Overview
It is said that Data Scientist spends 80% of their time in preprocessing the data, so lets deep dive into the data preprocessing pipeline also known as ETL pipeline and let's find out which stage takes the most time. In this blog post, we will learn how to extract data from different data sources. Let's take a real-life dataset so it’s easier to follow.
This lesson uses data from the World Bank. The data comes from two sources:
- World Bank Indicator Data — This data contains socio-economic indicators for countries around the world. A few example indicators include population, arable land, and central government debt.
- World Bank Project Data — This data set contains information about World Bank project lending since 1947.
Types of Data files
- CSV — CSV stands for comma-separated value. This is how the file looks
id,regionname,countryname,prodline,lendinginstr
P162228,Other,World;World,RE,Investment Project Financing
P163962,Africa,Democratic Republic of the Congo;Democratic Republic of the Congo,PE,Investment Projec
Let's load this file using pandas.
import pandas as pd df_projects = pd.read_csv('../data/projects_data.csv')#ERROR: #/opt/conda/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (44) have mixed types. Specify dtype option on import or set low_memory=False.interactivity=interactivity, compiler=compiler, result=result)
We will get a DType warning error. Basically, pandas figure out the data types of our file and read them appropriately but one of our columns had multiple data types thus the warning error. We can pass the data type of the string while reading. Please refer to pandas documentation to read more.
df_projects = pd.read_csv('../data/projects_data.csv',dtype=str)
Output:

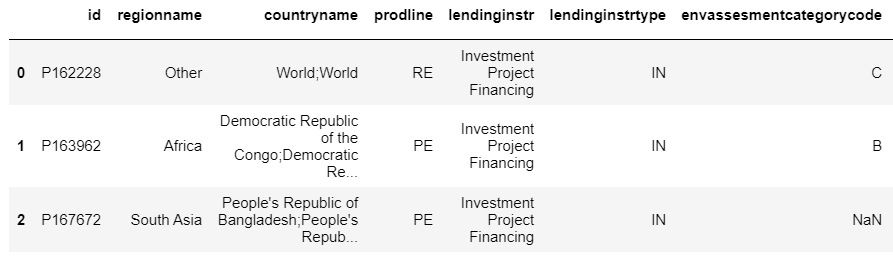
Let’s read another CSV file:
df_population = pd.read_csv("../data/population_data.csv")
# ParserError: Error tokenizing data. C error: Expected 3 fields in line 5, saw 63
Looks like something is wrong with this CSV file. Let’s check the contents. Here, if the file is small you can directly open the CSV file using notepad/excel or you can use the python code below:
with open("../data/population_data.csv") as f: lis = [line.split() for line in f] # create a list of lists #print(lis) for i, x in enumerate(lis): #print the list items print ("line{0} = {1}".format(i, x))#Output:line0 = ['\ufeff"Data', 'Source","World', 'Development', 'Indicators",'] line1 = [] line2 = ['"Last', 'Updated', 'Date","2018-06-28",'] line3 = [] line4 = ['"Country', 'Name","Country', 'Code","Indicator', 'Name","Indicator', 'Code","1960","1961","1962","1963","1964","1965","1966","1967","1968","1969","1970","1971","1972","1973","1974","1975","1976","1977","1978","1979","1980","1981","1982","1983","1984","1985","1986","1987","1988","1989","1990","1991","1992","1993","1994","1995","1996","1997","1998","1999","2000","2001","2002","2003","2004","2005","2006","2007","2008","2009","2010","2011","2012","2013","2014","2015","2016","2017",']
Looks like the first 4 lines of the CSV files are corrupted. So, we can skip the first 4 rows by using skiprows parameter.
df_population = pd.read_csv("../data/population_data.csv",skiprows=4)
Output:

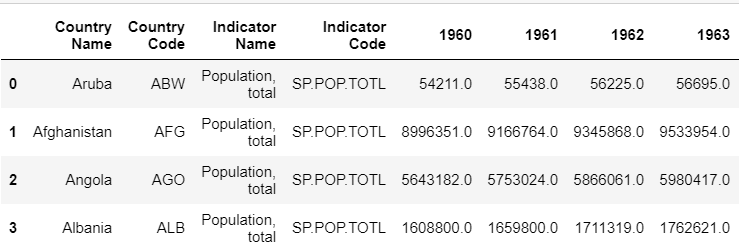
2. JSON — It is a file format with key/value pairs.
[{"id":"P162228","regionname":"Other","countryname":"World;World","prodline":"RE","lendinginstr":"Investment Project Financing"},{"id":"P163962","regionname":"Africa","countryname":"Democratic Republic of the Congo;Democratic Republic of the Congo","prodline":"PE","lendinginstr":"Investment Project Financing"},{"id":"P167672","regionname":"South Asia","countryname":"People\'s Republic of Bangladesh;People\'s Republic of Bangladesh","prodline":"PE","lendinginstr":"Investment Project Financing"}]
Thankfully, pandas have the feature to read JSON directly.
import pandas as pd
df_json = pd.read_json('population_data.json',orient='records')
Other Methods:
import json# read in the JSON file with open('population_data.json') as f: json_data = json.load(f)# print the first record in the JSON file print(json_data[0])
3. XML — Another data format is called XML (Extensible Markup Language). XML is very similar to HTML at least in terms of formatting.
<ENTRY>
<ID>P162228</ID>
<REGIONNAME>Other</REGIONNAME>
<COUNTRYNAME>World;World</COUNTRYNAME>
<PRODLINE>RE</PRODLINE>
<LENDINGINSTR>Investment Project Financing</LENDINGINSTR>
</ENTRY>
<ENTRY>
<ID>P163962</ID>
<REGIONNAME>Africa</REGIONNAME>
<COUNTRYNAME>Democratic Republic of the Congo;Democratic Republic of the Congo</COUNTRYNAME>
<PRODLINE>PE</PRODLINE>
<LENDINGINSTR>Investment Project Financing</LENDINGINSTR>
</ENTRY>
There is a Python library called BeautifulSoup, which makes reading in and parsing XML data easier. Here is the link to the documentation: Beautiful Soup Documentation
# import the BeautifulSoup library from bs4 import BeautifulSoup# open the population_data.xml file and load into Beautiful Soup with open("population_data.xml") as fp: soup = BeautifulSoup(fp, "lxml") # lxml is the Parser type
Let’s see what soup looks like:
<html><body><p><?xml version="1.0" encoding="utf-8"?>
<root xmlns:wb="http://www.worldbank.org">
<data>
<record>
<field key="ABW" name="Country or Area">Aruba</field>
<field key="SP.POP.TOTL" name="Item">Population, total</field>
<field name="Year">1960</field>
<field name="Value">54211</field>
</record>
<record>
<field key="ABW" name="Country or Area">Aruba</field>
<field key="SP.POP.TOTL" name="Item">Population, total</field>
<field name="Year">1961</field>
<field name="Value">55438</field>
</record>
How to read XML as a data frame?
data_dictionary = {'Country or Area':[], 'Year':[], 'Item':[], 'Value':[]}for record in soup.find_all('record'): for record in record.find_all('field'): data_dictionary[record['name']].append(record.text)df = pd.DataFrame.from_dict(data_dictionary) df = df.pivot(index='Country or Area', columns='Year', values='Value')df.reset_index(level=0, inplace=True)
Basically, we need to make a dictionary for each column or for each row and then convert the dictionary to dataframe.
Output:

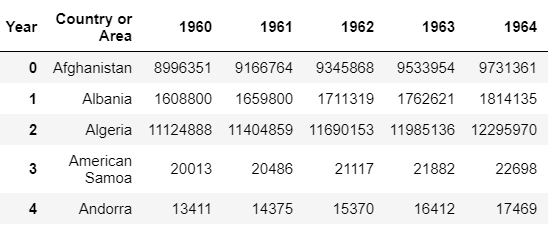
4. SQL — SQL databases store data in tables using primary and foreign keys
To read data from the SQL database, you need to have your data stored in the database. To know how to Convert CSV to SQL DB read this blog.
SQLite3 to Pandas
import sqlite3 import pandas as pd# connect to the database conn = sqlite3.connect('population_data.db')# run a query pd.read_sql('SELECT * FROM population_data', conn)
SQLAlchemy to Pandas
import pandas as pd from sqlalchemy import create_engineengine=create_engine('sqlite:////home/workspace/3_sql_exercise/population_data.db') pd.read_sql("SELECT * FROM population_data", engine)
5. API — Extracting data from the Web is a very tiring process. But a lot of companies have made their data public through API. APIs generally provide data in either JSON or XML format. Some APIs are public where you do not need to log in whereas some are private, where users need to generate an API key.
import requests import pandas as pdurl = 'http://api.worldbank.org/v2/countries/br;cn;us;de/indicators/SP.POP.TOTL/?format=json&per_page=1000' r = requests.get(url) r.json()
API calls are different for different websites, here we are using requests library to get the data in a JSON format. Read more about different API structures here




No comments:
Post a Comment