Big Data and (Py)Spark - Introduction
Introduction
In this section, you will be introduced to the idea of big data and the tools data scientists use to manage it.
Big Data
Big data is undoubtedly one of the most hyped terms in data science these days. Big data analytics involves dealing with data that is large in volume and high in variety and velocity, making it challenging for data scientists to run their routine analysis activities. In this section, you'll learn the basics of dealing with big data through parallel and distributed computing.
Parallel and Distributed Computing with MapReduce
We start this section by providing more context on the ideas of parallel and distributed computing and MapReduce. When talking about distributed and parallel computing, we refer to the fact that complex (and big) data science tasks can be executed over a cluster of interconnected computers instead of on just one machine. You'll learn that MapReduce allows us to convert these big datasets into sets of tuples as key:value pairs, as we'll cover in more detail in this section.
Apache Spark and PySpark
Apache Spark is an open-source distributed cluster-computing framework that makes it easier (and feasible) to use huge amounts of data! It was developed in response to limitations of MapReduce and written using the Scala programming language. Fortunately for Python developers, there is also a Python interface for Spark called PySpark. Throughout these lessons we will use the terms "Spark" and "PySpark" fairly interchangeably, though technically "Spark" is the underlying framework and "PySpark" is the Python library we'll be using.
RDDs (Resilient Distributed Datasets)
Resilient Distributed Datasets (RDDs) are the core concept in PySpark. RDDs are immutable distributed collections of data objects. Each dataset in RDD is divided into logical partitions, which may be computed on different computers (so-called "nodes") in the Spark cluster. In this section, you'll learn how RDDs in Spark work. Additionally, you'll learn that RDD operations can be split into actions and transformations.
Word Count with MapReduce
You'll use MapReduce to solve a basic NLP task where you compare the attributes of different authors of various texts.
Machine Learning with Spark
After you've solved a basic MapReduce problem, you will learn about employing the machine learning modules of PySpark. You will perform both a regression and classification problem and get the chance to build a full parallelizable data science pipeline that can scale to work with big data. In this section, you'll also get a chance to work with PySpark DataFrames.
Installing and Configuring PySpark with Docker
PySpark was not part of the original environment setup you completed. While the interface is in Python, Spark relies on an underlying Java virtual machine (JVM) that can be challenging to install. Therefore rather than installing Spark on your computer directly, we'll go over how to use a Docker container for this purpose.
Summary
In this section, you'll learn the foundations of Big Data and how to manage it with Apache Spark!
----------------
(Py)Spark Basics
Introduction
Before we begin writing PySpark code, let's go over some more of the concepts that underpin Apache Spark.
Objectives
You will be able to:
- Describe the high-level architecture of Apache Spark
- Describe the driver, worker, and executor in the context of Spark's parallelism
- Describe the data structures used by Apache Spark and PySpark in particular
- List use cases for Spark
Spark Architecture
The high-level architecture of the Apache Spark stack looks like this:
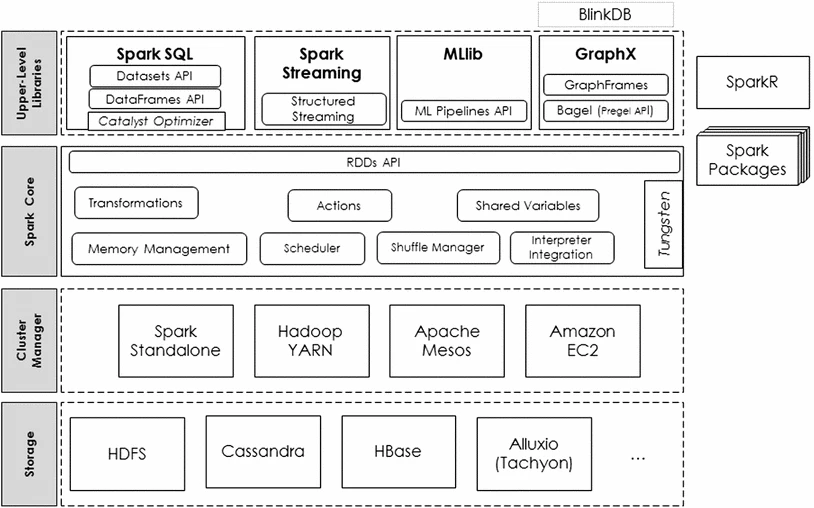
(Figure from Big data analytics on Apache Spark)
We'll start at the bottom and work our way up.
Storage
We won't focus too much on the specifics here, since they are applicable to all sorts of distributed computing systems. The main thing to be aware of is that production-grade Big Data stacks require specialized file systems.
Some storage options that are compatible with Spark are:
Cluster Manager

(Figure from Cluster Mode Overview)
As mentioned previously, Big Data tools typically rely on distributed and parallel computing. This is implemented in the Apache Spark stack using a cluster manager.
The main takeaway here should be a basic familiarity with the terminology.
A cluster is a group of interconnected computers used for distributed and parallel computing. A cluster manager manages those machines by allocating resources and connecting the driver program and worker nodes. A driver program maintains information about your application, responds to external programs, and analyzes, distributes, and schedules work across worker nodes. Worker nodes contain executor processes that execute the code assigned by the driver.
Here are links to some cluster manager options:
A Note About The Spark Curriculum
Because the curriculum lessons and labs are smaller, proof-of-concept applications of Spark, we will not be using a special distributed file storage system like HDFS or a full-fledged cluster manager like YARN. Instead, we will use Spark Standalone with a local cluster.
Typically a data scientist or data engineer would not be responsible for managing a cluster. In fact, you can refer to the PySpark documentation, which contains a version of the Spark architecture diagram that doesn't even include the storage and cluster manager layers. Instead it just focuses on the Spark Core and upper-level libraries:

Spark Core (Unstructured API)
Advantages Over MapReduce
The Spark Core is where Spark's advantages over MapReduce appear. To quote from Big data analytics on Apache Spark (emphasis added):
Apache Spark has emerged as the de facto standard for big data analytics after Hadoop’s MapReduce. As a framework, it combines a core engine for distributed computing with an advanced programming model for in-memory processing. Although it has the same linear scalability and fault tolerance capabilities as those of MapReduce, it comes with a multistage in-memory programming model comparing to the rigid map-then-reduce disk-based model. With such an advanced model, Apache Spark is much faster and easier to use.
Apache Spark leverages the memory of a computing cluster to reduce the dependency on the underlying distributed file system, leading to dramatic performance gains in comparison with Hadoop’s MapReduce.
Recall the difference between data or models in memory (e.g. data stored in a Python variable) vs. on disk (e.g. a CSV or pickled model file). Almost all of the data work we do in this curriculum is in memory, since this is much faster and more flexible than performing all of the IO operations needed to save everything to disk. Spark uses this same approach.
You can read more about the specific performance gains made by Spark compared to MapReduce here.
Unstructured API
Functionality within the Spark Core is also referred to as the "Unstructured API".
Note: "API" doesn't necessarily mean an HTTP API accessed over the internet -- in this case it just means the interface of classes and functions that your code can invoke.
The Unstructured API is the older, lower-level interface.
Note: "lower-level" is literally true in the case of the figure shown at the top of this lesson, but it also generally means that a tool is closer to the underlying machine code executing on a computer. That means that it is usually more configurable than a higher-level tool, but also that it tends to be more difficult to use and is possibly not optimized for specific use cases.
It includes some constructs that resemble MapReduce constructs, such as Accumulators and Broadcast variables, as well as SparkContext and Resilient Distributed Datasets (RDDs). You can find the full PySpark Unstructured API documentation here.
SparkContext
SparkContext is the entry point for using the Unstructured API. You'll notice it is inside the "Driver Program" rectangle in the cluster manager figure above. We will cover more details of how SparkContext is used with PySpark in a future lesson. You can also read more from the PySpark documentation here.
Resilient Distributed Datasets (RDDs)
Resilient Distributed Datasets (RDDs) are the fundamental data structure used by the Spark Core and accessible via the Unstructured API. Once again, we will cover more details in a future lesson, and you can read more from the PySpark documentation here.
Upper-Level Libraries (Structured API)
The upper-level libraries, also known as the Structured API, is where Spark gets really exciting. They are higher-level, easier to use, and optimized for particular tasks.
For data analysis and manipulation, the Structured API offers Spark SQL, a pandas API, and Spark Streaming. For machine learning the Structured API offers MLlib.
Spark SQL
Spark SQL has data structures called DataFrame and Dataset.
A Spark SQL DataFrame is similar to a pandas DataFrame in that it keeps track of column names and types, which improves efficiency and makes the data easier to work with. It is not the same as the DataFrame used in the pandas API, although it is possible to convert between them if necessary. You can find more documentation here.
A Spark SQL Dataset works similar to a DataFrame except it has an additional Row construct. Datasets are not usable in PySpark (only in Scala and Java) at this time, although you may see references to them in the main Spark documentation.
Rather than a SparkContext like is used for the Unstructured API, the entry point to Spark SQL is a SparkSession. You can find more documentation here.
Pandas API
The pandas API allows you to use familiar pandas class and function names, with the power of Spark! The PySpark maintainers recommend that anyone who already knows how to use pandas uses this API. You can find the API reference here and user guide here.
Spark Streaming
Streaming data is outside the scope of this curriculum, but it's useful to know that Spark has functionality for it. You can find the PySpark documentation for Spark Streaming here.
MLlib
MLlib allows you to perform many of the same machine learning tasks as scikit-learn, including transforming data, building and evaluating supervised and unsupervised machine learning models, and even building pipelines. There is also an Alternating Least Squares (ALS) implementation, which we will apply to a recommender system!
You can find the PySpark documentation for MLlib here.
Additional Resources
- Big data analytics on Apache Spark (2016) is an excellent review article. It should take 90-120 minutes to read, and we highly encourage you to take the time if you're interested in using Spark.
- Intro to Apache Spark (2014) is a 194-slide presentation that goes into more detail about Spark with many code examples. Note: it appears that links in the slide deck starting with
cdn.liber118.comare no longer working, but the GitHub links are still functional.
Summary
At a high level, Spark's architecture consists of:
- Storage
- Cluster Manager
- Spark Core (Unstructured API)
- Upper-Level Libraries (Structured API)
The Cluster Manager divides and shares the physical resources of a cluster of machines, utilizing a driver program that specifies tasks for executors within worker nodes.
The Spark Core (Unstructured API) is accessed using SparkContext, and utilizes the RDD data structure.
The upper-level libraries (Structured API) include code for specific use cases, including data analysis and manipulation (Spark SQL, pandas API, Spark Streaming) and machine learning (MLlib). Spark SQL is accessed using SparkSession and introduces two additional data structures (DataFrame and Dataset).
Now that we've covered the concepts, let's dive into some specific implementations!
------------------------
Understanding SparkContext - Codealong
Introduction
SparkContext is the entry point for using the Unstructured API of Spark. In this lesson we'll go over how SparkContext works in PySpark, create a SparkContext called sc, and explore sc's properties.
Objectives
You will be able to:
- Define a SparkContext and why it is important to a Spark application
- Create a SparkContext with PySpark
- List the major properties and methods of SparkContext
The Purpose of the SparkContext
Spark Application Architecture
Recall this figure from the Cluster Mode Overview:
When you are writing Spark code, your code is the "Driver Program" pictured here. Your code needs to instantiate a SparkContext if we want to be able to use the Spark Unstructured API.
PySpark Stack
Since we are not writing Spark code in Scala, but instead are writing PySpark code in Python, there is some additional architecture to be aware of.
Specifically, all Spark code needs to be able to run on the JVM (Java Virtual Machine), because PySpark is built on top of Spark's Java API. PySpark uses the Py4J library under the hood to accomplish this.
This is relevant to your development process because:
- Sometimes you will see error messages or warnings related to Java code.
- Many of the function and variable names follow Java naming conventions rather than Python. In particular, you will see many examples of
camelCasenames in places where you would expectsnake_casePython names.
The architecture including Py4J is something like this (from the PySpark Internals wiki):

The driver program launches parallel operations on executor Java Virtual Machines (JVMs). This can occur either locally on a single machine using multiple cores to create parallel processing or across a cluster of computers that are controlled by a master computer. When running locally, "PySparkShell" is the application name. The driver program contains the key instructions for the program and it determines how to best distribute datasets across the cluster and apply operations to those datasets.
The key takeaways for SparkContext are listed below:
- SparkContext is a client of Spark’s execution environment and it acts as the master of the Spark application
- SparkContext sets up internal services and establishes a connection to a Spark execution environment
- The driver is the program that creates the SparkContext, connecting to a given Spark Master
After creation, SparkContext asks the master for some cores to use to do work. The master sets these cores aside and they are used to complete whatever operation they are assigned to do. You can visualize the setup in the figure below:

This image depicts the worker nodes at work. Every worker has 4 cores to work with, and the master allocates tasks to run on certain cores within each worker node.
Creating a Local SparkContext
While the SparkContext conceptual framework is fairly complex, creating a SparkContext with PySpark is fairly simple. All we need to do is import the relevant class and instantiate it.
Importing the SparkContext Class
As we can see from the documentation, there is an example import statement:
# Import the SparkContext class from the pyspark.context submodule
from pyspark.context import SparkContextType this code in the cell below and execute the cell.
# Import the SparkContext class from the pyspark.context submoduleInstantiating sc
Naming Convention
The conventional name for the SparkContext object is sc. In fact, in some (Py)Spark environments, there will already be an object in memory called sc as soon as the environment is loaded. Therefore unless you have a very specific reason for changing the name, you are strongly encouraged to use the name sc to represent the SparkContext.
Parameters
In theory you could simply call SparkContext() to create your SparkContext, but in practice you should specify values for two parameters: master and appName.
The master parameter is the cluster URL to connect to. If you were using a full-fledged Cluster Manager this URL might be something like "mesos://host:5050" but we are just running a local cluster. Therefore we'll specify a master value of "local[*]". The * means that we are telling Spark to run on all available cores of our machine.
The appName parameter is just a label for the application. It's similar to a Python variable name -- just there to help you understand what the code is doing. You can put any string value you like.
Codealong
In the cell below, instantiate a variable sc using the SparkContext class, a master of "local[*]", and an appName of "sc practice".
# Instantiate sc
sc = SparkContext("local[*]", "sc practice")# Instantiate scYou may see some Java warnings appear below this line of code (or other lines of code). In general you can safely ignore these warnings, although they may provide relevant information for debugging.
One SparkContext at a Time
Note that you can only have one SparkContext at a time. If you try to make another one without stopping the first one, you will get an error:
# Bad idea - creating a second SparkContext
try:
another_sc = SparkContext("local[*]", "double trouble")
except Exception as e:
print(type(e))
print(e)Properties and Methods of SparkContext
Now we have a SparkContext object! Let's investigate it like any other Python object.
Type
What is the type of our SparkContext?
Click to Reveal Code
# Type of scClick to Reveal Expected Output
All Attributes
Use Python's dir built-in function (documentation here) to get a list of all attributes (including methods) accessible through the sc object.
Click to Reveal Code
# Get a list of all attributesClick to Reveal Expected Output
Python Help
We have a list of attributes, but no explanation of how to use them. Use Python's help function (documentation here) to get an easier-to-read list of all the attributes, including examples, that the sc object has.
Click to Reveal Code
# Use Python's help function to get information on attributes and methods for sc objectClick to Reveal Expected Output
Investigating Specific Attributes
Refer to the PySpark documentation to find the appropriate attributes to answer these questions.
Spark Version
What version of Spark is the application running?
Click to Reveal Code
# Spark versionStart Time
What time was the Spark Context created?
Click to Reveal Code
# Start timeNote that this is the epoch time so it will appear as a large integer.
All Configuration Settings
We can access the complete configuration settings (including all defaults) for the current SparkContext by chaining together the getConf() method and the getAll() method.
Click to Reveal Code
# All configuration settingsShutting Down the SparkContext
When you are finished using a SparkContext, be sure to call the stop method. This will allow you to create another SparkContext in the future.
Click to Reveal Code
# Shut down SparkContextOnce shut down, you can no longer access Spark functionality before starting a new SparkContext.
try:
sc.version
except Exception as e:
print(type(e))
print(e)Additional Resources
Summary
In this codealong, we saw how SparkContext is used as an entry point to Spark applications. We learned how to start a SparkContext, how to list and use some of the attributes and methods in SparkContext and how to shut it down. Students are encouraged to explore other attributes and methods offered by the sc object. Some of these, namely creating and transforming datasets as RDDs, will be explored in later labs.




No comments:
Post a Comment