An introduction to using Git for machine learning projects
Ihave been using Git for a very long time now. Sometimes I forget that it may be a bit alien to data scientists just starting to learn the basics of how to work with version control. So I decided to write this short guide if you are new to the idea of using the command line to version your machine learning projects and need a simple cheat sheet of the bare minimum commands you should know.
What makes version control so powerful is being able to step back through the history of a proejct, and see the exact changes between the two versions. This is critical when training a new model and you are tuning hyperparameters.
With that in mind, I’m not going to cover how to install Git. There are lots of great resources out there that tell you how to do this. Don’t forget to set up an SSH key as well. Instead, I’m going to assume you have Git installed and are ready to go. You should see the following if you type
git into the command line on Mac/Linux, or GitBash if you are on Windows.

1. Init
We are going to start with the most basic of commands,
init. This will initialize a Git project, which is a fancy way of saying adding the files needed by Git to the root of the folder you are in. Simply cd into your project’s directory and type in the following:git init
In return, you’ll get a message saying that your project is ready to go.


You only have to do this once per project.
2. Remote Add
Right now, thanks to the
init command, you have a local repo for your project. And while you can do everything you need to properly version control your project locally, you’ll want to create a project online to get the most out of Git. The majority of developers have a GitHub account, although there are good alternatives like BitBucket and GitLab. I use GitHub for all of my projects. After Microsoft acquired it, they made private repositories free. But honestly, all of these services are the same for anyone just starting.
After you pick the service, you want to use, go ahead and create a new project.

Once you create your project, you’ll get a custom URL. In this case, the one generated for this project is:
https://github.com/jessefreeman/GitExample.git
All we need to do now is connect our local project to the online one we created. To do this, you’ll use the following command:
git remote add origin <PROJECT_URL>
You can also connect via the SSH path, depending on what your Git service provides you.
3. Add
At this point, your project is ready to track versions locally. Go ahead and add a
ReadMe.txt file or something to the folder. Just keep in mind that Git will ignore empty folders. Once you are ready, you’ll want to add the changes to the repository. Staging is a fancy way of saying that Git is going to track specific files until you are ready to save a version of them.
To add files, just type the following command:
git add .
While you can specify files by name after
add, the . is a wildcard that will automatically include any files that have changed since the last commit.4. Status
At any point, you can get a list of the files in the Git project and see if they are staged or not. To do this, type in the following command:
git status
This will return a list of all the files Git sees in the directory.

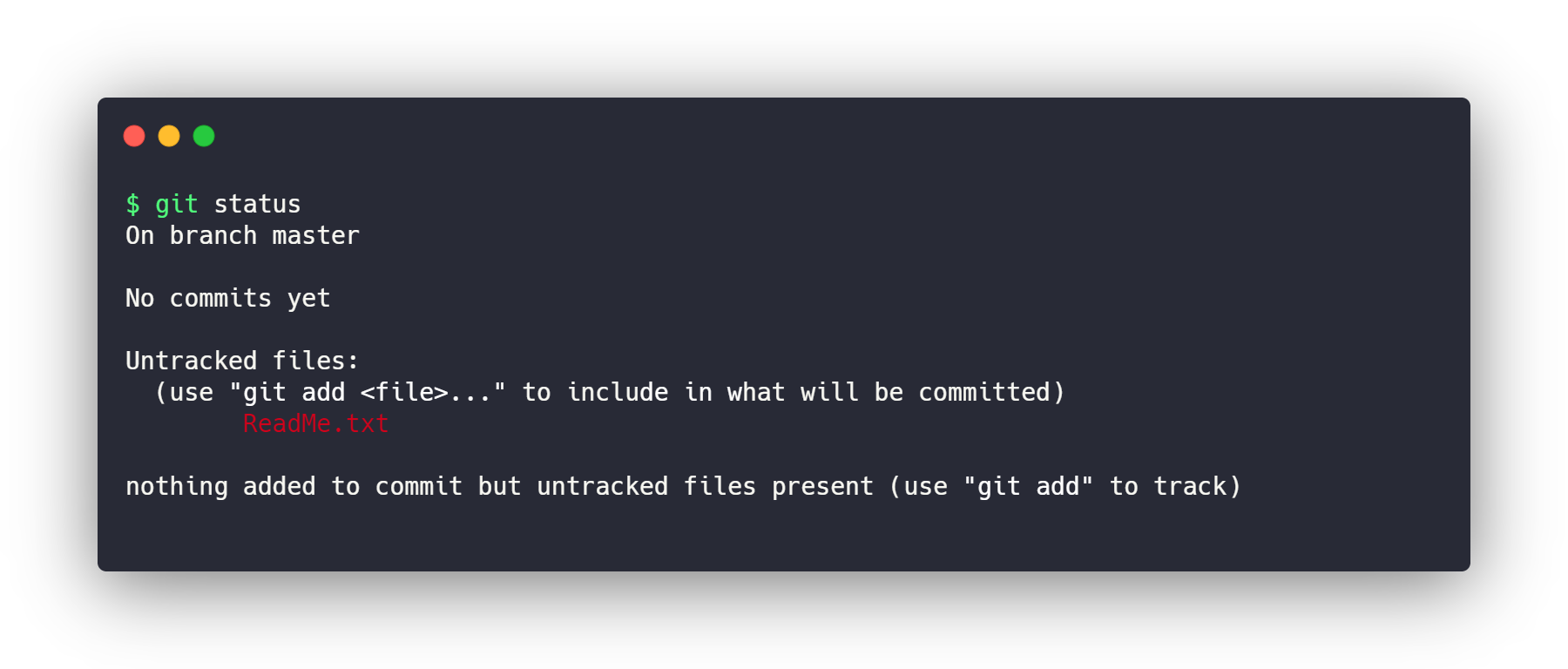
You can see the files not currently added in red. Files that are ready to be saved will show up in green. The file status list is helpful when you want to visually see everything currently staged before saving changes.
5. Commit
Once you’ve staged your files, you’ll want actually to save a version of them. We call this committing. Git will take the files you previously added and compare them to the last version. It then saves the deltas, or the differences, in a special hidden
.gitfolder at the root of your project.
To save the changes, type the following into the command line:
git commit -m "Add a message so you know what you did."
This is probably the most complex of the commands we’ve used so far. If we look at each part, we are calling
commit and the -m stands for adding a message. Finally, you’ll supply the commit message in quotes. This way, you can look back over the commit log later to remember what changes you made.
If you are using GitHub, there are some interesting features you can tap into when committing your code. I use the Issues channel as a way of tracking tasks I need to complete in my project. Each issue has a unique ID number, and you can link to it by referencing it in your comment like this:
git commit -m "Finished making changes to #1."
GitHub will automatically add a link from your commit to the issue. It’s a great way to stay organized while you work.
6. Push
The last step in this process is to push all of your commits to the remote repository on GitHub. Git is unique in that it lets you work locally until you are ready to add them back to the main repository. This is what allows teams to work so efficiently on their computers and then merge everything back to a single project.
Remember, earlier on, when we linked our local project to the online one? Now when you tell Git to
push the changes, they will be copied and merged into the main project. All you need to do is type the following into the command line:git push --all
The
--all is similar to the . wildcard we used earlier when staging our files. This flag tells Git to push all of the recent commits to the default origin, which is what we defined with the remote add command.Rinse and Repeat
Now you know the six most essential commands for using Git:
initCreate a new projectremote add originLink a local project to an online projectaddAdd files to trackstatusReturns a list of files in the local projectcommitSave the changes to those filespushCopy those changes to the online project
Now you can do steps 3–6 to keep saving and pushing changes you make. I tend to commit when I know things are stable. If this is a code project, I only commit when the code works. For writing, I tend to commit at the end of a session. There is no limit to the number of commits you can make, although you may need to clean the Github repo from time to time if you make a lot of changes.
Be sure to check out one of my TextGenRNN projects to can see how I set it up on GitHub. As you get more comfortable using Git, be sure to check out how to use.gitignorefile to exclude specific items you don’t want to be tracked. My project has a one you can use as a reference that ignores the models I generate and some of the python project config files that are not critical for others looking to run the project locally.
Finally, it’s important to note that Git struggles to store large binary files which is another reason to use a
.gitignore file. A lot of your training data like image, videos, or anything over 50 megs could cause an issue. GitHub has a hard limit on large file sizes, and if you accidentally commit one, it will take a few additional steps to undo the changes, especially if you are new to Git or the command line. It’s best to back up those files in a different version control system.
I hope this is helpful if you are new to Git or looking for a quick refresher? I am happy to answer any questions you made have if you leave a comment below.




No comments:
Post a Comment