What is a data pipeline?
A data pipeline consists of a sequence of processes for processing data. The data is ingested at the beginning of the pipeline if it has not yet been loaded into the data platform. In the following phases, each process produces an output that serves as the input for the next step. This continues until the pipeline is complete. Independent steps may be executed simultaneously in certain instances.Components of data pipeline:-
A source, a processing step or stages, and a destination are the three main components of a data pipeline.
Data Pipeline Considerations:-
Numerous considerations must be made while designing data pipeline designs. For instance,
- Does your pipeline need the ability to handle streaming data?
- What kind of data volume do you anticipate?
- How much and what sort of processing does the data pipeline require?
- Is the data created in the cloud or on-premises, and if so, where should it go?
- Are you planning to construct the pipeline using microservices?
- Is there a particular technology in which your team is already proficient at developing and maintaining?
Source/Reference: Towards Data Science article by Satish Chandra Gupta, hazelcast dot com

Scalable and efficient data pipelines are as important for the success of analytics, data science, and machine learning as reliable supply lines are for winning a war
Data Pipeline
A data pipeline is a series of data processing steps. If the data is not currently loaded into the data platform, then it is ingested at the beginning of the pipeline. Then there are a series of steps in which each step delivers an output that is the input to the next step. This continues until the pipeline is complete. In some cases, independent steps may be run in parallel.
Data pipelines consist of three key elements: a source, a processing step or steps, and a destination. In some data pipelines, the destination may be called a sink. Data pipelines enable the flow of data from an application to a data warehouse, from a data lake to an analytics database, or into a payment processing system, for example. Data pipelines also may have the same source and sink, such that the pipeline is purely about modifying the data set. Any time data is processed between point A and point B (or points B, C, and D), there is a data pipeline between those points.
As organizations look to build applications with small code bases that serve a very specific purpose (these types of applications are called “microservices”), they are moving data between more and more applications, making the efficiency of data pipelines a critical consideration in their planning and development. Data generated in one source system or application may feed multiple data pipelines, and those pipelines may have multiple other pipelines or applications that are dependent on their outputs.
Consider a single comment on social media. This event could generate data to feed a real-time report counting social media mentions, a sentiment analysis application that outputs a positive, negative, or neutral result, or an application charting each mention on a world map. Though the data is from the same source in all cases, each of these applications are built on unique data pipelines that must smoothly complete before the end user sees the result.
Common steps in data pipelines include data transformation, augmentation, enrichment, filtering, grouping, aggregating, and the running of algorithms against that data.
What Is a Big Data Pipeline?
As the volume, variety, and velocity of data have dramatically grown in recent years, architects and developers have had to adapt to “big data.” The term “big data” implies that there is a huge volume to deal with. This volume of data can open opportunities for use cases such as predictive analytics, real-time reporting, and alerting, among many examples.
Like many components of data architecture, data pipelines have evolved to support big data. Big data pipelines are data pipelines built to accommodate one or more of the three traits of big data. The velocity of big data makes it appealing to build streaming data pipelines for big data. Then data can be captured and processed in real time so some action can then occur. The volume of big data requires that data pipelines must be scalable, as the volume can be variable over time. In practice, there are likely to be many big data events that occur simultaneously or very close together, so the big data pipeline must be able to scale to process significant volumes of data concurrently. The variety of big data requires that big data pipelines be able to recognize and process data in many different formats—structured, unstructured, and semi-structured.
Data Pipeline vs. ETL
ETL refers to a specific type of data pipeline. ETL stands for “extract, transform, load.” It is the process of moving data from a source, such as an application, to a destination, usually a data warehouse. “Extract” refers to pulling data out of a source; “transform” is about modifying the data so that it can be loaded into the destination, and “load” is about inserting the data into the destination.
ETL has historically been used for batch workloads, especially on a large scale. But a new breed of streaming ETL tools are emerging as part of the pipeline for real-time streaming event data.
Data Pipeline Considerations
Data pipeline architectures require many considerations. For example, does your pipeline need to handle streaming data? What rate of data do you expect? How much and what types of processing need to happen in the data pipeline? Is the data being generated in the cloud or on-premises, and where does it need to go? Do you plan to build the pipeline with microservices? Are there specific technologies in which your team is already well-versed in programming and maintaining?
Architecture Examples
Data pipelines may be architected in several different ways. One common example is a batch-based data pipeline. In that example, you may have an application such as a point-of-sale system that generates a large number of data points that you need to push to a data warehouse and an analytics database. Here is an example of what that would look like:

Another example is a streaming data pipeline. In a streaming data pipeline, data from the point of sales system would be processed as it is generated. The stream processing engine could feed outputs from the pipeline to data stores, marketing applications, and CRMs, among other applications, as well as back to the point of sale system itself.
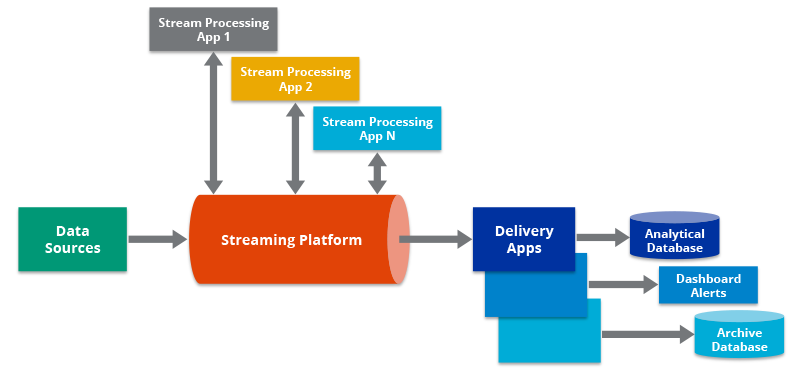
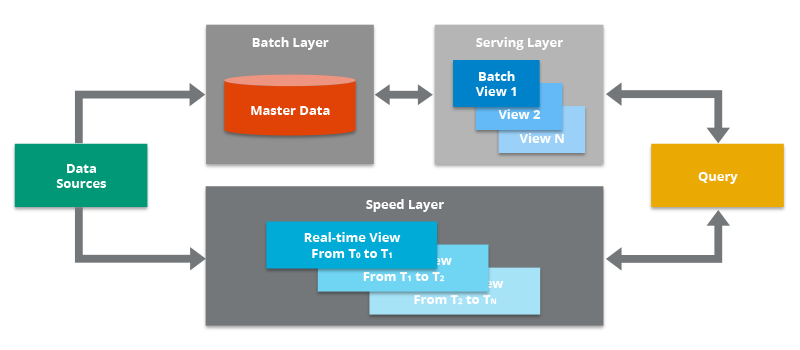
A third example of a data pipeline is the Lambda Architecture, which combines batch and streaming pipelines into one architecture. The Lambda Architecture is popular in big data environments because it enables developers to account for both real-time streaming use cases and historical batch analysis. One key aspect of this architecture is that it encourages storing data in raw format so that you can continually run new data pipelines to correct any code errors in prior pipelines, or to create new data destinations that enable new types of queries.




No comments:
Post a Comment