Scikit-learn pipelines provide a really simple way to chain together the preprocessing steps with the model fitting stages in machine learning development. With pipelines, you can embed these steps so that in one line of code the model will perform all necessary preprocessing steps at the same time as either fitting the model or calling predict.
There are many benefits to this besides reducing the lines of code in your project. Using the standard pipeline layouts means that it is very easy for a colleague, or your future self, to quickly understand your workflow. This in turns means that your work is more reproducible. Additionally, with pipelines, you can enforce the order in which transformations happen.
There is however one drawback in that, although scikit-learn models have the benefit of being highly explainable. Once you embed the model into a pipeline it becomes difficult to extract elements such as feature importances that make these models so interpretable.
I have been spending some time recently looking at this problem. In the following article, I am going to present a simple method I have found to extract feature importances from a pipeline using the python library ELI5.
Simple pipeline
In this article, I am going to be using a dataset from drivendata.org, a machine learning competition website. The dataset can be downloaded here.
First I’ll import all the libraries I am using.
import pandas as pd import numpy as npfrom sklearn import preprocessing from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler from sklearn.compose import ColumnTransformer from sklearn.metrics import f1_score from sklearn.preprocessing import OneHotEncoder from sklearn.base import BaseEstimator, TransformerMixin from sklearn.metrics import classification_report from sklearn.linear_model import LogisticRegressionimport eli5
I am then using the pandas library to read in the datasets that I have previously downloaded. The features and target labels are in separate CSV files so I am also using the pandas merge function to combine them into one data frame.
train_values = pd.read_csv('train_values.csv')
train_labels = pd.read_csv('train_labels.csv')
train_data = train_values.merge(train_labels, left_on='building_id', right_on='building_id')
If we inspect the data types we can see that there are a mixture of numerical and categorical data. We will, therefore, need to apply some preprocessing before training a model. A pipeline will, therefore, be useful for this dataset.
train_data.dtypes


Before constructing the pipeline I am dropping the ‘building_id’ column as it will not be needed for training, splitting the data into test and train sets, and defining some variables to identify the categorical and numerical columns.
train_data = train_data.drop('building_id', axis=1)numeric_features = train_data.select_dtypes(include=['int64', 'float64']).drop(['damage_grade'], axis=1).columns categorical_features = train_data.select_dtypes(include=['object']).columns X = train_data.drop('damage_grade', axis=1) y = train_data['damage_grade'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
I am going to construct a simple pipeline which will chain together the preprocessing and model fitting steps. Additionally, I am going to add an imputer for any missing values. Although the dataset I am using here does not have any missing data it is sensible to add in this step. This is because in the real world if we were deploying this as a machine learning application there is a chance that new data we are trying to predict on may have missing values. It is, therefore, good practice to add this as a safety net.
The code below constructs a pipeline that imputes any missing values, applies a standard scaler to the numerical features, converts any categorical features into numerical and then fits a classifier.
numeric_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')), ('scaler', StandardScaler())]) categorical_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='constant', fill_value='missing')), ('one_hot', OneHotEncoder())]) preprocessor = ColumnTransformer( transformers=[ ('num', numeric_transformer, numeric_features), ('cat', categorical_transformer, categorical_features) ])pipe = Pipeline(steps=[('preprocessor', preprocessor), ('classifier', LogisticRegression(class_weight='balanced', random_state=0))]) model = pipe.fit(X_train, y_train)
We can inspect the quality of the pipeline by running the below code.
target_names = y_test.unique().astype(str)
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=target_names))

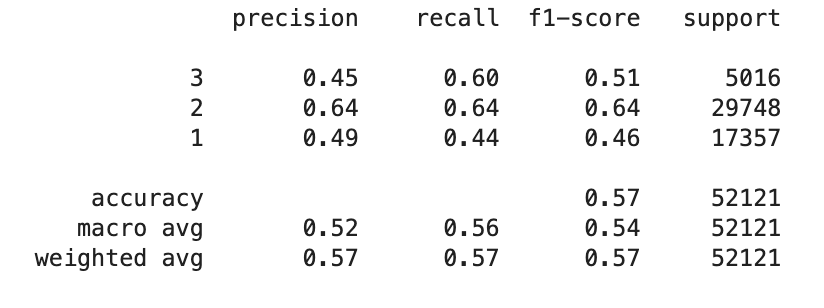
We can see that there is likely to be room for improvement in terms of the performance of the model. One area we would want to explore, besides model selection and hyperparameter optimisation would be feature engineering. However, in order to determine which new features to engineer we first need to have an understanding of which features are most predictive.
ELI5
It is not easy to extract feature importances from this pipeline. However, there is a python library that makes this very simple called ELI5. This library, named after the slang term “explain like I’m 5”, is a package that provides a simple way to explain and interpret machine learning models. It is compatible with most popular machine learning frameworks including scikit-learn, xgboost and keras.
The library can be installed via pip or conda.
pip install eli5conda install -c conda-forge eli5
Let's use ELI5 to extract feature importances from the pipeline.
ELI5 needs to know all feature names in order to construct feature importances. By applying one-hot encoding to the categorical variables in the pipeline we are introducing a number of new features. We therefore first need to extract these feature names and append them to the known list of numerical features. The code below uses the ‘named_steps’ function built into scikit-learn pipelines to do this.
onehot_columns = list(pipe.named_steps['preprocessor'].named_transformers_['cat'].named_steps['one_hot'].get_feature_names(input_features=categorical_features))
numeric_features_list = list(numeric_features)
numeric_features_list.extend(onehot_columns)
To extract the feature importances we then simply need to run this line of code.
eli5.explain_weights(pipe.named_steps['classifier'], top=50, feature_names=numeric_features_list)
Which gives a nicely formatted output.

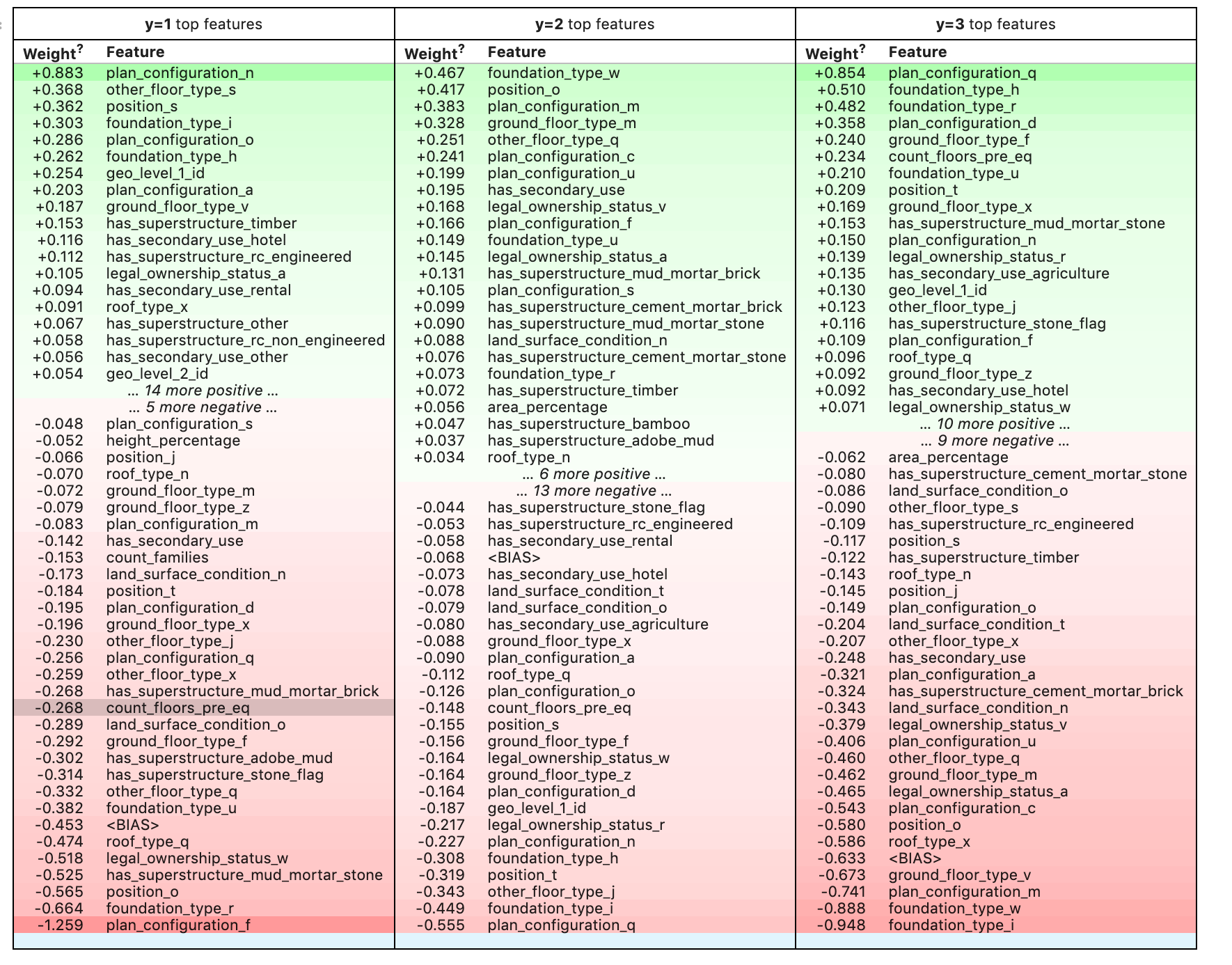
The ELI5 library also provides the ability to explain individual predictions but this is not yet supported for pipelines. In this article, I demonstrated a simple method to extract features importances from a scikit-learn pipeline which provides a good starting point to debug and improve a machine learning model.
Thanks for reading!




No comments:
Post a Comment