Databricks)

In this blog post, I will explain 5 reasons to prefer the Delta format to parquet or ORC when you are using Databricks for your analytic workloads.
But before we start, let’s have a look at what is delta format.
Delta … an introduction
Delta is a data format based on Apache Parquet. It’s an open source project (https://github.com/delta-io/delta), delivered with Databricks runtimes and it’s the default table format from runtimes 8.0 onwards.
You can use Delta format through notebooks and applications executed in Databricks with various APIs (Python, Scala, SQL etc.) and also with Databricks SQL.
As said above, Delta is made of many components:
- Parquet data files organized or not as partitions
- Json files as transaction log
- Checkpoint file
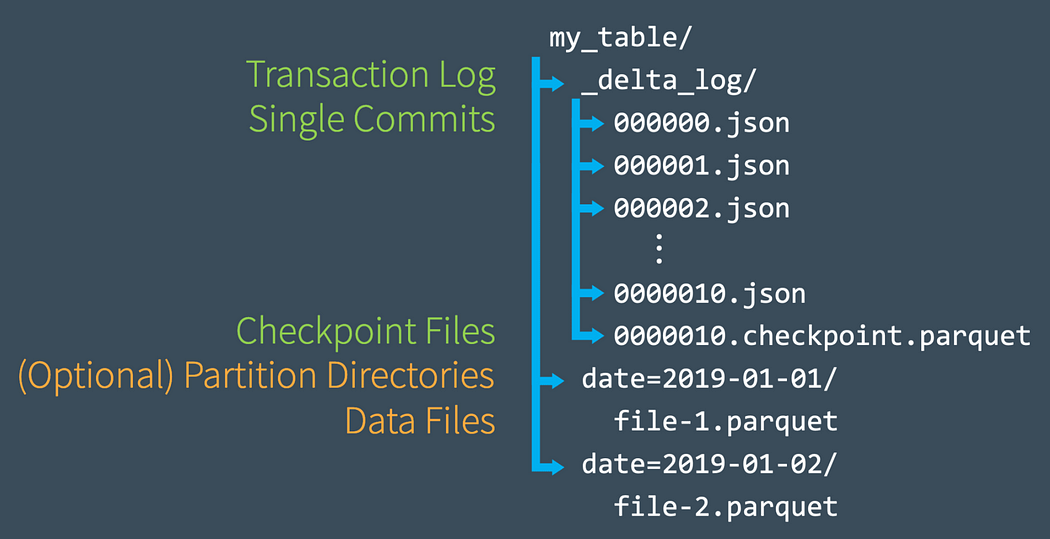
All of this is built on top of your datalake which can be hosted on AWS S3, Microsoft Azure DataLake, or Google Storage service. So it’s built to work on high data volumes … by design.
As a consequence:
- Delta is, like Parquet, a columnar oriented format. So, it’s best fitted for analytic workloads.
- With Delta transaction log files, it provides ACID transactions and isolation level to Spark.
These are the core features of Delta that make the heart of your lakehouse, but there are more features. I have selected 5 of them as a reason to choose Delta for your analytic workloads on Databricks.
#1: Caching

As Databricks is a platform based on Apache Spark, you probably know that Spark has its own caching features based on DataFrames and RDDs. For example, after loading your dataframe from files, you can call the cache() or persist() functions to tell the Spark Engine to cache data into the worker memory.
Delta comes with 2 caching features, the Delta Cache and the Result Cache (Well, in fact, Result cache is a feature of Delta Cache).
Delta Cache
Delta Cache will keep local copies (files) of remote data on the worker nodes. This is only applied on Parquet files (but Delta is made of Parquet files). It will avoid remote reads during big workloads. If you choose the ideal VM SKUs with big local caches on NVMe/SSD disks (i3 instances on AWS / E and L series on Azure), you will take all the benefits of the Delta Cache.
As the Delta cache uses local storage, you are able to configure the amount of storage dedicated for this cache and its sub-sections:
spark.databricks.io.cache.maxDiskUsage: disk space per node reserved for cached data in bytes
spark.databricks.io.cache.maxMetaDataCache: disk space per node reserved for cached metadata in bytes
spark.databricks.io.cache.compression.enabled: should the cached data be stored in compressed format
To demonstrate delta cache improvements, I built a small test. In this test, I ran twice the same query against 3 data-sources (in Parquet and in Delta) on a 2 worker nodes cluster based on E Series instance. As you can see, execution time is drastrically reduced for the second execution when data is stored on Delta (the 20 secs are due to fetch operation).
And last but not least, compared to Spark, I didn’t have to change my code (as this feature is enabled by default. See spark.databricks.io.cache.enabled parameter)

Result Cache (Part of Delta Cache)
Another cool caching feature of the Delta cache is the ability to cache a subset of data (query results).
This feature can be very helpful if you need consistent performance on a specific query. Once the query (and its results) is cached, subsequent queries executions avoid to read files (as much as possible). The result cache is automatically invalidated once of the underlying files is updated or if the cluster is restarted.
This is enabled with the reserved word CACHE:

#2: Time travel

Another reason to choose Delta for your data format is for its time travel feature.
As it was mentioned in this post’s introduction, Delta is a Parquet format enhanced with a delta log which is basically a transaction log. And, if like me, you come from the rDBMS world, this log works similarly as a redo log in Oracle or in a WAL in Postgres etc. It will record all the changes made on your delta location (file addition/deletion, files stats etc.) and as a classic transaction log, all of these operations will be timestamped.
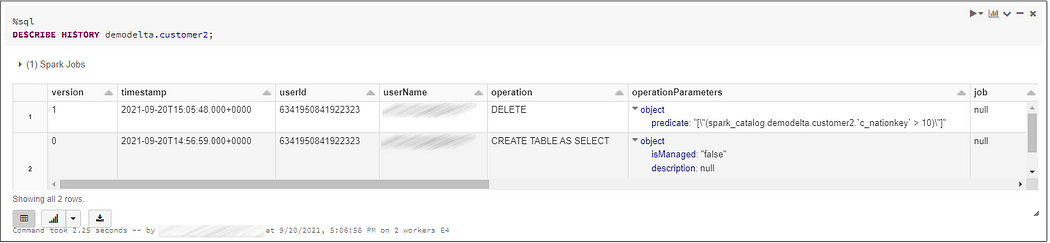
In the following example, we can see the delta log content for a table creation made with a CREATE TABLE AS SELECT statement with one file added and stored as parquet file (with 1256500 records in it, and statis on data referenced as minValues):

The cool feature that comes with is that you can now query your delta location (or table) as it was of a specific timestamp, query change history, and even restore a table as it was in the past. For example, if you have your gold area managed by Delta, your data scientists are able to run their model on data as it was at a specific timestamp.
In the screenshot below, we are able to query change history on a specific table. It works fine too with the syntax:
DESCRIBE HISTORY delta.`/mnt/data-delta/cust2`;We can see that some data has been deleted on this table with the predicate “c_nationkey>10”
Once we have changes history, we are now able to query data as it was at a specific timestamp or a version.

Note: By default, Delta keeps 7 days of data, as a consequence you have a 7 days data history. We’ll see later on this post how to configure and the impact it can have if you play with some command (like VACUUM).
#3: Merging datasets

Another reason to choose Delta for your data format is the ability to MERGE two datasets based on a condition. For example, if the condition is true, it will execute an UPDATE statement, if not, an INSERT statement depending on your need. This is a common feature on rDBMS, now it’s enabled for analytics and Big Data workloads with the benefit of parallel processing.
Below, you can find an example of a basic MERGE statement (it will insert data only when match condition is not true … really basic 😋).
It’s given as a SQL statement but you can code this statement in all API languages available (See https://docs.delta.io/latest/delta-update.html#upsert-into-a-table-using-merge for examples in Python, Java and Scala)

#4: Optimization
For all readers who usually work on bigdata workloads, we all know that the underlying file structure of a table (or directory) is very important to get high performance, especially when your data is spreaded in a collection of multiple small files which is evil for performance 😉.
We all know that data is a living thing and the number of files in a folder can evolve and even inside each file, data can be unsorted inside columns and this can have an impact on how data is accessed during reads.
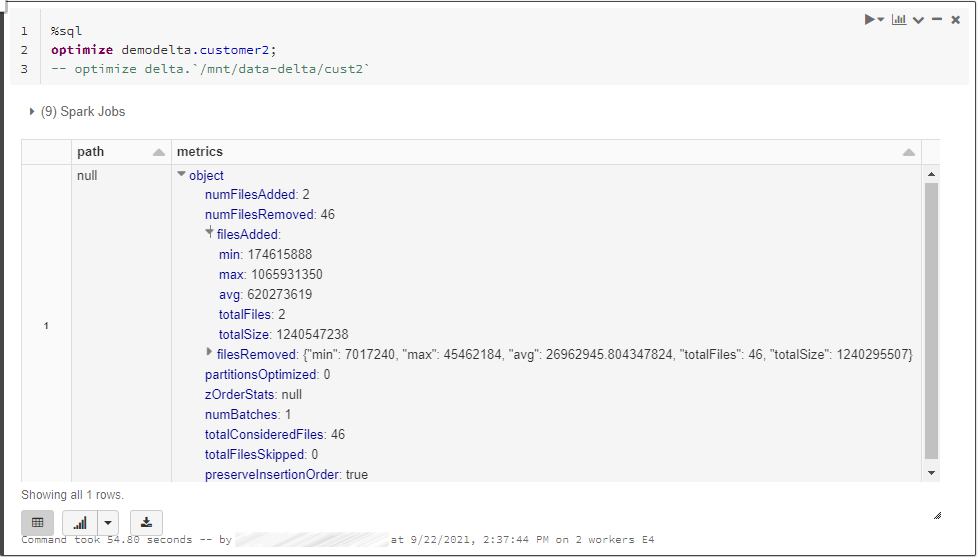
Delta on Databricks comes with two optimizations which can result in a better data organization inside data files, and a better file structure with less files. These two optimizations are managed by the OPTIMIZE command where documentation is available at this address: https://docs.databricks.com/spark/latest/spark-sql/language-manual/delta-optimize.html
File count reduction for a table (folder)
To reduce file count for a table or a delta folder, you can run one of the following command:
Note: it’s possible to add a WHERE clause in order to optimize a subset of your data or specific partitions.
In this example, we can see that 2 files have been added and 46 files removed (and other stats) but, if we have a look to the underlying folder, we will see that all the files are still there.
$ az storage fs file list — account-name myADLSGen2Account -f data-delta — path cust2/ — recursive false -o table — exclude-dir | wc -l60
They remain here to obey time travel feature and for consistent reads. If you run a VACUUM statement on it, you could encounter some problems:

$ az storage fs file list — account-name myADLSGen2Account -f data-delta — path cust2/ — recursive false -o table — exclude-dir | wc -l2
WARNING: using VACUUM after unlocking it by setting spark.databricks.delta.retentionDurationCheck.enabled to false is not recommended in production and is given for education purpose only. Using VACUUM on delta tables can produce side effects by removing data needed for consistent reads or time travel function as described in the example above. By default, an implicit VACUUM is executed on a 7 days interval default value (see: https://docs.databricks.com/delta/delta-batch.html#data-retention for more parameters related to data retention on delta tables).
Note: You can control the maximum file size gotten after the OPTIMIZE command. This is done by setting spark.databricks.delta.optimize.maxFileSize (default is set to 1Gb).
Data organization inside data files.
Even after optimizing the file structure in order to deal with bigger files, it’s still probable that your data (stored as columns) is located is many files. As a result, for a required group of columns (in your SELECT clause), the related data will be spread in multiple files and will lead into excessive IOs. To summarize, your data won’t be colocated into a file.
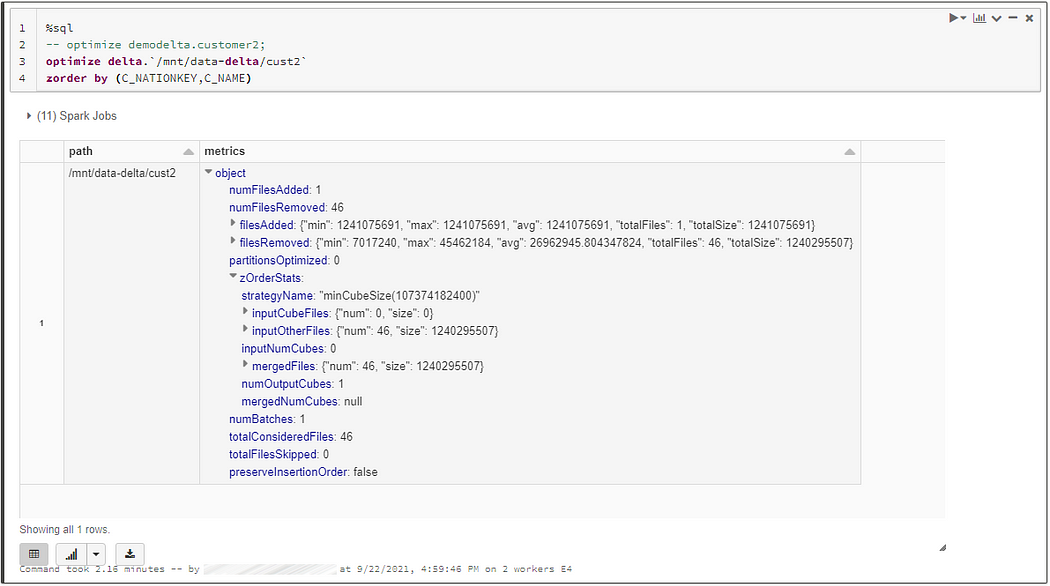
To solve this issue, the OPTIMIZE command can be appended with the ZORDER BY option followed by the column names to colocate inside the same files. This command will produce data clusters with min-max range of narrow and non overlapping data. As a result, it can reduce by 90% the amount of data read (depending on data content, clustered data, number of columns etc.)

Below, an example of a ZORDER execution on our customer2 table.
#5: Schema evolution

In Apache Spark SQL Api and therefore in Databricks, you use Dataframes which are associated to a schema. A schema defines the data structure contained inside the Dataframe. As we’ve seen earlier in this post, in Delta the schema is embedded in the transaction log and when you write data to a Delta table, it’s not possible to use a different schema.
But data lifecycle is not a long quiet river and data schema can evolve: you can add columns with new data, new indicator and more basically, data can be enrich with new values. Nevertheless, in the big data world, if you have a table which contains terabytes of data, it can become challenging and time consuming to deal with schema evolution.
In the example below, I created a new dataframe named “newCustDf” from the initial Delta Table (Customer2) and I’ve filtered only one row (C_CUSTKEY=1) and then I’ve added a new column named “NewCol” with a default value in it.
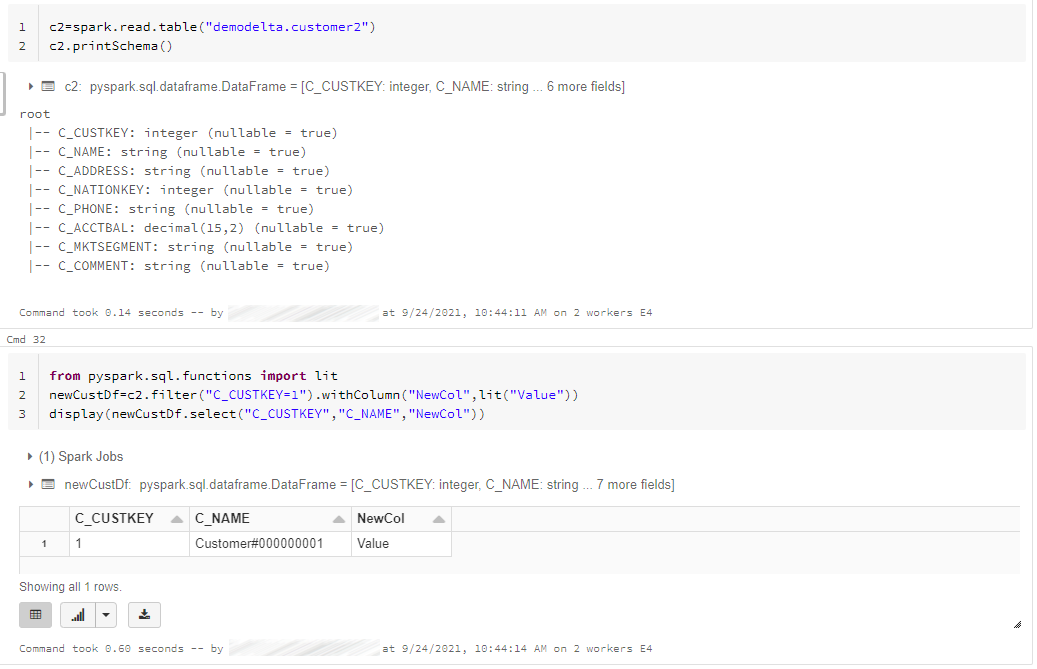
Then I executed a write function with Delta format (this is mandatory in order to merge Schemas) with two options:
- mode=append, to append new data to the existing table
- option mergeSchema set to True to enable schema merge
Please note that I wrote the result in the initial existing table “demodelta.customer2”

As a result, my initial table has evolved in terms of data and schema:
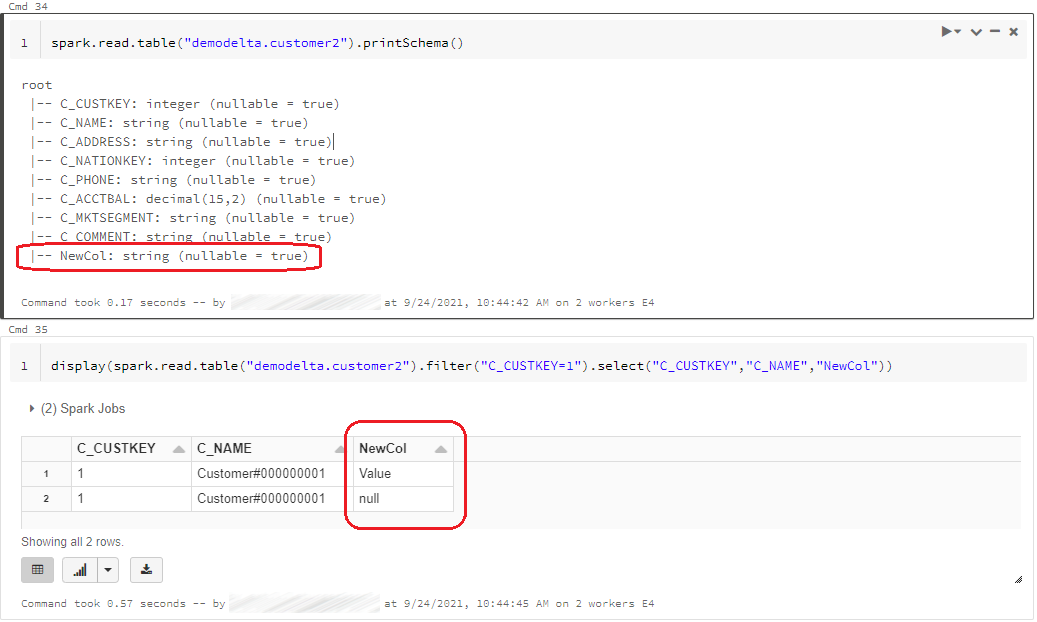
And that’s all ?
Well, in fact not really. Delta is now the default format in recent Databricks runtimes and there are lots of new features added.
For example, Delta Live Table which is a solution to build reliable data pipelines on top of Delta, or Delta Sharing which is an open protocol (REST Based) for secure data sharing. Delta Sharing enables the capability to share large datasets across various clients and products, including data generated in real-time.
These technologies built on top of Delta prove that Delta is now a central data format which enables a part of Databricks performance and reliability.
And that’s it for today !!! 😀




No comments:
Post a Comment