Pandas is the go-to library for every data scientist. It is essential for every person who wishes to manipulate data and perform some data analysis.
However, despite its practicality and extensive set of features, we quickly start to see its limits when manipulating large data sets. It’s in this case that a transition to PySpark becomes essential since it offers the possibility to run operations on multiple machines, unlike Pandas. In this article, we will provide the equivalents of pandas methods in PySpark with ready-to-use code snippets, to facilitate the task for new adepts of PySpark 😉
PySpark offers the possibility to run operations on multiple machines, unlike Pandas
Table Of Contents
· DataFrame creation
· Specifying columns types
· Reading and writing files
· Filtering
∘ Specific columns
∘ Specific lines
∘ Using a condition
· Add a column
· Concatenate dataframes
∘ Two Dataframes
∘ Multiple Dataframes
· Computing specified statistics
· Aggregations
· Apply a transformation over a columnGetting started
Before diving into the equivalents, we first need to set the floor for later. It goes without saying that the first step is to import the needed libraries:
import pandas as pd
import pyspark.sql.functions as FThe entry point into PySpark functionalities is the SparkSession class. Through the SparkSession instance, you can create dataframes, apply all kinds of transformations, read and write files, etc … To define a SparkSession you can use the following :
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.appName('SparkByExamples.com')\
.getOrCreate()Now that everything is set, let’s jump right into the Pandas vs PySpark part!
DataFrame creation
First, let’s define a data sample we’ll be using:
columns = ["employee","department","state","salary","age"]
data = [("Alain","Sales","Paris",60000,34),
("Ahmed","Sales","Lyon",80000,45),
("Ines","Sales","Nice",55000,30),
("Fatima","Finance","Paris",90000,28),
("Marie","Finance","Nantes",100000,40)]To create a Pandas DataFrame , we can use the following:
df = pd.DataFrame(data=data, columns=columns)
# Show a few lines
df.head(2)PySpark
df = spark.createDataFrame(data).toDF(*columns)
# Show a few lines
df.limit(2).show()Specifying columns types
Pandas
types_dict = {
"employee": pd.Series([r[0] for r in data], dtype='str'),
"department": pd.Series([r[1] for r in data], dtype='str'),
"state": pd.Series([r[2] for r in data], dtype='str'),
"salary": pd.Series([r[3] for r in data], dtype='int'),
"age": pd.Series([r[4] for r in data], dtype='int')
}
df = pd.DataFrame(types_dict)You can check your types by executing this line:
df.dtypesPySpark
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
schema = StructType([ \
StructField("employee",StringType(),True), \
StructField("department",StringType(),True), \
StructField("state",StringType(),True), \
StructField("salary", IntegerType(), True), \
StructField("age", IntegerType(), True) \
])
df = spark.createDataFrame(data=data,schema=schema)You can check your DataFrame’s schema by executing :
df.dtypes
# OR
df.printSchema()Reading and writing files
Reading and writing are so similar in Pandas and PySpark. The syntax is the following for each: Pandas
df = pd.read_csv(path, sep=';', header=True)
df.to_csv(path, ';', index=False)PySpark
df = spark.read.csv(path, sep=';')
df.coalesce(n).write.mode('overwrite').csv(path, sep=';')Note 1 💡: that you can specify a column on which you wish to partition:
df.partitionBy("department","state").write.mode('overwrite').csv(path, sep=';')Note 2 💡: You can read and write in different formats like parquet format by changing the CSV by parquet in all the lines of code above
Filtering
Specific columns
Selecting certain columns in Pandas is done like so: Pandas
columns_subset = ['employee', 'salary']
df[columns_subset].head()
df.loc[:, columns_subset].head()Whereas in PySpark, we need to use the select method with a list of columns: PySpark
columns_subset = ['employee', 'salary']
df.select(columns_subset).show(5)Specific lines
To select a range of lines, you can use the ilocmethod in Pandas:
Pandas
# Take a sample ( first 2 lines )
df.iloc[:2].head()In Spark, it is not possible to get any range of line numbers. It is however possible to select the n first lines like so:
PySpark
df.take(2).head()
# Or
df.limit(2).head()Note 💡 : With spark keep in mind the data is potentially distributed over different compute nodes and the “first” lines may change from run to run since there is no underlying order
Using a condition
It is possible to filter data based on a certain condition. The syntax in Pandas is the following:
Pandas
# First method
flt = (df['salary'] >= 90_000) & (df['state'] == 'Paris')
filtered_df = df[flt]
# Second Method: Using query which is generally faster
filtered_df = df.query('(salary >= 90_000) and (state == "Paris")')
# Or
target_state = "Paris"
filtered_df = df.query('(salary >= 90_000) and (state == @target_state)')In Spark, the same result can be found by using the filtermethod or executing an SQL query. The syntax is the following:
PySpark
# First method
filtered_df = df.filter((F.col('salary') >= 90_000) & (F.col('state') == 'Paris'))
# Second Method:
df.createOrReplaceTempView("people")
filtered_df = spark.sql("""
SELECT * FROM people
WHERE (salary >= 90000) and (state == "Paris")
""")
# OR
filtered_df = df.filter(F.expr('(salary >= 90000) and (state == "Paris")'))Add a column
In Pandas, there are several ways to add a column:
Pandas
seniority = [3, 5, 2, 4, 10]
# Method 1
df['seniority'] = seniority
# Method 2
df.insert(2, "seniority", seniority, True)In PySpark there is a specific method called withColumn that can be used to add a column:
PySpark
seniority = [3, 5, 2, 4, 10]
df = df.withColumn('seniority', seniority)Concatenate dataframes
Two Dataframes
Pandas
df_to_add = pd.DataFrame(data=[("Robert","Advertisement","Paris",55000,27)], columns=columns)
df = pd.concat([df, df_to_add], ignore_index = True)PySpark
df_to_add = spark.createDataFrame([("Robert","Advertisement","Paris",55000,27)]).toDF(*columns)
df = df.union(df_to_add)Multiple Dataframes
Pandas
dfs = [df, df1, df2,...,dfn]
df = pd.concat(dfs, ignore_index = True)The method unionAllof PySpark only concatenates two dataframes. A workaround for this limit is to iterate the concatenations as many times as needed. For a more compact elegant syntax, we’re going to avoid loops and use the reduce method to apply unionAll:
PySpark
from functools import reduce
from pyspark.sql import DataFrame
def unionAll(*dfs):
return reduce(DataFrame.unionAll, dfs)
dfs = [df, df1, df2,...,dfn]
df = unionAll(*dfs)Computing specified statistics
In some cases, we need to perform some data analysis through some statistical KPIs. Both Pandas and PySpark offer the possibility to get very easily the following pieces of information for each column in the dataframe:
- The count of the column elements
- The mean of the column elements
- The stddev
- The min value
- Three percentiles: 25%, 50%, and 75%
- The max value
You can compute these values simply by executing one of these lines:
Pandas and PySpark
df.summary()
#OR
df.describe() # the method describe doesn't return the percentilesAggregations
To perform some aggregations, the syntax is almost the Pandas and PySpark: Pandas
df.groupby('department').agg({'employee': 'count', 'salary':'max', 'age':'mean'})PySpark
df.groupBy('department').agg({'employee': 'count', 'salary':'max', 'age':'mean'})However, the results need some tweaking to be similar in pandas and PySpark. 1. In pandas the column to group by becomes the index:
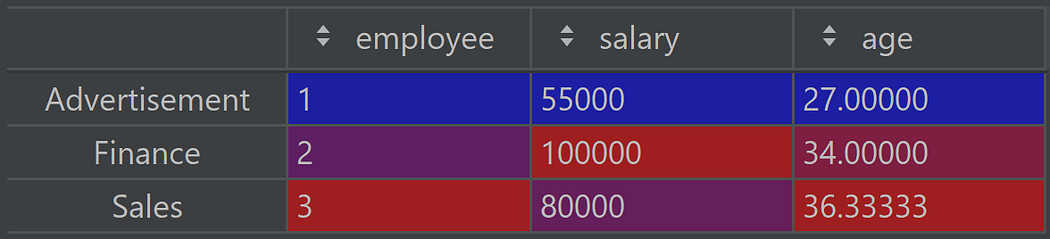
To get it back as a column, we need to apply the reset_index method: Pandas
df.groupby('department').agg({'employee': 'count', 'salary':'max', 'age':'mean'}).reset_index()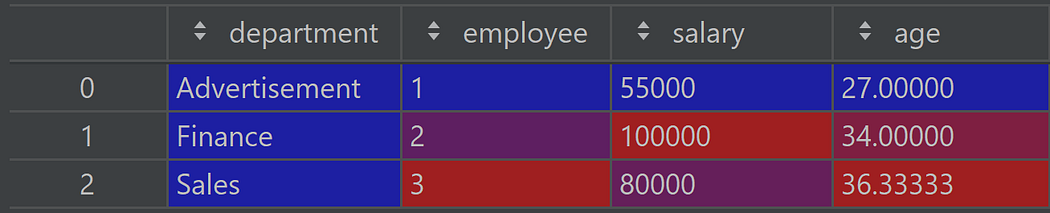
- In PySpark the names of the columns get modified in the resulting dataframe, mentioning the performed aggregation:

If you wish to avoid this, you’ll need to use the alias method like so:
df.groupBy('department').agg(F.count('employee').alias('employee'), F.max('salary').alias('salary'), F.mean('age').alias('age'))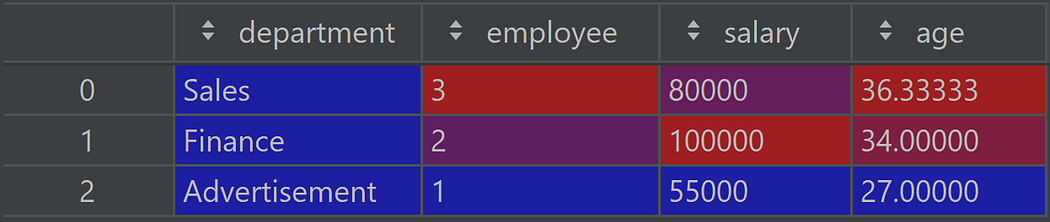
Apply a transformation over a column
To apply a certain transformation over a column, the apply method is no longer an option in PySpark. Instead, we can use a method called udf ( or user-defined function) that envelopes a python function.
For example, we need to increase salary by 15% if the salary is under 60000 and by 5% if over 60000.
The syntax in pandas is the following:
df['new_salary'] = df['salary'].apply(lambda x: x*1.15 if x<= 60000 else x*1.05)The equivalent in PySpark is the following:
from pyspark.sql.types import FloatType
df.withColumn('new_salary', F.udf(lambda x: x*1.15 if x<= 60000 else x*1.05, FloatType())('salary'))⚠️ Note that the udfmethod needs the data type to be specified explicitly (in our case FloatType)
Final thoughts
To conclude, it is clear that there are a lot of similarities between the syntax of Pandas and PySpark. This should facilitate immensely the transition from one to another.
Using PySpark can give you a great advantage when working with big datasets since it allows parallel computing. However, if the dataset you’re working with is small, it becomes quickly more efficient to revert to the one and only Pandas.
Since this article is all about transitioning smoothly from Pandas to PySpark, it is important to mention that there is a pandas equivalent API called Koalas that works on Apache Spark and therefore fills this gap between the two.
Thank you for sticking this far. Stay safe and see you in the next story 😊!
If you’re interested in learning more about scikit-learn, check out these articles:




No comments:
Post a Comment