This was originally published at https://vutr.substack.com
Intro
If my memory is still good, this is the 5th article about BigQuery from me since I began writing a long-form blog. (I am too lazy to open the writing history). The reason is not only how confident I am when discussing BigQuery (I have used it for my whole career.), but also because BigQuery has many cool things that need to be recognized by many people.
My latest BigQuery article discusses how storage operations are carried out behind the scenes, so it would be a complete picture if another article described how BigQuery handles data processing. That’s how I wrote this article.
Note: Although the goal of this article is to look at how BigQuery processes data internally, I will use the term Dremel most of the time instead of BigQuery because BigQuery is made of many components, and Dremel is its query engine, so using Dremel will give me a chance to deliver the information better.
This blog is my note from what I researched about how BigQuery processes the SQL query from multiple sources; I will leave all the reference documents at the end of this blog.
The query plan
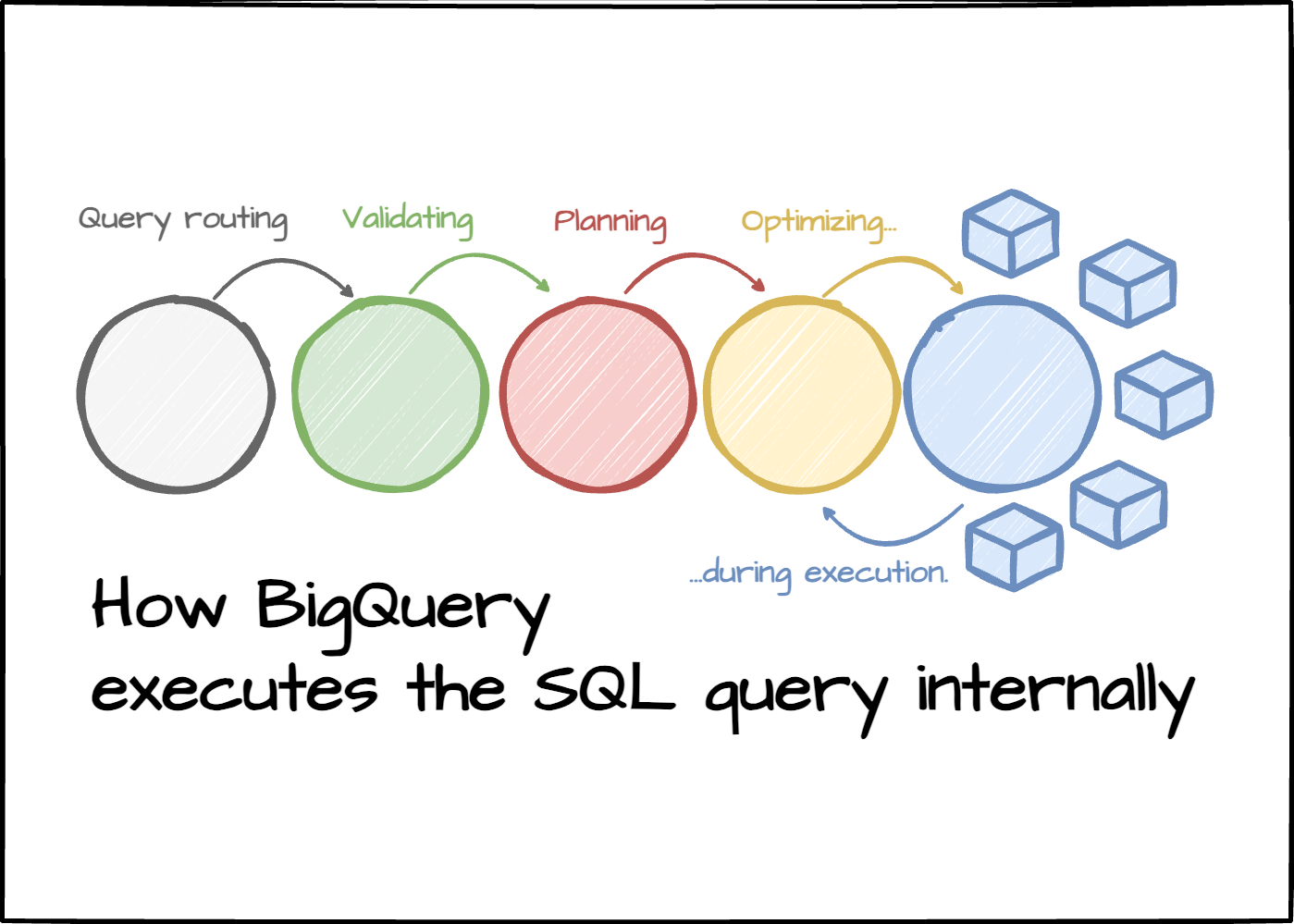
The cool thing about SQL is that you declare the desired result, and somehow, the database returns the result to you in seconds or hours.
To hide that “somehow“ from the user, the database has to do many things behind the scenes, from validating the SQL statement, planning, optimizing the plan, and executing the workload. The magic begins at the planning phase, which is crucial to guarantee the query is run efficiently. In this section, let’s figure out how Dremel constructs the query plan.
Static
Initially, Google described the execution plan as a tree. Dremel uses a static multi-level tree to execute queries:

- The root node acts as an endpoint for receiving queries. After that, it will read the tables’s metadata (table’s location, partition information,…).
- When getting all the information needed for the query, the root node rewrites the query and routes it to the below tree level.
- The query will be rewritten through every server and finally reach the leaf nodes. The leaf nodes communicate with storage to retrieve the data.
- Results and aggregations flow back from the leaves, go through the intermediate nodes, and finally get to the root.
As Dremel evolved, the fixed tree became less ideal for more complex query plans. Google needs a new approach.
Dynamic

In 2010, people from Google changed Dremel’s architecture to build execution plans dynamically rather than having a static tree plan.
Although the tree plan works fine for certain types of queries like scan-filter-aggregate queries, it does not perform well on more complicated queries like JOIN operations or having nested subqueries.
Another reason that encourages Google to change to a dynamic plan is that it is hard to obtain accurate data characteristics during query planning. (Dremel especially takes an “in-situ analyst“ approach, which doesn’t require first loading data into the system. Instead, Dremel will operate on unseen data most of the time). The query plan can now be adjusted dynamically at runtime based on the data’s statistics collected during the execution.
Dremel optimizes the query plan at runtime by changing the number of workers in each stage, switching between shuffle vs. broadcast join, or dynamic repartitioning…
This approach is backed by two significant changes in Dremel architecture: shuffle persistence layer and centralized query orchestration. (these will be covered in the following sections.)
Let’s look at an example where the query has a JOIN operation:
- Dremel supports two JOIN strategies: broadcast vs hash join.
Broadcast joins: When joining a large table to a small table, BigQuery creates a broadcast join where the small table is sent to each slot processing the large table.
Hash joins: When joining two large tables, BigQuery uses hash and shuffle operations to shuffle the left and right tables so that the matching keys end up in the same slot to perform a local join. This is an expensive operation since the data needs to be moved.
Blog: BigQuery explained: Working with joins, nested & repeated data — 2020
- Dremel will start with the hash join strategy by shuffling data on both sides.
- But if one side finishes fast and is below a broadcast data size threshold, Dremel will cancel the second shuffle (stop data is moved around) and execute a broadcast join instead (faster).
After understanding how BigQuery builds the query plan, in the following sections, let’s see the bigger picture: Dremel’s components and how the query is executed.
Components
The Dremel has three parts: the Query Master, the Scheduler, and the Worker Shard.

Query Master
The Query Master is responsible for query planning (on what work needs to be done)
Here’s a list of tasks of Query Master:
- When first seeing the query, it parses it to retrieve two kinds of information: the table needed for the query and each table’s filter. The filter information will be used for partition pruning. If the table is partitioned by and later, when the user filters based on the same column used for the partition, the system only needs to read the necessary files. (I have a detailed article about how BigQuery organizes data files internally.)
- After having the information, the Query Master looks up the table’s metadata from the metadata server (Google using Cloud Spanner for metadata storage); if the partition pruning is applied, the metadata server will only return the file locations for the partitions that match the filter. (Query Master uses other Dremel jobs for the look-up process.)
- Then, the Query Master creates a query plan based on its information. Query plans are dynamic (as mentioned above); the query starts with an initial plan describing how the query can run, which is generally straightforward and becomes more complex as needed. The query plan divides the query into stages, each performing a set of operations.

Scheduler
The Scheduler’s job is to assign slots (figuring out which workers are available)
Dremel changed to centralized scheduling in 2012, allowing more fine-grained resource allocation. It uses the entire cluster state to make decisions, which enables better utilization and isolation.
The primary responsibility of the Scheduler is assigning desired slots to queries.
A slot corresponds to an execution thread on a leaf server. For example, a system of 3,000 leaf servers, each using 8 threads, has 24,000 slots. So, a table spanning 100,000 tablets can be processed by assigning about 5 tablets to each slot.
— source —
If users have the same priority, the scheduler will assign resources fairly among these users. However, the scheduler can cancel running slots at any time (on the lower priority query) to make room for a query with higher priority.
Worker shard
They do the hard work.
The worker is where the actual work is executed. A Worker Shard is a task running in Borg — Google’s container management system (Kubernetes’s ancestor). Borg allows Dremel to perform thousands of tasks without caring much about the infrastructure burden.
The Worker Shard itself can run multiple tasks in parallel (threads); each task represents a unit that can be scheduled; this unit is called the slot, which is mentioned in the scheduler section.
The query’s sources are data files on Colossus or outputs of previous stages (in the shuffle layer). Generally, a single thread of execution (slot) will be in charge of one input file. The destination location is usually an in-memory shuffle layer; if the output does not fit in the memory, it will be spilled to the disk.
Each unit of work in BigQuery is atomic (all or nothing) and idempotent (no matter how many times you execute the job, the result will remain the same). In case the job fails, it can be safely restarted.
Shuffle
Software engineering advantages from the shuffle
The famous MapReduce inspires Dremel’s shuffle. Unlike traditional implementation, where the shuffle is colocated to the worker, Dremel disaggregates the shuffle layer into a dedicated service, which opens many engineering opportunities. (I wrote a detailed article on Dremel’s shuffle.)
Shuffle allows data to be exchanged between stages by routing the data to several sinks. For example, shuffle might write data beginning with “X” to sink 1 and everything beginning with “Y” to sink 2. Then, in the next stage, a single Worker Shard could read from sink 1 and acknowledge that all the data begins with “X“; a different Worker Shard could read from sink 2 and acknowledge that all the data begins with “Y”.

Because the shuffle acts as a destination for the previous stage, the Query Master will check the shuffle statistics to determine the number of slots at the current stage dynamically.

The result of a shuffle can also be used as a checkpoint of the query execution state so that the scheduler can dynamically add or remove workers (the workers are stateless thanks to all the data stored in the shuffle, which now acts like a separate storage).
If the Worker Shard doesn’t respond fast enough (some deadline threshold to define) somewhere else, the query may take a little bit longer to complete. If more than one Worker Shard finishes the same job, the results from the one that ends first are kept.
Another cool thing about Shuffle that should be mentioned here is that it can handle data skew efficiently. Data skew is when data is partitioned into unequal sizes; this leads to some slots having more work to be done than other slots. Dremel dynamically load-balances and adjusts intermediate result partitioning to handle data skew. The Query Master detects if the shuffle partition gets too overloaded and then instructs workers to adjust their partitioning process (repartition).
Note: the “partition” here indicates how data are divided and routed to the shuffle; it differs from the storage partition.
Check an example here:

There are two workers, A and B, at Stage 1, producing output to shuffle layers, let’s say Partition 1 and Partition 2.
- Let’s say that at some time t, the Query Master detects that Partition 2 begins to get full.
- The Query Master instructs workers A and B to do another round of hash; the result is routed to Partition 3 and Partition 4.
- The re-partition worker is brought up to consume Partition 2 and then re-partition the data to Partition 3 and Partition 4. After finishing, Partition 2 will be discarded.
- This way, it can ensure the data has a manageable size between partitions.
The query’s journey
After going through all the Dremel’s components, let’s continue with the journey of the query: from the time the user submits the query to when the result is returned:

Whenever you submit a query using UI console, CLI, SDK, or curl, it will send an HTTP POST request to the BigQuery endpoint to modify the state by creating a query job.
- The HTTP request is routed through the internet to the REST endpoint, which is served by a Google Front-End (GFE) server, the same type of server that services Google Search and other Google products. The GFE needs to route the BigQuery backend that can handle the request.
- The state of a request is kept tracked by the BigQuery Job Server. The Job Server operates asynchronously with the assumption that the network connection between the client and server can fail at any time, plus the query can take many hours to run. The Job Server also performs authorization to make sure that the caller is allowed to run a query.
- The Job Server routes the request to the Query Master. The Query Master will contact the metadata server to get information about the physical data and how it is partitioned. (as explained in detail in the “Query Master” above).
- After knowing the amount of involved data, the Query Master constructs the initial query plan and requests slots from the scheduler.
- The scheduler determines the number of slots for the query and returns the address of these resources for the Query Master. The Query Master then sends the query jobs to each resource in parallel.
- After the query worker shards finish executing the query, the results are returned to the client.
Outro
It’s time to wrap it up.
Dremel’s most exciting characteristic (to me) is its dynamic query plans. Thanks to the shuffle layer (which makes the worker stateless) and the centralized scheduler (which observes the whole cluster status to make the schedule decisions), BigQuery can adapt to the workload efficiently.
In particular, the disaggregated shuffle layer gives many software engineering advantages to the whole system. (I think despite the latency of writing to the remote shuffle, its engineering benefit seems to outweigh other factors)
Now, see you next Saturday.
(Next week’s blog post is about Snowflake, but don’t get me wrong, I won’t stop writing about BigQuery)




No comments:
Post a Comment