to/csv/file')to read the file into a Pandas data frame.
There is definitely an easier way of doing this, which is pd.read_clipboard().
- Copy the area of the data that you need.
- Go to Python, use
pd.read_clipboard().
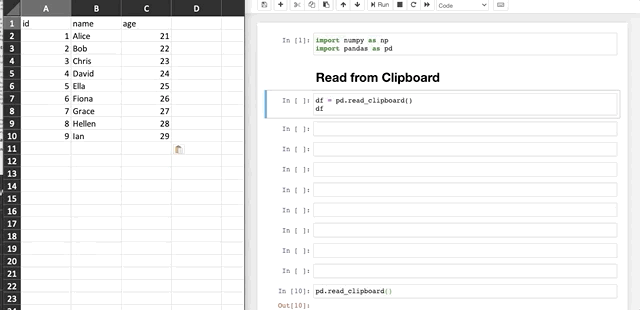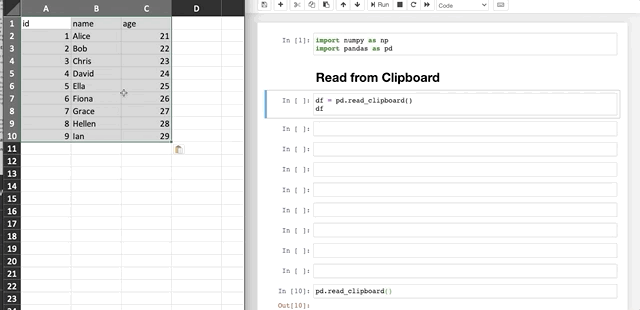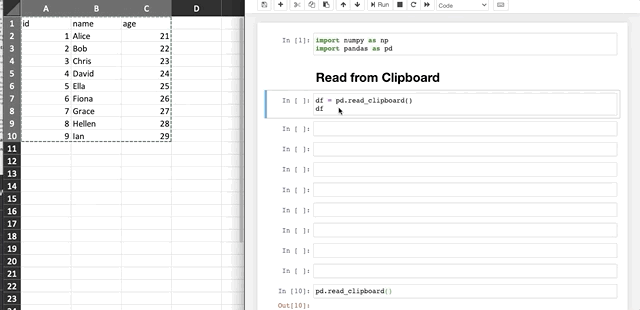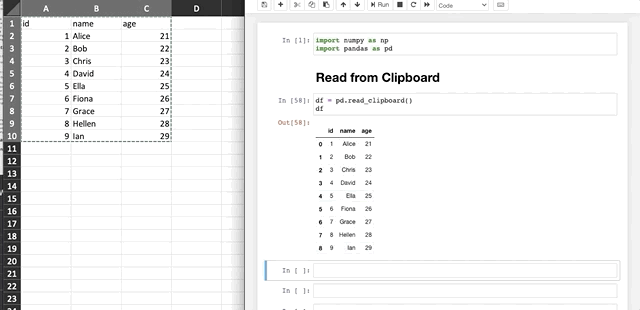
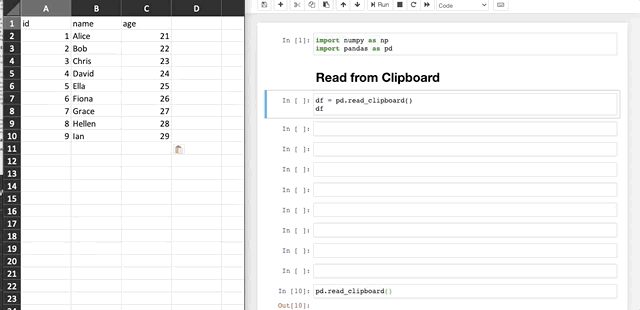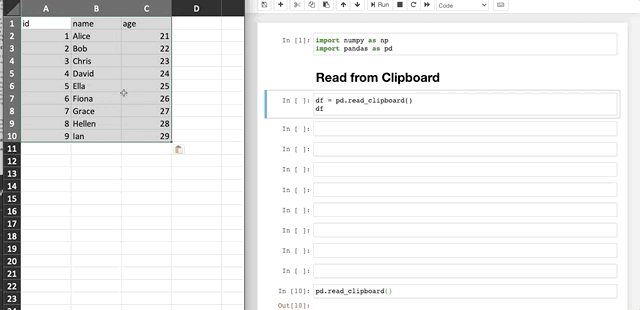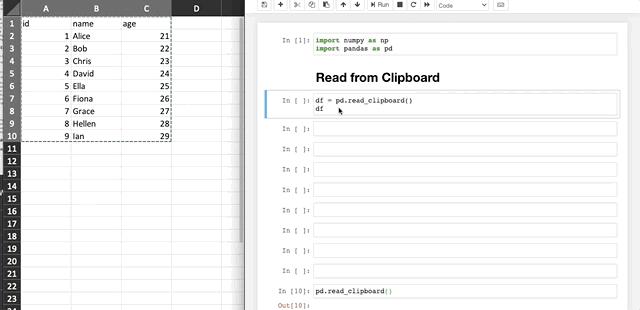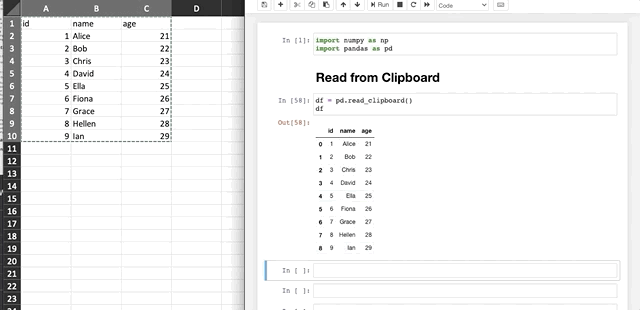
As shown above, how easy it is! You don’t need to have a separated CSV or Excel file if you just want to load some data into Pandas.
There are also some more tricks in this function. For example, when we have data with date format, it might not be correctly loaded as follows.
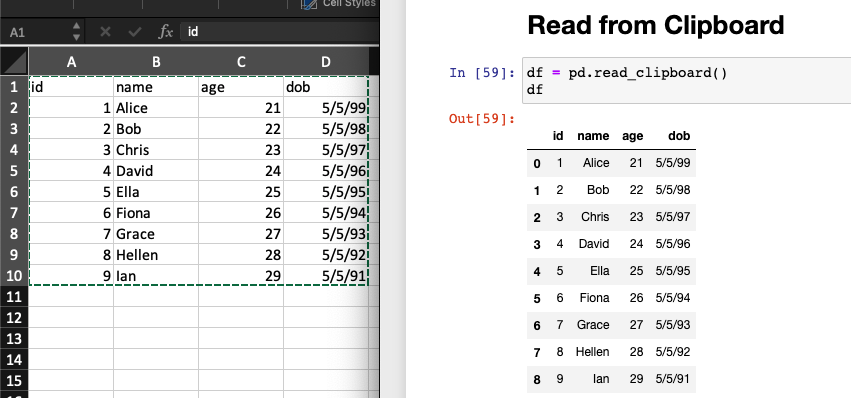
The trick is to let Pandas know which column is date format that needs to be parsed.
df = pd.read_clipboard(parse_dates=['dob'])

2. Generate Dummy Data Using Testing Methods


Sometimes we may want to generate some sample data frame. The most common method is probably using NumPy to generate an array with random values, and then generate data frame from the array.
I would say that we have to do it like this if we need the data to have a certain distribution, such as normal distribution. However, most of the time we may not care whether the data is normally distributed, we just want to have some data to play around. In this case, there is a much easier way to do so. That is, using pandas.util.testing package to generate the sample data frame.
pd.util.testing.makeDataFrame()The index of the data frame will be generated using random strings. By default, there will be 30 rows with 4 columns.


If we need a certain number of rows and columns, we can define the testing.N as the number of rows and testing.K as the number of columns.
pd.util.testing.N = 10
pd.util.testing.K = 5
pd.util.testing.makeDataFrame()

3. Output Data Frame into Compressed File


You must know that we can easily output a data frame into a file, such as df.to_csv(), df.to_json() and so on. But sometimes, we may want to compress the file to save the disk space or for other purposes.
For example, as a Data Engineer, I did meet such a requirement that is to output Pandas data frames into CSV files and transfer them into a remote server. To save the space as well as the bandwidth, the files need to be compressed before sending.
Usually, the typical solution could be adding one more step in the scheduling tool that is using such as Airflow or Oozie. But we know that we can directly let Pandas to output a compressed file. So, the solution will be neater and less complicated with fewer steps.
Let’s generate a random data frame using the Trick №2 :)
pd.util.testing.N = 100000
pd.util.testing.K = 5
df = pd.util.testing.makeDataFrame()

See, in this case, we just want a data frame and the values in it is totally not a concern.
Now, let’s save the data frame into a CSV file, and check the size.
import osdf.to_csv('sample.csv')os.path.getsize('sample.csv')


Then, we can test outputting the same data frame into a compressed file, and check the size of the file.
df.to_csv('sample.csv.gz', compression='gzip')os.path.getsize('sample.csv.gz')


We can see that the compressed file is less than half of the normal CSV file.
Please note that this might not be a good example, because we don’t have any repeated values in our random data frame. In practice, if we have any categorical values, the compression rate can be very high!
BTW, maybe you’re thinking the thing that I gonna say. Yes, Pandas can directly read the compressed file back into a data frame. You don’t need to unzip it in the file system.
df = pd.read_csv('sample.csv.gz', compression='gzip', index_col=0)

I prefer to use gzip because it exists in most of the Linux system by default. Pandas do also support more formats of compressions such as “zip” and “bz2”.
4. Get DateTime from Multiple Columns


I believe you must have used pd.to_datetime() method to convert some kind of string into DateTime format in Pandas. We usually use this method with a format string such as %Y%m%d.
However, we may have the following kind of data frame as our raw data, sometimes.
df = pd.DataFrame({
'year': np.arange(2000, 2012),
'month': np.arange(1, 13),
'day': np.arange(1, 13),
'value': np.random.randn(12)
})

It is not uncommon to have the year, month and day as separated columns in a data frame. In fact, we can use pd.to_dateframe() to convert them into a DateTime column in one step.
df['date'] = pd.to_datetime(df[['year', 'month', 'day']])

How easy it is!
Summary


In this article, I’ve shared some tricks that I believe are quite useful in Python Pandas library. I would say that these little tricks are not essentials that we have to know, of course. But by knowing them, sometimes can save time in our life.
I’ll be kept looking for more interesting stuff for Python. Please keep an eye on my profile. And finally:
Life is short, I use Python :)




No comments:
Post a Comment