Why is bringing machine learning code into production hard?
Machine Learning applications are becoming popular in all industries, however, the process for developing, deploying, and continuously improving them is more complex compared to more traditional software, such as a web service or a mobile application. They are subject to change in three dimensions: the base code itself, the model parameters, and the data. Unlike with most software, improvement in models is more ambiguous as performance is not measured in right or wrong but with various quantitative measures and tradeoffs with model complexity. In addition, real-world data is continuously changing affecting the performance of the machine learning application in production. This means that the application needs to be continuously monitored and the model retrained on new data.
What is “CD4ML”?
Continuous Delivery for Machine Learning (CD4ML) is the discipline of bringing Continuous Delivery principles and practices to Machine Learning applications. The concept has been derived from Continuous Delivery, an approach developed 25 years ago to foster automation, quality, and discipline to create a reliable and repeatable process to release software into production.
CD4ML builds upon this, allowing a cross-functional team to produce machine learning applications based on code, data, and models that progress in small and safe increments that can be reproduced and reliably released at any time. This improves greatly over typical approaches which include lots of manual, difficult-to-reproduce steps and handoffs that result in errors, confusion, and occasionally, disaster.


Figure 1: The overall process of CD4ML
Figure 1 shows the different steps of the overall CD4ML process. This begins with the work of a Data Scientist, using easily discoverable and accessible data to build a model. The inputs to the training process include the model itself, the parameters, the source code and the training data required. One item to note is that throughout this entire process, we are carrying the source code, executables, model and parameters through the entire CD4ML pipeline. The next step would be Model Evaluation, ensuring that it’s predictive accuracy is acceptable for the performance of your application using your testing data.
Afterwards, we need to Productionize and perform Integration Testing on our model. This might involve exposing a RESTful endpoint to our model for consumers, integrating it into a streaming pipeline for real-time predictions or perhaps adjusting the implementing language like adjusting a machine learning model to run on a big data framework like Apache Spark. During this Productionization process, one item we want to ensure is that if we need to adjust the model that the productionized implementation matches the original implementation, so writing integration tests to ensure model predictive performance matches between implementation adjustments is critical.


Lastly, we move to deployment and monitoring. During these steps we monitor our model in production ensuring metrics such as model prediction accuracy, response time and system load are acceptable. It’s also important to capture the information around what is being asked from the model and the final outcome; a key concept is that these processes should be happening continuously and the outputs from monitoring should be used in the next iteration of development of our machine learned model. This live collected data should be used as input when iterating on the model along with any source code and parameter adjustments. Finally, If there are any code adjustments, this CD4ML pipeline should trigger the machine learning process to start from the beginning to ensure continuous delivery and the latest code changes and models are available for customers to use.
How can you try CD4ML on your laptop?
At ODSC Europe this fall, we invite you to our workshop to join us to learn about CD4ML. This workshop runs completely on your local environment using open source data and technologies. You can browse the repository here. During the workshop, we will guide you through the steps of CD4ML using the tools in Figure 2 and how they communicate to each other in Figure 3.


Figure 2: The different tools we will use and their categories.
One important aspect of CD4ML is that it is a software development approach which incorporates the entire data science and model development workflow. The tools used just need to apply to the six categories outlined in Figure 2. For instance, for “Continuous Delivery Orchestration to Combine Pipelines” you can use Jenkins or another tool like CircleCI. For “Model Monitoring and Observability” tools like Prometheus or monitoring tools provided by your cloud provider, such as AWS CloudWatch or Azure Monitoring can be used. This software development approach is preferred because it allows for the development team to collaborate and come together to evaluate and choose the tools best fit for their development process.

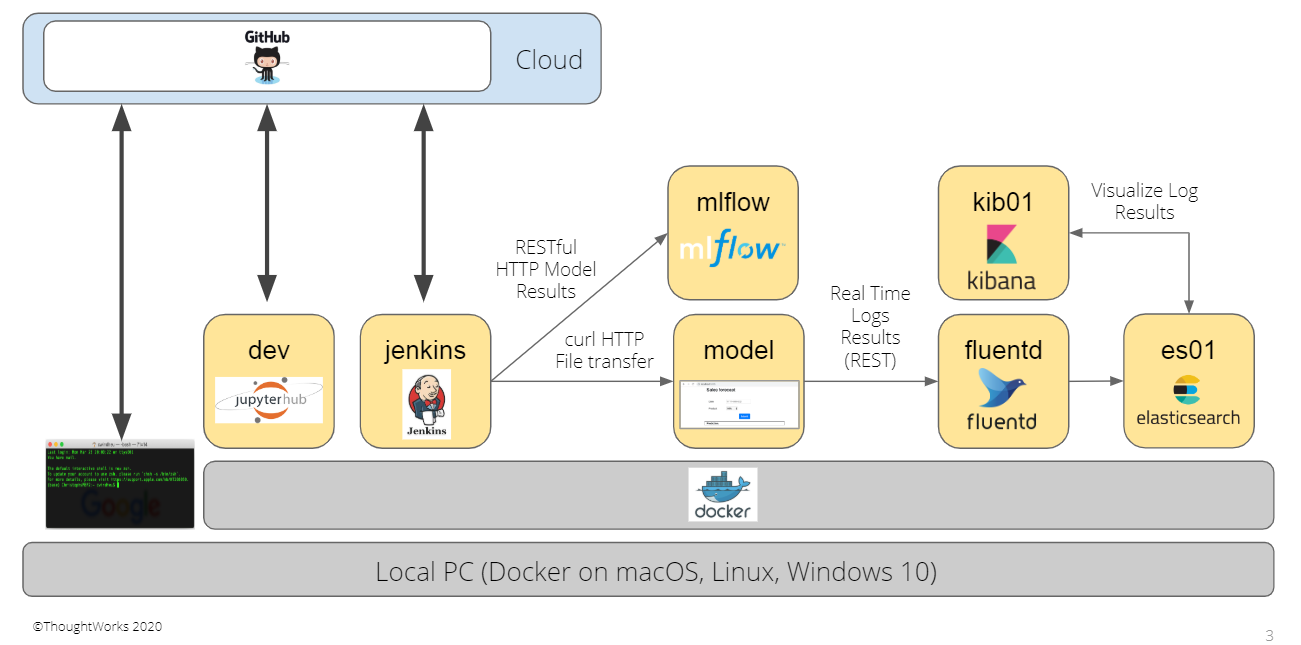
Figure 3: The overall architecture of our scenario
As part of this workshop, we will be completing the following real-world scenarios together. These scenarios represent the major steps and learnings in a teams software development process in implementing CD4ML:
- Doing the plumbing: Set up the pipeline and see if it is working
- Data Science: Develop the model and test the code with Test Driven Development
- Machine Learning Engineering: Improve the model in several steps and monitor the results
- Continuous Deployment: Set up a performance test of the model, which only allows automatic deployment if the model passes the test
- Undo changes: Roll changes back in time, consistently, with all artifacts
- Our app in the wild: Monitor your application in production with fluentd, elasticsearch and kibana
As Machine Learning techniques continue to evolve and perform more complex tasks, so is evolving our knowledge of how to manage and deliver such applications to production. By bringing and extending the principles and practices from Continuous Delivery, we can better manage the risks of releasing changes to Machine Learning applications in a safe and reliable way.
We look forward to seeing you at ODSC Europe 2020 at our talk, “Data Science Best Practices: Continuous Delivery for Machine Learning“!
References:
Continuous Delivery for Machine Learning — Martin Fowler




No comments:
Post a Comment