Welcome to our latest exploration into SQL for Data Science. In our previous articles, we have delved into the manipulation of datasets within the confines of a single table, exploring data extraction, transformation, calculations, and filtering to unveil insights and patterns.
While these foundational skills are crucial, the real-world application of SQL often demands a more complex approach, particularly the integration of data from multiple tables. This is a reflection of how data is typically stored in relational databases, segmented into various tables that relate to each other through specific keys and attributes.
In this article, we will venture beyond the single-table operations and embark on understanding and applying multi-table joins. Join operations are pivotal in SQL, allowing us to consolidate and cross-reference data from different tables to construct a comprehensive view of the information at hand.
We will cover the fundamental concepts of join operations, including the various types of joins and their applications. By the end of this piece, you will be equipped with the practical know-how to perform sophisticated data manipulations that mirror the complexities of real-world data science challenges. Let’s dive into the intricacies of multi-table relations and unveil the strategies to navigate and harness the full potential of relational databases for data science.
Understanding Data Relationships
At the core of our exploration into table joins and SQL lies a fundamental concept: data relationships. Before we dive deep into the mechanics of joining tables, it’s crucial to grasp what it means for data to be related and how these relationships form the backbone of relational databases.
Consider a basic example that’s commonplace in virtually any business that sells products — a product catalog table. This table is an essential component of a company’s database, providing a structured overview of the products available for sale. It typically includes fields such as product code, product name, sale price, and product category. Each of these fields serves a specific purpose:
- Product Code: A unique identifier for each product.
- Product Name: The name of the product, which helps users identify it.
- Sale Price: The price at which the product is sold to customers.
- Product Category: A classification that groups products into broader categories.
This table not only helps in organizing product information in a manageable way but also sets the stage for understanding how data can be interconnected.
For instance, the product category field links individual products to a larger category, hinting at a simple yet powerful relationship within the data. As we progress, we’ll see how such relationships extend beyond single tables, enabling us to combine data from multiple sources to provide richer insights and more comprehensive analyses.
In the upcoming sections, we’ll delve into the mechanics of table joins, a technique that leverages these relationships to merge data from two or more tables, enriching our ability to query and analyze data.
By understanding the foundational concept of data relationships, you’ll be better equipped to appreciate the power of SQL in data science.

In terms of query analysis and the generation of visualizations, the PRODUCTS table seems to be well-structured and suitable for SQL operations.
To retrieve the names of products from the PRODUCTS table where the category is specifically `Home Appliances', we could execute a SQL query like this:
SELECT product_name
FROM PRODUCTS
WHERE category = 'Home Appliances'In our example table, executing this query would return three rows, indicating that we have three products within the ‘Home Appliances’ category.
Thus, there are no issues with fetching this subset of data. Furthermore, we could extend our analysis to calculate the average value of products per category.
For such an operation, we would use the AVG function to compute the average product value. This is how we might structure the SQL command:
SELECT category, AVG(product_value)
FROM PRODUCTS
GROUP BY category;This command accomplishes two tasks:
- It selects the
categorycolumn to be included in the output, providing a distinct identifier for each category's average value. - It calculates the average
product_valueusing theAVGfunction, an aggregate function that will be explored more in-depth in our next chapter.
By using GROUP BY category, we ensure the average value is computed for each unique category within the PRODUCTS table. Such aggregation is key to data analysis, enabling the identification of patterns and trends within different product segments.
Upon closer examination, however, the category column reveals an inefficiency: the term 'Home Appliances' is repeated multiple times. While at first glance it may seem necessary to represent each product's category, this redundancy can lead to several issues:
- Data Storage: Redundant data can be costly in terms of storage. Each repetition of ‘Home Appliances’ occupies additional space on the disk, which is unnecessary, especially if there’s a more efficient method to represent this information.
- Performance: A table that’s frequently updated will take longer to load if it contains such redundancies. Imagine this table scaled to millions or billions of records; the impact on performance could be significant due to the repeated category entries.
- Query Efficiency: When querying large tables, the presence of repeated categories can result in increased computational time, as the database engine needs to scan through more data than necessary.
So, while the table may seem sufficient for reporting purposes, the management and operational aspects reveal substantial inefficiencies.
Addressing these challenges requires a solution known as normalization, which involves restructuring the database to reduce redundancy and improve data integrity.
One common approach to resolving this issue is to create a separate CATEGORIES table that holds unique category names and their associated identifiers.
Each product in the PRODUCTS table would then reference the appropriate category by an identifier, a method known as foreign key reference.
This change not only saves storage space but also optimizes the performance for data operations and queries.
Here’s an example of how we could restructure our database to address these inefficiencies:
-- Create a new table for categories
CREATE TABLE CATEGORIES (
category_id INT PRIMARY KEY,
category_name VARCHAR(255)
);
-- Insert unique categories into the CATEGORIES table
INSERT INTO CATEGORIES (category_id, category_name)
VALUES (1, 'Home Appliances'), (2, 'Furniture'), (3, 'Food');
-- Modify the PRODUCTS table to include a foreign key reference to CATEGORIES
ALTER TABLE PRODUCTS
ADD COLUMN category_id INT,
ADD FOREIGN KEY (category_id) REFERENCES CATEGORIES(category_id);This approach resolves several issues: there’s no longer a repetition of the word ‘Home Appliances’, which is significant in a table with billions of records.
The loading time is likely reduced, as the CATEGORIES table doesn’t need to be loaded frequently; it's created once and undergoes few changes over time. The PRODUCTS table becomes faster to load and update, as there’s no need to repeat category-related text.
Querying will involve a bit more complexity as it requires joining the two tables. However, this trade-off is beneficial since queries can be more performatic by referencing an ID instead of a text-based category column, and then joining to the CATEGORIES table where the category isn't repeated.
Here’s an example of how a query would look to retrieve product names where the category is ‘Home Appliances’:
SELECT p.product_name, p.product_value
FROM PRODUCTS p
JOIN CATEGORIES c ON p.category_id = c.category_id
WHERE c.category_name = 'Home Appliances';This SQL statement joins the PRODUCTS table with the CATEGORIES table based on their shared category_id. By doing so, it efficiently retrieves the product names and values associated with the 'Home Appliances' category.
pandcare aliases forPRODUCTSandCATEGORIES, respectively, simplifying our query.- The
ONclause links the two tables by matchingcategory_id. - The
WHEREclause filters the results to only include 'Home Appliances'.
Column names without table aliases are from columns unique to one table, removing the need for aliases. However, standard practice is to use aliases for clarity, especially as queries grow in complexity.
We’ll explore various types of joins such as LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN, and CROSS JOIN in upcoming sections.
Understanding SQL Joins: A Conceptual Approach
In the realm of SQL, the ability to join tables is a powerful feature that enables complex data retrieval.
Before we begin, a word of advice: while it may be tempting, resist the urge to memorize join rules. True comprehension comes from understanding the underlying principles, not rote memorization.
In this section, we’ll present an overview of SQL joins, supplemented by diagrams to grasp the general concepts. As we move into practical exercises, we’ll emphasize a goal-oriented approach to learning SQL joins.
The key to mastering joins is to focus on the desired outcome: What data do you need? How much data is required? From which tables?
These questions will guide you to the appropriate join type, regardless of its name.

A join is essentially a set theory rule in action, and understanding this concept is more strategic than simple memorization.
Nonetheless, this is just one perspective. You’re encouraged to draw your own conclusions as we explore the various join types, including INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN, and more, in the upcoming lessons.
SQL joins are, in essence, the practical application of set theory — a concept most are introduced to in early education. This idea is simple: joins allow us to retrieve data that belongs to one set, another, or both. In SQL, these sets are tables containing our data.
Consider this visualization: each circle represents a dataset, or a table. We can retrieve data:
Inner Join
If you hear about a “join,” it’s likely referring to the Inner Join, the most commonly used type of join. It returns records that have matching values in both tables. Below, a diagram aids in understanding.
Left Join (or Left Outer Join)
Sometimes referred to simply as “Left Join” (omitting “Outer”), it returns all records from the left table and the corresponding records from the right table. The sequence of tables in your SQL query significantly affects the results, highlighting the importance of table order in queries.
Right Join (or Right Outer Join)
This join returns all records from the right table and the matching records from the left table. A diagram below illustrates this concept.
Full Join (or Full Outer Join)
It returns all records when there is a match in the left, the right, or both tables, essentially retrieving everything.
Cross Join
Less commonly used due to performance issues, it returns a Cartesian product of all records from both tables.
It’s important to note that while these examples use two tables for simplicity, the same principles apply regardless of the number of tables involved. The logic remains consistent whether you’re joining three, four, five, or even a million tables.
Self Join
This technique involves joining a table to itself, employing recursion, a concept widely used in computer programming.
The subsequent diagram summarizes the explanations provided.

This summary encapsulates the types of joins just discussed, yet it’s essential to note that each join type has its nuances, mainly in how you organize filters in your query.
We’ve explored filters in previously, remember? Filters are indeed the cornerstone of any SQL concept.
The way you construct a join can be completely altered based on the filters you apply. So, while I’ve introduced you to these joins and their slight variations, I personally don’t bother memorizing the names of joins.
Instead, I focus on understanding what I need:
- Do I want to return data from both the left and right tables?
- Am I looking to retrieve data present in one table but absent in the other?
- Or am I interested in returning data where the relationship exists within the same table?
These are the questions I ponder, and they will guide you through our practical lessons. This approach helps define the best joining strategy. Of course, grasping all this might not come instantly; practice is key.
I will provide numerous examples in the coming sessions to reinforce your understanding and application of these concepts.
Exploring Table Joins in SQL
We will delve into table joins in SQL. This section emphasizes this subject, intending to clarify it thoroughly, step by step, from the basics in the most didactic manner possible.
My goal is for you to clearly understand the concept, as table joins will be utilized in subsequent chapters when we tackle increasingly complex queries.
Let’s start by preparing and loading the data, working with fictional datasets to ease our journey into mastering SQL joins.
CREATE SCHEMA `chapter04` ;First, I’ll load the table with some fictional data, then proceed to create a second table, load it as well, and follow up with a third table before applying data loads.
Although it’s possible to right-click and select “Create Schema” in the interface, I’m providing all the commands in a single script for execution. Once executed, you’ll see a success message in the log.
Then, by right-clicking and refreshing in the left sidebar, the “Chapter 04” schema will appear.
Creating a Customers Table
Copy and paste the following DDL (Data Definition Language) instruction in SQL to create the customers table:
CREATE TABLE `chapter04`.`CUSTOMERS` (
`customer_id` INT NULL,
`customer_name` VARCHAR(50) NULL,
`customer_address` VARCHAR(50) NULL,
`customer_city` VARCHAR(50) NULL,
`customer_state` VARCHAR(2) NULL);The ultimate goal of this section is to create objects within the database. Thus, creating a CUSTOMERS table is a DDL (Data Definition Language) instruction.
DDL is used when we aim to create something in the database, such as a table. In this case, we’re creating the CUSTOMERS table in the chapter04 schema, which will include columns for customer ID, customer name, customer address, city, and state.
Let’s proceed to execute this. Upon successful execution, you’ll see a confirmation in the log. Click on the arrow, then on the ‘Tables’ section, and you’ll see our first table has been created. Now, it’s time to populate this table with fictional data using INSERT statements.
Populating the CUSTOMERS Table
To add data to our CUSTOMERS table, we utilize the INSERT INTO statement, a key component of the Data Manipulation Language (DML) designed for adding new records to a table.
Here's how to systematically insert fictional customer data:
-- Inserting data into CUSTOMERS table
INSERT INTO `chapter04`.`CUSTOMERS`
(`customer_id`, `customer_name`, `customer_address`, `customer_city`, `customer_state`)
VALUES
(1, 'John Smith', '123 Maple Street', 'Orlando', 'FL');
INSERT INTO `chapter04`.`CUSTOMERS`
(`customer_id`, `customer_name`, `customer_address`, `customer_city`, `customer_state`)
VALUES
(2, 'Susan Johnson', '456 Oak Avenue', 'Austin', 'TX');
INSERT INTO `chapter04`.`CUSTOMERS`
(`customer_id`, `customer_name`, `customer_address`, `customer_city`, `customer_state`)
VALUES
(3, 'Robert Brown', '789 Pine Lane', 'Phoenix', 'AZ');
INSERT INTO `chapter04`.`CUSTOMERS`
(`customer_id`, `customer_name`, `customer_address`, `customer_city`, `customer_state`)
VALUES
(4, 'Linda Davis', '321 Birch Blvd', 'Raleigh', 'NC');
INSERT INTO `chapter04`.`CUSTOMERS`
(`customer_id`, `customer_name`, `customer_address`, `customer_city`, `customer_state`)
VALUES
(5, 'Michael Miller', '654 Cedar Place', 'Atlanta', 'GA');Each INSERT INTO command adds a new row to the CUSTOMERS table, specifying values for customer_id, customer_name, customer_address, customer_city, and customer_state.
This methodically populates the table with diverse entries, setting a foundation for our SQL queries and operations.
After executing these commands, the CUSTOMERS table will be filled with these sample records, facilitating our exploration of SQL functions and table joins in subsequent lessons.
Creating and Populating the ORDERS Table
After establishing the CUSTOMERS table, the next step involves setting up the ORDERS table within the same chapter04 schema.
This table records various details about customer orders, including the salesperson involved and delivery details. Here's how to create the ORDERS table:
CREATE TABLE `chapter04`.`ORDERS` (
`order_id` INT NULL,
`customer_id` INT NULL,
`salesperson_id` INT NULL,
`order_date` DATETIME NULL,
`delivery_id` INT NULL);This table schema includes:
order_id: The unique identifier for each order.customer_id: A reference to the customer who placed the order, linking back to theCUSTOMERStable.salesperson_id: The identifier for the salesperson who handled the order.order_date: The date and time when the order was placed, using the DATETIME format. This is important to note, as the DATETIME format allows for the precise timing of orders to be recorded.delivery_id: An identifier for the delivery details associated with the order.
Once you execute this command to create the ORDERS table, refresh your schema view in MySQL Workbench (or your SQL management tool of choice) to see the newly created table under the chapter04 schema.
Next, we will proceed to populate this ORDERS table with data, ensuring to pay attention to the order_date column's DATETIME format as we insert records.
Populating the ORDERS Table with Current Data
To populate the ORDERS table, we're utilizing the INSERT INTO statement to add records.
This includes specifying each order's unique ID, customer ID, salesperson ID, the current date and time of the order, and the delivery ID.
Here's how we use the SQL NOW() function to capture the exact current date and time for the order_date column, which is of the DATETIME type:
INSERT INTO `chapter04`.`ORDERS` (`order_id`, `customer_id`, `salesperson_id`, `order_date`, `delivery_id`)
VALUES (1001, 1, 5, now(), 23);
INSERT INTO `chapter04`.`ORDERS` (`order_id`, `customer_id`, `salesperson_id`, `order_date`, `delivery_id`)
VALUES (1002, 1, 7, now(), 24);
INSERT INTO `chapter04`.`ORDERS` (`order_id`, `customer_id`, `salesperson_id`, `order_date`, `delivery_id`)
VALUES (1003, 2, 5, now(), 23);The NOW() function is a convenient feature in SQL that retrieves the current date and time from the system where the database server is running, ensuring that the order_date column is accurately timestamped at the moment of data insertion.
After executing these commands, each record is timestamped with the precise moment of insertion, showcasing the utility of the NOW() function for current date and time entries.
SQL functionalities can vary slightly across different database management systems (DBMS), and it's essential to consult the specific documentation for the SQL dialect you are using, whether it's MySQL, PostgreSQL, or others, to understand their unique functions and syntax.
This step not only demonstrates how to insert data into a database but also highlights the importance of familiarizing oneself with the various SQL functions and their applications in different DBMS environments.
Next, we’ll review the inserted data by executing a SELECT query and then proceed to create and populate the third and final table.
Creating and Populating the SALESPERSON Table
Next in our SQL journey, we focus on setting up the SALESPERSON table. This table is designed to store information about salespersons, including their IDs and names. Here's the SQL command to create the SALESPERSON table:
CREATE TABLE `chapter04`.`SALESPERSON` (
`salesperson_id` INT NULL,
`salesperson_name` VARCHAR(50) NULL);After executing this command, the SALESPERSON table is established, ready to be populated with data about salespersons.
Populating the SALESPERSON Table
To insert data into the SALESPERSON table, we use the INSERT INTO statement for each salesperson record.
While the specific INSERT commands are not detailed in your prompt, the general form of such commands would look like this:
INSERT INTO `chapter04`.`SALESPERSON` (`salesperson_id`, `salesperson_name`)
VALUES (1, "Salesperson 1");
INSERT INTO `chapter04`.`SALESPERSON` (`salesperson_id`, `salesperson_name`)
VALUES (2, "Salesperson 2");
INSERT INTO `chapter04`.`SALESPERSON` (`salesperson_id`, `salesperson_name`)
VALUES (3, "Salesperson 3");
INSERT INTO `chapter04`.`SALESPERSON` (`salesperson_id`, `salesperson_name`)
VALUES (4, "Salesperson 4");
INSERT INTO `chapter04`.`SALESPERSON` (`salesperson_id`, `salesperson_name`)
VALUES (5, "Salesperson 5");
INSERT INTO `chapter04`.`SALESPERSON` (`salesperson_id`, `salesperson_name`)
VALUES (6, "Salesperson 6");
INSERT INTO `chapter04`.`SALESPERSON` (`salesperson_id`, `salesperson_name`)
VALUES (7, "Salesperson 7");Retrieving Order ID and Customer Name
Given that the customer name resides in the CUSTOMERS table and the order ID in the ORDERS table, we're faced with the need to extract data across two distinct tables.
This scenario perfectly illustrates the necessity of table joins in SQL, allowing us to form relationships between tables to retrieve combined data.
Given that each order is linked to a specific customer — evidenced by the customer ID in the ORDERS table—it's clear that a relational column exists between the two tables.
This connection is not arbitrary; it's a deliberate aspect of database design, indicating that orders are inherently tied to customers. In practical terms, an order cannot exist without an associated customer, a logical rule established during the database modeling phase.
This is why the customer ID typically serves as a primary key; it uniquely identifies each customer, ensuring no two customers have the same ID, much like individuals have unique identification numbers.
To fetch the required information, we’ll execute an Inner Join between the ORDERS and CUSTOMERS tables. Here's how you can structure this query:
SELECT o.order_id, c.customer_name
FROM `chapter04`.`ORDERS` o
INNER JOIN `chapter04`.`CUSTOMERS` c
ON o.customer_id = c.customer_id;oandcare aliases for theORDERSandCUSTOMERStables, respectively, simplifying our notation.- The
SELECTstatement specifies that we're fetching theorder_idfrom the orders table (o) and thecustomer_namefrom the customers table (c). - The
INNER JOINclause connects the two tables on their commoncustomer_idcolumn, ensuring that only orders with a corresponding customer record are retrieved.
This approach demonstrates the power of Inner Joins in SQL for combining data from multiple tables based on a shared relationship, enabling us to compile comprehensive data sets for analysis or reporting purposes.
SELECT o.order_id, c.customer_name
FROM ORDERS o
INNER JOIN `chapter04`.`CUSTOMERS` c ON o.customer_id = c.customer_id;This query will return the IDs of the orders along with the names of the customers who made those orders by performing an inner join between the orders and customers tables on the common customer_id field.
Using aliases in SQL queries, such as ‘p’ for the ORDERS table and 'c' for the CUSTOMERS table, simplifies the syntax.
For instance, to retrieve order IDs and customer names, you could use an INNER JOIN to link these tables based on a common column, like customer_id.
SELECT p.order_id, c.customer_name
FROM ORDERS p
INNER JOIN CUSTOMERS c ON p.customer_id = c.customer_id;This query employs the WHERE clause as an alternative to the INNER JOIN syntax for connecting two tables, effectively matching orders with customers by customer_id.
I’ve demonstrated how INNER JOIN, widely used for its ability to return data where a clear relationship exists, avoids orphaned records. Instead of using INNER JOIN, direct column comparison with the WHERE clause can achieve the same result.
Placing the two queries side by side clarifies the difference. Executing both yields identical results, underscoring INNER JOIN’s role in intersecting set theory — a concept introduced in elementary education.
The choice between using INNER JOIN or WHERE for table joining is personal. Some might prefer WHERE for its straightforward table linkage, aligning with the mindset of direct connection understanding. However, syntax awareness is crucial as it varies slightly between the two methods.
# Return order ID, customer's name, and salesperson's name
# Inner Join with 3 tables
SELECT O.order_id, C.customer_name, S.salesperson_name
FROM chapter04.ORDERS AS O
INNER JOIN chapter04.CUSTOMERS AS C ON O.customer_id = C.customer_id
INNER JOIN chapter04.SALESPERSON AS S ON O.salesperson_id = S.salesperson_id;This query executes an inner join on three tables: ORDERS, CUSTOMERS, and SALESPERSONS, retrieving the order ID, customer name, and salesperson name for each order.
It starts with the ORDERS table, joins it with CUSTOMERS by matching the customer_id, and then performs another join with SALESPERSONS on salesperson_id.
The query aims to intersect data, limiting the results to the smallest set of related records across the tables, in this case, returning three orders and their associated customers and salespersons.
This approach, while precise, could also be adapted to alternative methods without using INNER JOIN, potentially simplifying understanding.
SELECT O.order_id, C.customer_name, S.salesperson_name
FROM chapter04.ORDERS AS O,
chapter04.CUSTOMERS AS C,
chapter04.SALESPERSON AS S
WHERE O.customer_id = C.customer_id
AND O.salesperson_id = S.salesperson_id;This query joins the ORDERS, CUSTOMERS, and SALESPERSON tables by matching customer_id and salesperson_id using a WHERE clause, retrieving order ID, customer name, and salesperson name without needing parentheses for separation.
The approach simplifies understanding by directly comparing IDs, showcasing a straightforward way to perform an INNER JOIN for three tables—a logic extendable to multiple tables by establishing necessary data relationships.
This method, while demonstrating one of the most common table joining techniques, hints at the variety of joins to be explored further in the course.
Delving Deeper into INNER JOIN Usage and Syntax
Let’s delve deeper into INNER JOIN, the most common join type, which can be combined with SQL clauses like WHERE, ORDER BY, GROUP BY, among others.
# Inner Join - ANSI Standard
SELECT O.order_id, C.customer_name
FROM chapter04.ORDERS AS O
JOIN chapter04.CUSTOMERS AS C ON O.customer_id = C.customer_id;This query demonstrates the ANSI standard INNER JOIN used in previously, a universally supported format across database management systems (DBMS) adhering to the ANSI standard.
Nearly all modern DBMS support this standard, ensuring compatibility. Interestingly, omitting INNER and using just JOIN yields the same result, indicating that JOIN alone defaults to an INNER JOIN.
However, for LEFT JOIN or RIGHT JOIN, the specific keywords “left” or “right” must be explicitly used
Simplifying INNER JOIN with USING Clause
When joining tables with columns of the same name, the USING clause offers a streamlined approach. Instead of specifying each table's column in an ON clause, USING directly identifies the common column for the join. This method enhances code readability, crucial not only in SQL but in all programming practices. Maintaining clear and understandable code facilitates future reviews or modifications, whether by you or others.
Here’s how to apply INNER JOIN with USING for columns with identical names across tables, followed by filtering and sorting results:
# Inner Join with WHERE and ORDER BY
SELECT O.order_id, C.customer_name
FROM chapter04.ORDERS AS O
INNER JOIN chapter04.CUSTOMERS AS C USING (customer_id)
WHERE C.customer_name LIKE 'Bob%'
ORDER BY O.order_id DESC;The query focuses on extracting orders and customer names, specifically targeting customers named “Bob” and sorting the results in descending order based on the order ID.
By utilizing the customer_id for table relationships, the query adeptly filters data using the LIKE operator — signifying approximate matches — to capture any name starting with “Bob.”
This methodical approach underscores the adaptability and depth of INNER JOIN in SQL, which, when combined with other clauses, significantly broadens the scope of data analysis.
It exemplifies how queries can evolve into more intricate forms, such as joining multiple tables, applying filters, and executing sorts or groupings, promising even more sophisticated data manipulation techniques in subsequent chapters.
Exploring LEFT JOIN in SQL
After delving into INNER JOIN, we now turn our attention to LEFT JOIN.
This type of join allows for a broader understanding of table relationships by including all records from the left table, regardless of whether there are matching entries in the right table.
This approach ensures a comprehensive grasp of the concept, transitioning smoothly from theory to practical SQL code implementation.
# Inner Join with WHERE and ORDER BY
SELECT O.order_id, C.customer_name
FROM chapter04.ORDERS AS O
INNER JOIN chapter04.CUSTOMERS AS C USING (customer_id)
WHERE C.customer_name LIKE 'Bob%'
ORDER BY O.order_id DESC;Utilizing LEFT JOIN for Data Retrieval
In MySQL Workbench, a scenario with INNER JOIN aimed to fetch order IDs and customer names.
However, recognizing that some customers might not have placed orders yet, we seek a query that includes all customers, irrespective of their order status. INNER JOIN falls short for this purpose, as it only returns customers with orders.
To address this, LEFT JOIN becomes the tool of choice, allowing us to retrieve all customers from the left table, even those without matching entries in the right table, thus providing a complete dataset for reports or managerial insights.
# Left Join – indicates we want all data from the left table even without a corresponding match in the right table
SELECT C.customer_name, O.order_id
FROM chapter04.CUSTOMERS AS C
LEFT JOIN chapter04.ORDERS AS O ON C.customer_id = O.customer_id;The Impact of Query Order with LEFT JOIN
The sequence of tables in a query significantly affects the outcome.
Demonstrating this, a query was set up to fetch customer names and order IDs, using aliases ‘C’ for CUSTOMERS and ‘P’ for CORDERS.
By executing a LEFT JOIN, the aim to include all customers, with or without associated orders, was achieved. This technique highlighted customers who have made orders and represented those without any as NULL.
Adjustments, like using a CASE statement to replace NULL with a descriptive value, could further refine the output. Ultimately, using LEFT JOIN (or LEFT OUTER JOIN, interchangeably) ensures that all entries from the left table are returned, maintaining data integrity regardless of matching records in the right table.
SELECT C.customer_name, O.order_id
FROM chapter04.CUSTOMERS AS C
LEFT OUTER JOIN chapter04.ORDERS AS O
ON C.customer_id = O.customer_id;LEFT JOIN vs. LEFT OUTER JOIN
Using LEFT OUTER JOIN yields the same results as LEFT JOIN, highlighting their interchangeability in SQL. However, removing “LEFT” fundamentally changes the query’s behavior, as it defaults to an INNER JOIN, focusing only on matching records.
This distinction underscores the importance of specifying “LEFT” to include all records from the left table, even those without matches in the right table.
The option to use OUTER is a matter of preference, often omitted for simplicity. Experimenting with table order in queries can offer further insights, encouraging testing to fully grasp the effects of such adjustments on query outcomes.
# If we reverse the order of the tables the result is different
SELECT C.customer_name, O.order_id
FROM chapter04.ORDERS AS P
LEFT JOIN chapter04.CUSTOMERS AS C
ON C.customer_id = P.customer_id;Impact of Table Order in LEFT JOIN Queries
Executing a LEFT JOIN query, as shown, correctly returns all customers, whether they’ve placed orders or not.
Reversing the table order while keeping the LEFT JOIN, however, alters the outcome significantly, resembling an INNER JOIN’s behavior.
This demonstrates the crucial influence of table sequence when using LEFT or RIGHT JOINs, where the direction (left or right) specifies which table’s records are to be fully included in the results.
The upcoming lesson will delve further into this concept by exploring RIGHT JOIN, enhancing our understanding of SQL join operations and their dependencies on table order.
Solving Table Order Issues with RIGHT JOIN
In the previous video, we explored LEFT JOIN to include all customers, with or without orders. Flipping the table order resulted in behavior akin to an INNER JOIN.
To address this without reordering tables, RIGHT JOIN is the solution. It ensures all entries from the right table (in this case, CUSTOMERS) are included, even if there's no match in the left table (ORDERS). This approach effectively reverses the initial LEFT JOIN strategy by focusing on the right table for comprehensive data retrieval.
# Right Join – indicates we want all data from the right table even without a corresponding match in the left table
SELECT C.customer_name, O.order_id
FROM chapter04.ORDERS AS P
RIGHT JOIN chapter04.CUSTOMERS AS C
ON C.customer_id = P.customer_id;Optimizing JOIN Strategy with a Standard Approach
Adjusting table order can be cumbersome, leading to a preference for consistently using LEFT JOIN for desired outcomes, such as comprehensive reports.
This personal strategy establishes a uniform pattern, simplifying query execution and enhancing learning and recall. Adopting such standards in daily operations aids in quickly grasping and applying SQL concepts, making LEFT or RIGHT JOIN selection dependent on table position and the requirement to include all data, associated or not.
This methodical approach underscores the importance of consistency in SQL practices for efficient and effective data retrieval.
Crafting a Query for Comprehensive Data Analysis
The task is to create a query that returns the order date, customer name, and all salespersons, regardless of their association with orders, sorted by the customer’s name.
Determining whether to use LEFT JOIN, RIGHT JOIN, or INNER JOIN depends on the specific data retrieval goal, underscoring the importance of problem-solving in learning. Here’s how to approach this:
# Retrieve order date, customer's name, and all salespersons, sorted by customer name
SELECT O.order_date, C.customer_name, S.salesperson_name
FROM chapter04.ORDERS AS O
JOIN chapter04.CUSTOMERS AS C ON O.customer_id = C.customer_id
RIGHT JOIN chapter04.SALESPERSON AS S ON O.salesperson_id = S.salesperson_id
ORDER BY C.customer_name;This solution demonstrates the necessity of selecting the appropriate join type based on the requirement to include all relevant data — here, ensuring every salesperson is listed, with or without linked orders, and organizing the output by customer name.
Such queries highlight the strategic aspect of SQL in addressing business needs through precise data querying techniques.
This query will give you the order date and customer name for all orders, and include all salespersons, whether or not they have associated orders, sorting the results by the customer’s name. If a salesperson does not have an associated order, the order date and customer name fields will be NULL in the result.
# Return the order date, customer's name, all salespersons, with or without an associated order, and order the result by the customer's name.
SELECT
CASE
WHEN O.order_date IS NULL THEN 'No Order'
ELSE O.order_date
END AS order_date,
CASE
WHEN C.customer_name IS NULL THEN 'No Order'
ELSE C.customer_name
END AS customer_name,
S.salesperson_name
FROM chapter04.ORDERS AS O
JOIN chapter04.CUSTOMERS AS C ON O.customer_id = C.customer_id
RIGHT JOIN chapter04.SALESPERSON AS S ON O.salesperson_id = S.salesperson_id
ORDER BY C.customer_name;Enhancing Results with Conditional Formatting
By employing conditional logic with the CASE statement, it ensures no null values are presented in the report.
Instead, missing order dates or customer names are labeled as ‘No Order’, enhancing clarity and utility for executive review.
The query is meticulously structured to order results by customer name, facilitating an organized and informative output suitable for further analysis or presentation.
SELECT
CASE
WHEN O.order_date IS NULL THEN 'No Order'
ELSE O.order_date
END AS order_date,
CASE
WHEN C.customer_name IS NULL THEN 'No Order'
ELSE C.customer_name
END AS customer_name,
S.salesperson_name
FROM chapter04.ORDERS AS O
RIGHT JOIN chapter04.CUSTOMERS AS C ON O.customer_id = C.customer_id
RIGHT JOIN chapter04.SALESPERSON AS S ON O.salesperson_id = S.salesperson_id
ORDER BY C.customer_name;This approach not only addresses the immediate need for comprehensive data but also enhances the report’s presentation by replacing null values with meaningful placeholders, thus providing a fully formatted view ready for executive summary or analytical processing.
Addressing Referential Integrity Errors
Introducing an “orphan” record into the ORDERS table — an order without a corresponding customer or salesperson — highlights the challenges of maintaining referential integrity in relational databases.
This concept ensures that all records in a database are connected appropriately, preventing the existence of orphaned data.
However, this example deliberately bypasses these constraints to illustrate how SQL can be used to identify such discrepancies.
INSERT INTO `chapter04`.`ORDERS` (`order_id`, `customer_id`, `salesperson_id`, `order_date`, `delivery_id`)
VALUES (1004, 10, 6, NOW(), 23);This insertion, executed successfully, signifies that referential integrity checks were not enforced, allowing the creation of an order that lacks a valid customer link.
The scenario serves as a common database issue, potentially leading to performance compromises and data inconsistency. To remedy performance issues, some might temporarily disable referential integrity, risking further data integrity for the sake of speed.
We’ll explore SQL strategies for identifying such orphan records, underscoring the importance of robust database management practices to ensure data reliability and system integrity.
Identifying Orphan Records with SQL Joins
To address the challenge of identifying orphan records, which was intentionally introduced into the database, we explore the use of SQL joins.
The exercise of creating and then resolving such issues is a valuable learning tool, showcasing the practical application of SQL knowledge in real-world scenarios.
Using a LEFT JOIN, we attempted to detect any orphan records by retrieving all customers and their corresponding order IDs, with NULL values for orders that don’t exist:
# Left Join to identify missing orders
SELECT C.customer_name, O.order_id
FROM chapter04.CUSTOMERS AS C
LEFT OUTER JOIN chapter04.ORDERS AS O ON C.customer_id = O.customer_id;This query successfully lists all customers, indicating missing orders with NULL order IDs but doesn’t fully solve the issue of detecting all types of orphan records. Switching to a RIGHT JOIN reveals orders without a linked customer but omits customers without orders.
The logical step to comprehensively identify all discrepancies would be a FULL OUTER JOIN, aiming to combine the insights of both LEFT and RIGHT JOINS.
However, encountering limitations with MySQL’s support for FULL OUTER JOIN necessitates an alternative approach.
Since FULL OUTER JOIN is not universally supported across all SQL database management systems, including MySQL, the next logical step involves using a UNION to merge the results of separate LEFT and RIGHT JOIN queries, offering a comprehensive solution to identify all orphan records. This method will be elaborated in the following lesson.
Utilizing UNION and UNION ALL Data Retrieval
To address the challenge of identifying both orders and customers, including those without an association, SQL provides the UNION and UNION ALL commands. These commands merge the results of separate queries to form a complete dataset.
- LEFT OUTER JOIN: Retrieves all customers, including those without orders, marking unplaced orders with NULL.
SELECT C.customer_name, O.order_id
FROM chapter04.CUSTOMERS AS C
LEFT OUTER JOIN chapter04.ORDERS AS O ON C.customer_id = O.customer_id;- RIGHT OUTER JOIN: Captures all orders, even those without a linked customer.
SELECT C.customer_name, O.order_id
FROM chapter04.CUSTOMERS AS C
RIGHT OUTER JOIN chapter04.ORDERS AS O ON C.customer_id = O.customer_id;- UNION ALL: Combines the results of the above joins, allowing duplicates.
- UNION: Similar to UNION ALL but eliminates duplicate records, ensuring only unique entries are returned.
The key difference between UNION and UNION ALL lies in handling duplicates: UNION ALL includes every record, even duplicates, while UNION filters out duplicates to present only unique results.
This distinction is crucial for tasks requiring either comprehensive data inclusion or refined, distinct results.
Important considerations for using UNION commands include matching the number and type of columns across combined queries and maintaining consistent column order to ensure data integrity and query performance.
While UNION operations can impact performance, they are sometimes the only viable solution for achieving desired data compilations, especially in environments lacking support for FULL OUTER JOIN.
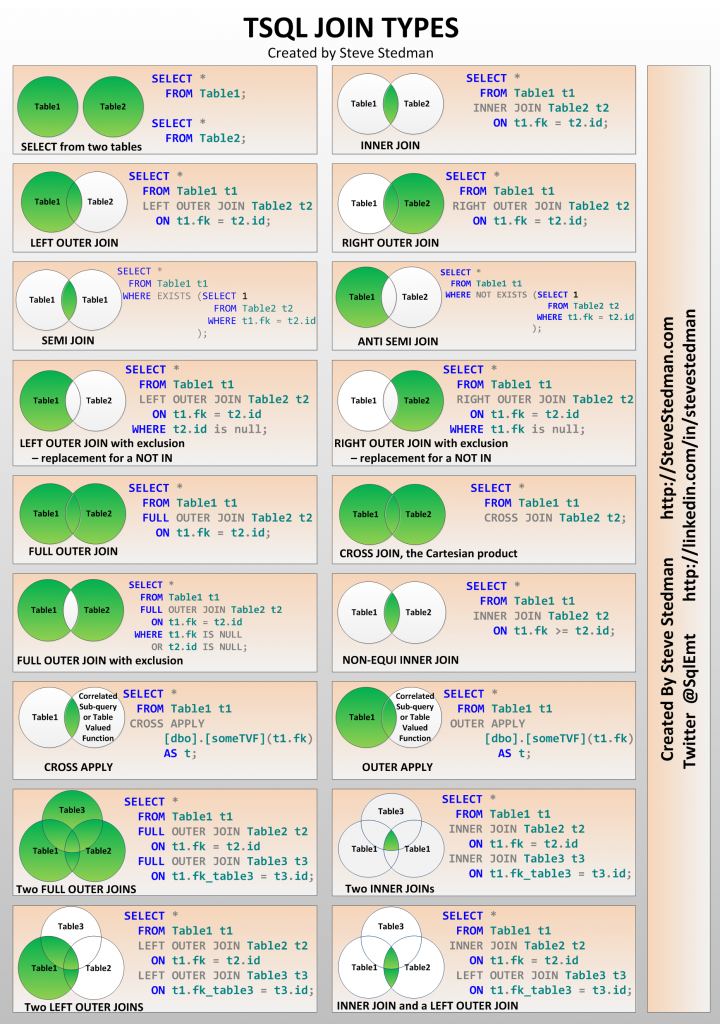
Summary of Table Joins
This overview references a chart created by Steve Stedman, a notable figure in the SQL Server community, illustrating various join types applicable in SQL Server and, with some adaptations, in other SQL database systems like MySQL.
Stedman’s blog, a longstanding resource for database knowledge, offers insights into SQL Server’s nuances through courses and reference materials.

- Basic Selects and Joins: Begins with selecting data from two tables, then covers the familiar INNER JOIN (intersection), and LEFT and RIGHT OUTER JOINS, emphasizing their equivalence without the “OUTER” keyword.
- Advanced Join Concepts: Introduces semi-joins and anti-semi-joins, using SQL’s EXISTS operator to filter data uniquely, showcasing how to retrieve partial or exclusive dataset from one table.
- Cross and Full Outer Joins: Differentiates between CROSS JOIN (Cartesian product) and FULL OUTER JOIN (combining all records with and without matching entries), cautioning against their apparent similarity in graphical representations.
- Union Operations: Describes using UNION and UNION ALL to simulate a FULL OUTER JOIN effect in systems lacking direct support, achieving comprehensive data integration.
- Complex Relationships: Concludes with handling multi-table relationships through various join types, enhancing query complexity and data retrieval capabilities.
This chart serves as a practical guide for applying SQL joins, from basic to complex scenarios, encouraging hands-on practice to master table joining techniques in SQL.
*Conclusion on SQL Table Joins
Throughout this article, we delved into the world of table joins in SQL, a crucial aspect for anyone working with relational databases. Guided by educational resources like Steve Stedman’s blog and hands-on practice in tools such as MySQL Workbench, we unraveled the layers of complexity surrounding effective data manipulation through various join types.
From basic operations with INNER JOIN to the adaptability of LEFT and RIGHT OUTER JOINS, and addressing the challenge of implementing FULL OUTER JOINS in systems without direct support, we learned that the choice of join type directly influences query outcomes and performance. We emphasized the value of referential integrity and methods to detect and address orphan records, ensuring data consistency and reliability.
The ability to combine UNION and UNION ALL for simulating complete joins, alongside applying CROSS JOIN for specific scenarios, showcases SQL’s versatility in meeting complex data analysis needs. Introducing advanced concepts like semi-joins and anti-semi-joins highlighted SQL’s capability for specific data filtering and selection, going beyond traditional join boundaries.
This article reaffirmed the importance of establishing query standards and maintaining code readability, facilitating database maintenance, understanding, and expansion over time. We encourage ongoing learning and experimentation, as each challenge encountered and overcome contributes to enhancing SQL proficiency, equipping professionals to efficiently and accurately solve complex business problems.
In summary, table joins are not just technical tools; they are the backbone of crafting meaningful queries that transform raw data into valuable insights. As we move to future chapters, we carry forward a robust knowledge base and practical experience necessary to navigate the vast world of databases with confidence and expertise.
Thank you! 🐼❤️
Source : https://levelup.gitconnected.com/mastering-sql-joins-eb786ad7a7c7




No comments:
Post a Comment