https://tenthousandmeters.com/blog/python-behind-the-scenes-12-how-asyncawait-works-in-python/
Mark functions as async. Call them with await. All of a sudden, your program becomes asynchronous – it can do useful things while it waits for other things, such as I/O operations, to complete.
Code written in the async/await style looks like regular synchronous code but works very differently. To understand how it works, one should be familiar with many non-trivial concepts including concurrency, parallelism, event loops, I/O multiplexing, asynchrony, cooperative multitasking and coroutines. Python's implementation of async/await adds even more concepts to this list: generators, generator-based coroutines, native coroutines, yield and yield from. Because of this complexity, many Python programmers that use async/await do not realize how it actually works. I believe that it should not be the case. The async/await pattern can be explained in a simple manner if you start from the ground up. And that's what we're going to do today.
Note: In this post I'm referring to CPython 3.9. Some implementation details will certainly change as CPython evolves. I'll try to keep track of important changes and add update notes.
It's all about concurrency
Computers execute programs sequentially – one instruction after another. But a typical program performs multiple tasks, and it doesn't always make sense to wait for some task to complete before starting the next one. For example, a chess program that waits for a player to make a move should be able to update the clock in the meantime. Such an ability of a program to deal with multiple things simultaneously is what we call concurrency. Concurrency doesn't mean that multiple tasks must run at the same physical time. They can run in an interleaved manner: a task runs for some time, then suspends and lets other tasks run, hoping it will get more time in the future. By this mechanism, an OS can run thousands of processes on a machine that has only a few cores. If multiple tasks do run at the same physical time, as in the case of a multi-core machine or a cluster, then we have parallelism, a special case of concurrency [1].
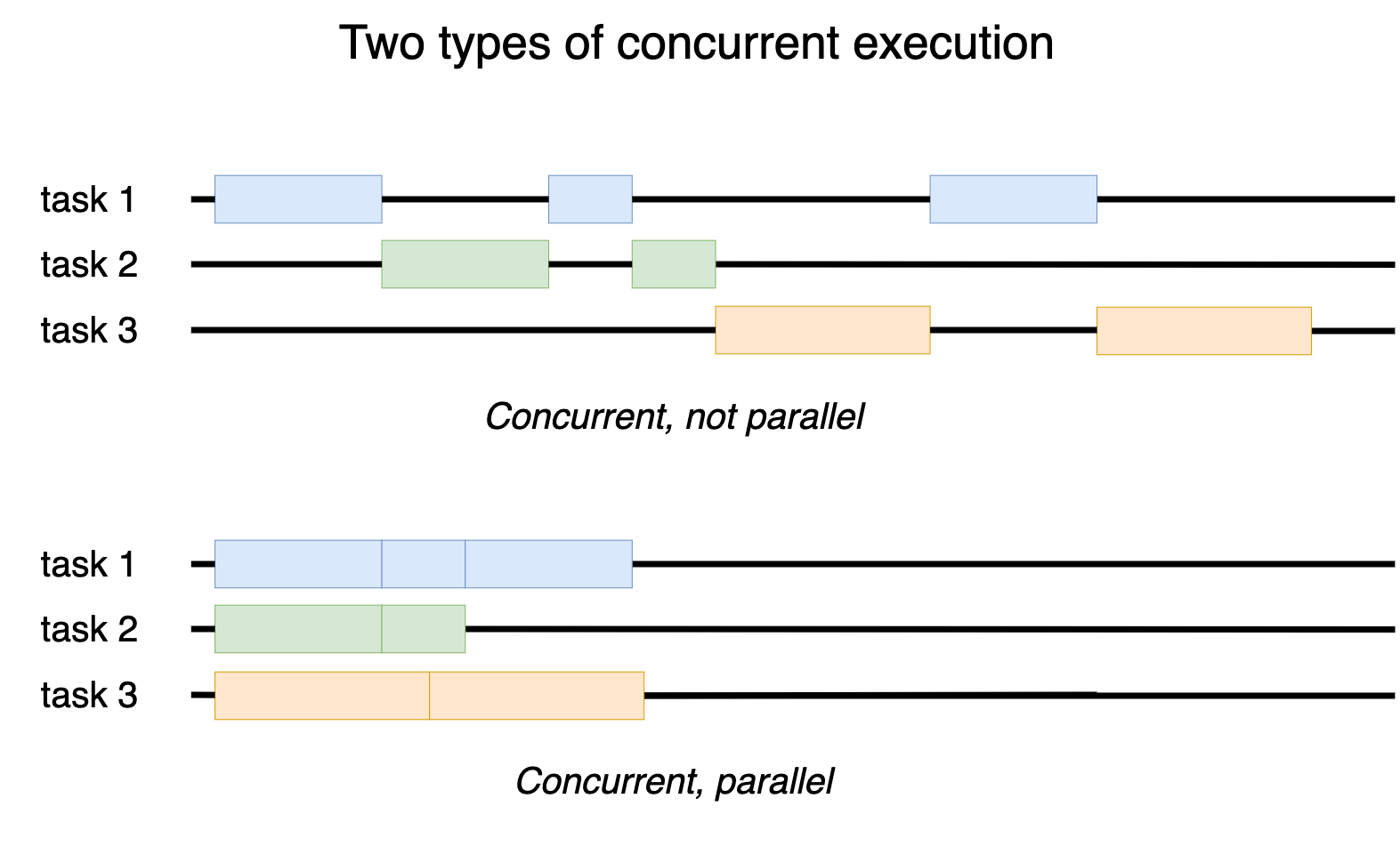
It's crucial to realize that you can write concurrent programs without any special support from the language. Suppose you write a program that performs two tasks, each task being represented by a separate function:
def do_task1():
# ...
def do_task2():
# ...
def main():
do_task1()
do_task2()
If the tasks are independent, then you can make the program concurrent by decomposing each function into several functions and call the decomposed functions in an interleaved manner, like so:
def do_task1_part1():
# ...
def do_task1_part2():
# ...
def do_task2_part1():
# ...
def do_task2_part2():
# ...
def main():
do_task1_part1()
do_task2_part1()
do_task1_part2()
do_task2_part2()
Of course, this is an oversimplified example. The point here is that the language doesn't determine whether you can write concurrent programs or not but may provide features that make concurrent programming more convenient. As we'll learn today, async/await is just such a feature.
To see how one goes from concurrency to async/await, we'll write a real-world concurrent program – a TCP echo server that supposed to handle multiple clients simultaneously. We'll start with the simplest, sequential version of the server that is not concurrent. Then we'll make it concurrent using OS threads. After that, we'll see how we can write a concurrent version that runs in a single thread using I/O multiplexing and an event loop. From this point onwards, we'll develop the single-threaded approach by introducing generators, coroutines and, finally, async/await.
A sequential server
Writing a TCP echo server that handles only one client at a time is straightforward. The server listens for incoming connections on some port, and when a client connects, the server talks to the client until the connection is closed. Then it continues to listen for new connections. This logic can be implemented using basic socket programming:
# echo_01_seq.py
import socket
def run_server(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
while True:
client_sock, addr = sock.accept()
print('Connection from', addr)
handle_client(client_sock)
def handle_client(sock):
while True:
received_data = sock.recv(4096)
if not received_data:
break
sock.sendall(received_data)
print('Client disconnected:', sock.getpeername())
sock.close()
if __name__ == '__main__':
run_server()
Take time to study this code. We'll be using it as a framework for subsequent, concurrent versions of the server. If you need a reminder on sockets, check out Beej's Guide to Network Programming and the docs on the socket module. What we do here in a nutshell is:
- create a new TCP/IP socket with
socket.socket() - bind the socket to an address and a port with
sock.bind() - mark the socket as a "listening" socket with
sock.listen() - accept new connections with
sock.accept() - read data from the client with
sock.recv()and send the data back to the client withsock.sendall().
This version of server is not concurrent by design. When multiple clients try to connect to the server at about the same time, one client connects and occupies the server, while other clients wait until the current client disconnects. I wrote a simple simulation program to demonstrate this:
$ python clients.py
[00.097034] Client 0 tries to connect.
[00.097670] Client 1 tries to connect.
[00.098334] Client 2 tries to connect.
[00.099675] Client 0 connects.
[00.600378] Client 0 sends "Hello".
[00.601602] Client 0 receives "Hello".
[01.104952] Client 0 sends "world!".
[01.105166] Client 0 receives "world!".
[01.105276] Client 0 disconnects.
[01.106323] Client 1 connects.
[01.611248] Client 1 sends "Hello".
[01.611609] Client 1 receives "Hello".
[02.112496] Client 1 sends "world!".
[02.112691] Client 1 receives "world!".
[02.112772] Client 1 disconnects.
[02.113569] Client 2 connects.
[02.617032] Client 2 sends "Hello".
[02.617288] Client 2 receives "Hello".
[03.120725] Client 2 sends "world!".
[03.120944] Client 2 receives "world!".
[03.121044] Client 2 disconnects.
The clients connect, send the same two messages and disconnect. It takes half a second for a client to type a message, and thus it takes about three seconds for the server to serve all the clients. A single slow client, however, could make the server unavailable for an arbitrary long time. We should really make the server concurrent!
OS threads
The easiest way to make the server concurrent is by using OS threads. We just run the handle_client() function in a separate thread instead of calling it in the main thread and leave the rest of the code unchanged:
# echo_02_threads.py
import socket
import threading
def run_server(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
while True:
client_sock, addr = sock.accept()
print('Connection from', addr)
thread = threading.Thread(target=handle_client, args=[client_sock])
thread.start()
def handle_client(sock):
while True:
received_data = sock.recv(4096)
if not received_data:
break
sock.sendall(received_data)
print('Client disconnected:', sock.getpeername())
sock.close()
if __name__ == '__main__':
run_server()
Now multiple clients can talk to the server simultaneously:
$ python clients.py
[00.095948] Client 0 tries to connect.
[00.096472] Client 1 tries to connect.
[00.097019] Client 2 tries to connect.
[00.099666] Client 0 connects.
[00.099768] Client 1 connects.
[00.100916] Client 2 connects.
[00.602212] Client 0 sends "Hello".
[00.602379] Client 1 sends "Hello".
[00.602506] Client 2 sends "Hello".
[00.602702] Client 0 receives "Hello".
[00.602779] Client 1 receives "Hello".
[00.602896] Client 2 receives "Hello".
[01.106935] Client 0 sends "world!".
[01.107088] Client 1 sends "world!".
[01.107188] Client 2 sends "world!".
[01.107342] Client 0 receives "world!".
[01.107814] Client 0 disconnects.
[01.108217] Client 1 receives "world!".
[01.108305] Client 1 disconnects.
[01.108345] Client 2 receives "world!".
[01.108395] Client 2 disconnects.
The one-thread-per-client approach is easy to implement, but it doesn't scale well. OS threads are an expensive resource in terms of memory, so you can't have too many of them. For example, the Linux machine that serves this website is capable of running about 8k threads at most, though even fewer threads may be enough to swamp it. With this approach the server not only works poorly under heavy workloads but also becomes an easy target for a DoS attack.
Thread pools solve the problem of uncontrolled thread creation. Instead of submitting each task to a separate thread, we submit tasks to a queue and let a group of threads, called a thread pool, take and process the tasks from the queue. We predefine the maximum number of threads in a thread pool, so the server cannot start too many of them. Here's how we can write a thread pool version of the server using the Python standard concurrent.futures module:
# echo_03_thread_pool.py
import socket
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor(max_workers=20)
def run_server(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
while True:
client_sock, addr = sock.accept()
print('Connection from', addr)
pool.submit(handle_client, client_sock)
def handle_client(sock):
while True:
received_data = sock.recv(4096)
if not received_data:
break
sock.sendall(received_data)
print('Client disconnected:', sock.getpeername())
sock.close()
if __name__ == '__main__':
run_server()
The thread pool approach is both simple and practical. Note, however, that you still need to do something to prevent slow clients from occupying the thread pool. You may drop long-living connections, require the clients to maintain some minimum throughput rate, let the threads return the tasks to the queue or combine any of the suggested methods. The conclusion here is that making the server concurrent using OS threads is not as straightforward as it may seem at first, and it's worthwhile to explore other approaches to concurrency.
I/O multiplexing and event loops
Think about the sequential server again. Such a server always waits for some specific event to happen. When it has no connected clients, it waits for a new client to connect. When it has a connected client, it waits for this client to send some data. To work concurrently, however, the server should instead be able to handle any event that happens next. If the current client doesn't send anything, but a new client tries to connect, the server should accept the new connection. It should maintain multiple active connections and reply to any client that sends data next.
But how can the server know what event it should handle next? By default, socket methods such as accept(), recv() and sendall() are all blocking. So if the server decides to call accept(), it will block until a new client connects and won't be not able to call recv() on the client sockets in the meantime. We could solve this problem by setting a timeout on blocking socket operations with sock.settimeout(timeout) or by turning a socket into a completely non-blocking mode with sock.setblocking(False). We could then maintain a set of active sockets and, for each socket, call the corresponding socket method in an infinite loop. So, we would call accept() on the socket that listens for new connections and recv() on the sockets that wait for clients to send data.
The problem with the described approach is that it's not clear how to do the polling right. If we make all the sockets non-blocking or set timeouts too short, the server will be making calls all the time and consume a lot of CPU. Conversely, if we set timeouts too long, the server will be slow to reply.
The better approach is to ask the OS which sockets are ready for reading and writing. Clearly, the OS has this information. When a new packet arrives on a network interface, the OS gets notified, decodes the packet, determines the socket to which the packet belongs and wakes up the processes that do a blocking read on that socket. But a process doesn't need to read from the socket to get notified. It can use an I/O multiplexing mechanism such as select(), poll() or epoll() to tell the OS that it's interested in reading from or writing to some socket. When the socket becomes ready, the OS will wake up such processes as well.
The Python standard selectors module wraps different I/O multiplexing mechanisms available on the system and exposes each of them via the same high-level API called a selector. So it exposes select() as SelectSelector and epoll() as EpollSelector. It also exposes the most efficient mechanism available on the system as DefaultSelector.
Let me show you how you're supposed to use the selectors module. You first create a selector object:
sel = selectors.DefaultSelector()
Then you register a socket that you want to monitor. You pass the socket, the types of events you're interested in (the socket becomes ready for reading or writing) and any auxiliary data to the selector's register() method:
sel.register(sock, selectors.EVENT_READ, my_data)
Finally, you call the selector's select() method:
keys_events = sel.select()
This call returns a list of (key, events) tuples. Each tuple describes a ready socket:
keyis an object that stores the socket (key.fileobj) and the auxiliary data associated with the socket (key.data).eventsis a bitmask of events ready on the socket (selectors.EVENT_READorselectors.EVENT_WRITEor both).
If there are ready sockets when you call select(), then select() returns immediately. Otherwise, it blocks until some of the registered sockets become ready. The OS will notify select() as it notifies blocking socket methods like recv().
When you no longer need to monitor some socket, you just pass it to the selector's unregister() method.
One question remains. What should we do with a ready socket? We certainly had some idea of what do to with it when we registered it, so let's register every socket with a callback that should be called when the socket becomes ready. That's, by the way, what the auxiliary data parameter of the selector's register() method is for.
We're now ready to implement a single-threaded concurrent version of the server using I/O multiplexing:
# echo_04_io_multiplexing.py
import socket
import selectors
sel = selectors.DefaultSelector()
def setup_listening_socket(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
sel.register(sock, selectors.EVENT_READ, accept)
def accept(sock):
client_sock, addr = sock.accept()
print('Connection from', addr)
sel.register(client_sock, selectors.EVENT_READ, recv_and_send)
def recv_and_send(sock):
received_data = sock.recv(4096)
if received_data:
# assume sendall won't block
sock.sendall(received_data)
else:
print('Client disconnected:', sock.getpeername())
sel.unregister(sock)
sock.close()
def run_event_loop():
while True:
for key, _ in sel.select():
callback = key.data
sock = key.fileobj
callback(sock)
if __name__ == '__main__':
setup_listening_socket()
run_event_loop()
Here we first register an accept() callback on the listening socket. This callback accepts new clients and registers a recv_and_send() callback on every client socket. The core of the program is the event loop – an infinite loop that on each iteration selects ready sockets and calls the corresponding registered callbacks.
The event loop version of the server handles multiple clients perfectly fine. Its main disadvantage compared to the multi-threaded versions is that the code is structured in a weird, callback-centered way. The code in our example doesn't look so bad, but this is in part because we do not handle all the things properly. For example, writing to a socket may block if the write queue is full, so we should also check whether the socket is ready for writing before calling sock.sendall(). This means that the recv_and_send() function must be decomposed into two functions, and one of these functions must be registered as a callback at any given time depending on the server's state. The problem would be even more apparent if implemented something more complex than the primitive echo protocol.
OS threads do not impose callback style programming on us, yet they provide concurrency. How do they do that? The key here is the ability of the OS to suspend and resume thread execution. If we had functions that can be suspended and resumed like OS threads, we could write concurrent single-threaded code. Guess what? Pyhon allows us to write such functions.
Generator functions and generators
A generator function is a function that has one or more yield expressions in its body, like this one:
$ python -q
>>> def gen():
... yield 1
... yield 2
... return 3
...
>>>
When you call a generator function, Python doesn't run the function's code as it does for ordinary functions but returns a generator object, or simply a generator:
>>> g = gen()
>>> g
<generator object gen at 0x105655660>
To actually run the code, you pass the generator to the built-in next() function. This function calls the generator's __next__() method that runs the generator to the first yield expression, at which point it suspends the execution and returns the argument of yield. Calling next() second time resumes the generator from the point where it was suspended, runs it to the next yield expression and returns its argument:
>>> next(g)
1
>>> next(g)
2
When no more yield expressions are left, calling next() raises a StopIteration exception:
>>> next(g)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration: 3
If the generator returns something, the exception holds the returned value:
>>> g = gen()
>>> next(g)
1
>>> next(g)
2
>>> try:
... next(g)
... except StopIteration as e:
... e.value
...
3
Initially generators were introduced to Python as an alternative way to write iterators. Recall that in Python an object that can be iterated over (as with a for loop) is called an iterable. An iterable implements the __iter__() special method that returns an iterator. An iterator, in turn, implements __next__() that returns the next value every time you call it. You can get the values by calling next(), but you typically iterate over them with a for loop:
>>> for i in gen():
... i
...
1
2
Iterators can be iterated over because they are iterables too. Every iterator implements __iter__() that returns the iterator itself.
Generators allowed us to write iterators as functions that yield values instead of defining classes with special methods. Python fills the special methods for us so that generators become iterators automatically.
Generators produce values in a lazy, on-demand manner, so they are memory-efficient and can even be used to generate infinite sequences. See PEP 255 to learn more about such uses cases. We want to use generators for a completely different reason, though. What's important for us is not the values that a generator produces but the fact that it can be suspended and resumed.
Generators as coroutines
Take any program that performs multiple tasks. Turn functions that represent these tasks into generators by inserting few yield statements here and there. Then run the generators in a round-robin fashion: call next() on every generator in some fixed order and repeat this step until all the generators are exhausted. You'll get a concurrent program that runs like this:

Let's apply this strategy to the sequential server to make it concurrent. First we need to insert some yield statements. I suggest to insert them before every blocking operation. Then we need to run generators. I suggest to write a class that does this. The class should provide the create_task() method that adds a generator to a queue of scheduled generators (or simply tasks) and the run() method that runs the tasks in a loop in a round-robin fashion. We'll call this class EventLoopNoIO since it functions like an event loop except that it doesn't do I/O multiplexing. Here's the server code:
# echo_05_yield_no_io.py
import socket
from event_loop_01_no_io import EventLoopNoIO
loop = EventLoopNoIO()
def run_server(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
while True:
yield
client_sock, addr = sock.accept()
print('Connection from', addr)
loop.create_task(handle_client(client_sock))
def handle_client(sock):
while True:
yield
received_data = sock.recv(4096)
if not received_data:
break
yield
sock.sendall(received_data)
print('Client disconnected:', sock.getpeername())
sock.close()
if __name__ == '__main__':
loop.create_task(run_server())
loop.run()
And here's the event loop code:
# event_loop_01_no_io.py
from collections import deque
class EventLoopNoIO:
def __init__(self):
self.tasks_to_run = deque([])
def create_task(self, coro):
self.tasks_to_run.append(coro)
def run(self):
while self.tasks_to_run:
task = self.tasks_to_run.popleft()
try:
next(task)
except StopIteration:
continue
self.create_task(task)
This counts as a concurrent server. You may notice, however, that it has a problem. Its concurrency is very limited. The tasks run in an interleaved manner, but their order is fixed. For example, if the currently scheduled task is the task that accepts new connections, tasks that handle connected clients have to wait until a new client connects.
Another way to phrase this problem is to say that the event loop doesn't check whether socket operations will block. As we've learned, we can fix it by adding I/O multiplexing. Instead of rescheduling a task immediately after running it, the event loop should reschedule the task only when the socket that the task is waiting on becomes available for reading (or writing). A task can register its intention to read from or write to a socket by calling some event loop method. Or it can just yield this information to the event loop. Here's a version of the server that takes the latter approach:
# echo_06_yield_io.py
import socket
from event_loop_02_io import EventLoopIo
loop = EventLoopIo()
def run_server(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
while True:
yield 'wait_read', sock
client_sock, addr = sock.accept()
print('Connection from', addr)
loop.create_task(handle_client(client_sock))
def handle_client(sock):
while True:
yield 'wait_read', sock
received_data = sock.recv(4096)
if not received_data:
break
yield 'wait_write', sock
sock.sendall(received_data)
print('Client disconnected:', sock.getpeername())
sock.close()
if __name__ == '__main__':
loop.create_task(run_server())
loop.run()
And here's the new event loop that does I/O multiplexing:
# event_loop_02_io.py
from collections import deque
import selectors
class EventLoopIo:
def __init__(self):
self.tasks_to_run = deque([])
self.sel = selectors.DefaultSelector()
def create_task(self, coro):
self.tasks_to_run.append(coro)
def run(self):
while True:
if self.tasks_to_run:
task = self.tasks_to_run.popleft()
try:
op, arg = next(task)
except StopIteration:
continue
if op == 'wait_read':
self.sel.register(arg, selectors.EVENT_READ, task)
elif op == 'wait_write':
self.sel.register(arg, selectors.EVENT_WRITE, task)
else:
raise ValueError('Unknown event loop operation:', op)
else:
for key, _ in self.sel.select():
task = key.data
sock = key.fileobj
self.sel.unregister(sock)
self.create_task(task)
What do we get out of it? First, we get the server that handles multiple clients perfectly fine:
$ python clients.py
[00.160966] Client 0 tries to connect.
[00.161494] Client 1 tries to connect.
[00.161783] Client 2 tries to connect.
[00.163256] Client 0 connects.
[00.163409] Client 1 connects.
[00.163470] Client 2 connects.
[00.667343] Client 0 sends "Hello".
[00.667491] Client 1 sends "Hello".
[00.667609] Client 2 sends "Hello".
[00.667886] Client 0 receives "Hello".
[00.668160] Client 1 receives "Hello".
[00.668237] Client 2 receives "Hello".
[01.171159] Client 0 sends "world!".
[01.171320] Client 1 sends "world!".
[01.171439] Client 2 sends "world!".
[01.171610] Client 0 receives "world!".
[01.171839] Client 0 disconnects.
[01.172084] Client 1 receives "world!".
[01.172154] Client 1 disconnects.
[01.172190] Client 2 receives "world!".
[01.172237] Client 2 disconnects.
Second, we get the code that looks like regular sequential code. Of course, we had to write the event loop, but this is not something you typically do yourself. Event loops come with libraries, and in Python you're most likely to use an event loop that comes with asyncio.
When you use generators for multitasking, as we did in this section, you typically refer to them as coroutines. Coroutines are functions that can be suspended by explicitly yielding the control. So, according to this definition, simple generators with yield expressions can be counted as coroutines. A true coroutine, however, should also be able to yield the control to other coroutines by calling them, but generators can yield the control only to the caller.
We'll see why we need true coroutines if try to factor out some generator's code into a subgenerator. Consider these two lines of code of the handle_client() generator:
yield 'wait_read', sock
received_data = sock.recv(4096)
It would be very handy to factor them out into a separate function:
def async_recv(sock, n):
yield 'wait_read', sock
return sock.recv(n)
and then call the function like this:
received_data = async_recv(sock, 4096)
But it won't work. The async_recv() function returns a generator, not the data. So the handle_client() generator has to run the async_recv() subgenerator with next(). However, it can't just keep calling next() until the subgenerator is exhausted. The subgenerator yields values to the event loop, so handle_client() has to reyield them. It also has to handle the StopIteration exception and extract the result. Obviously, the amount of work that it has to do exceeds all the benefits of factoring out two lines of code.
Python made several attempts at solving this issue. First, PEP 342 introduced enhanced generators in Python 2.5. Generators got the send() method that works like __next__() but also sends a value to the generator. The value becomes the value of the yield expression that the generator is suspended on:
>>> def consumer():
... val = yield 1
... print('Got', val)
... val = yield
... print('Got', val)
...
>>> c = consumer()
>>> next(c)
1
>>> c.send(2)
Got 2
>>> c.send(3)
Got 3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
The generators' __next__() method became simply a shorthand for send(None).
Generators also got the throw() method that runs the generator like send() or __next__() but also raises a specified exception at the suspension point and the close() method that raises a GeneratorExit exception.
Here's how this enhancement solved the subgenerator issue. Instead of running a subgenerator in place, a generator could now yield it to the event loop, and the event loop would run the subgenerator and then send() the result back to the generator (or throw an exception into the generator if the subgenerator raised one). The generator would call the subgenerator like this:
received_data = yield async_recv(sock)
And this call would work just as if one coroutine calls another.
This solution requires some non-trivial logic in the event loop, and you may find it hard to understand. Don't worry. You don't have to. PEP 380 introduced a much more intuitive solution for implementing coroutines in Python 3.3.
yield from
You've probably used yield from to yield values from an iterable. So you should know that this statement:
yield from iterable
works as a shorthand for this piece of code:
for i in iterable:
yield i
But yield from does much more when you use it with generators. It does exactly what a generator has to do to run a subgenerator in place, and that's why we're discussing it. The main steps of yield from are:
- Run the subgenerator once with
send(None). Ifsend()raises aStopIterationexception, catch the exception, extract the result, make it a value of theyield fromexpression and stop. - If subgenerator's
send()returns a value without exceptions,yieldthe value and receive a value sent to the generator. - When received a value, repeat step 1 but this time
send()the received value.
This algorithm requires some elaboration. First, yield from automatically propagates exceptions thrown by calling the generator's throw() and close() methods into the subgenerator. The implementation of these methods ensures this. Second, yield from applies the same algorithm to non-generator iterables except that it gets an iterator with iter(iterable) and then uses __next__() instead send() to run the iterator.
Here's how you can remember what yield from does: it makes the subgenerator work as if the subgenerator's code were a part of the generator. So this yield from call:
received_data = yield from async_recv(sock)
works as if the call were replaced with the code of async_recv(). This also counts as a coroutine call, and in contrast to the previous yield-based solution, the event loop logic stays the same.
Let's now take advantage of yield from to make the server's code more concise. First we factor out every boilerplate yield statement and the following socket operation to a separate generator function. We put these functions in the event loop:
# event_loop_03_yield_from.py
from collections import deque
import selectors
class EventLoopYieldFrom:
def __init__(self):
self.tasks_to_run = deque([])
self.sel = selectors.DefaultSelector()
def create_task(self, coro):
self.tasks_to_run.append(coro)
def sock_recv(self, sock, n):
yield 'wait_read', sock
return sock.recv(n)
def sock_sendall(self, sock, data):
yield 'wait_write', sock
sock.sendall(data)
def sock_accept(self, sock):
yield 'wait_read', sock
return sock.accept()
def run(self):
while True:
if self.tasks_to_run:
task = self.tasks_to_run.popleft()
try:
op, arg = next(task)
except StopIteration:
continue
if op == 'wait_read':
self.sel.register(arg, selectors.EVENT_READ, task)
elif op == 'wait_write':
self.sel.register(arg, selectors.EVENT_WRITE, task)
else:
raise ValueError('Unknown event loop operation:', op)
else:
for key, _ in self.sel.select():
task = key.data
sock = key.fileobj
self.sel.unregister(sock)
self.create_task(task)
Then we yield from the generators in the server's code:
# echo_07_yield_from.py
import socket
from event_loop_03_yield_from import EventLoopYieldFrom
loop = EventLoopYieldFrom()
def run_server(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
while True:
client_sock, addr = yield from loop.sock_accept(sock)
print('Connection from', addr)
loop.create_task(handle_client(client_sock))
def handle_client(sock):
while True:
received_data = yield from loop.sock_recv(sock, 4096)
if not received_data:
break
yield from loop.sock_sendall(sock, received_data)
print('Client disconnected:', sock.getpeername())
sock.close()
if __name__ == '__main__':
loop.create_task(run_server())
loop.run()
And that's it! Generators, yield and yield from are all we need to implement coroutines, and coroutines allow us to write asynchronous, concurrent code that looks like regular sequential code. What about async/await? Well, it's just a syntactic feature on top of generators that was introduced to Python to fix the generators' ambiguity.
async/await
When you see a generator function, you cannot always say immediately whether it's intended to be used as a regular generator or as a coroutine. In both cases, the function looks like any other function defined with def and contains a bunch of yield and yield from expressions. So to make coroutines a distinct concept, PEP 492 introduced the async and await keywords in Python 3.5.
You define a native coroutine function using the async def syntax:
>>> async def coro():
... return 1
...
When you call such a function, it returns a native coroutine object, or simply a native coroutine. A native coroutine is pretty much the same thing as a generator except that it has a different type and doesn't implement __next__(). Event loops call send(None) to run native coroutines:
>>> coro().send(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration: 1
Native coroutines can call each other with the await keyword:
>>> async def coro2():
... r = await coro()
... return 1 + r
...
>>> coro2().send(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration: 2
The await keyword does exactly what yield from does but for native coroutines. In fact, await is implemented as yield from with some additional checks to ensure that the object being awaited is not a generator or some other iterable.
When you use generators as coroutines, you must end every chain of yield from calls with a generator that does yield. Similarly, you must end every chain of await calls with a yield expression. However, if you try to use a yield expression in an async def function, what you'll get is not a native coroutine but something called an asynchronous generator:
>>> async def g():
... yield 2
...
>>> g()
<async_generator object g at 0x1046c6790>
We're not going spend time on asynchronous generators here, but in a nutshell, they implement the asynchronous version of the iterator protocol: the __aiter__() and __anext__() special methods (see PEP 525 to learn more). What's important for us at now is that __anext__() is awaitable, while asynchronous generators themeselves are not. Thus, we cannot end a chain of await calls with an async def function containing yield. What should we end the chain with? There are two options.
First, we can write a regular generator function and decorate it with @types.coroutine. This decorator sets a special flag on the function behind the generator so that the generator can be used in an await expression just like a native coroutine:
>>> import types
>>> @types.coroutine
... def gen_coro():
... yield 3
...
>>> async def coro3():
... await gen_coro()
...
>>> coro3().send(None)
3
A generator decorated with @types.coroutine is called a generator-based coroutine. Why do we need such coroutines? Well, if Python allowed us to await on regular generators, we would again mix the concepts of generators and coroutines and come back to the same ambiguity problem. The @types.coroutine decorator explicitly says that the generator is a coroutine.
As a second option, we can make any object awaitable by defining the __await__() special method. When we await on some object, await first checks whether the object is a native coroutine or a generator-based coroutine, in which case it "yields from" the coroutine. Otherwise, it "yields from" the iterator returned by the object's __await__() method. Since any generator is an iterator, __await__() can be a regular generator function:
>>> class A:
... def __await__(self):
... yield 4
...
>>> async def coro4():
... await A()
...
>>> coro4().send(None)
4
Let's now write the final version of the server using async/await. First we mark the server's functions as async and change yield from calls to await calls:
# echo_08_async_await.py
import socket
from event_loop_04_async_await import EventLoopAsyncAwait
loop = EventLoopAsyncAwait()
async def run_server(host='127.0.0.1', port=55555):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen()
while True:
client_sock, addr = await loop.sock_accept(sock)
print('Connection from', addr)
loop.create_task(handle_client(client_sock))
async def handle_client(sock):
while True:
received_data = await loop.sock_recv(sock, 4096)
if not received_data:
break
await loop.sock_sendall(sock, received_data)
print('Client disconnected:', sock.getpeername())
sock.close()
if __name__ == '__main__':
loop.create_task(run_server())
loop.run()
Then we modify the event loop. We decorate generator functions with @types.coroutine so that they can be used with await and run the tasks by calling send(None) instead of next():
# event_loop_04_async_await.py
from collections import deque
import selectors
import types
class EventLoopAsyncAwait:
def __init__(self):
self.tasks_to_run = deque([])
self.sel = selectors.DefaultSelector()
def create_task(self, coro):
self.tasks_to_run.append(coro)
@types.coroutine
def sock_recv(self, sock, n):
yield 'wait_read', sock
return sock.recv(n)
@types.coroutine
def sock_sendall(self, sock, data):
yield 'wait_write', sock
sock.sendall(data)
@types.coroutine
def sock_accept(self, sock):
yield 'wait_read', sock
return sock.accept()
def run(self):
while True:
if self.tasks_to_run:
task = self.tasks_to_run.popleft()
try:
op, arg = task.send(None)
except StopIteration:
continue
if op == 'wait_read':
self.sel.register(arg, selectors.EVENT_READ, task)
elif op == 'wait_write':
self.sel.register(arg, selectors.EVENT_WRITE, task)
else:
raise ValueError('Unknown event loop operation:', op)
else:
for key, _ in self.sel.select():
task = key.data
sock = key.fileobj
self.sel.unregister(sock)
self.create_task(task)
And we're done! We've implemented an async/await-based concurrent server from scratch. It works exactly like the previous version of the server based on yield from and only has a slightly different syntax.
By now, you should understand what async/await is about. But you also should have questions about implementation details of generators, coroutines, yield, yield from and await. We're going to cover all of that in the next section.
How generators and coroutines are implemented *
If you've been following this series, you effectively know how Python implements generators. First recall that the compiler creates a code object for every code block that it encounters, where a code block can be a module, a function or a class body. A code object describes what the code block does. It contains the block's bytecode, constants, variable names and other relevant information. A function is an object that stores the function's code object and such things as the function's name, default arguments and __doc__ attribute.
A generator function is an ordinary function whose code object has a CO_GENERATOR flag set. When you call a generator function, Python checks for this flag, and if it sees the flag, it returns a generator object instead of executing the function. Similarly, a native coroutine function is an ordinary function whose code object has a CO_COROUTINE flag set. Python check for this flag too and returns a native coroutine object if it sees the flag.
To execute a function, Python first creates a frame for it and then executes the frame. A frame is an object that captures the state of the code object execution. It stores the code object itself as well as the values of local variables, the references to the dictionaries of global and built-in variables, the value stack, the instruction pointer and so on.
A generator object stores the frame created for the generator function and some utility data like the generator's name and a flag telling whether the generator is currently running or not. The generator's send() method executes the generator's frame just like Python executes frames of ordinary functions – it calls _PyEval_EvalFrameDefault() to enter the evaluation loop. The evaluation loop iterates over the bytecode instructions one by one and does whatever the instructions tell it to do. The only but crucial difference between calling a function and running a generator is that every time you call the function, Python creates a new frame for it, while the generator keeps the same frame between the runs, thus preserving the state.
How does Python execute yield expressions? Let's see. Every time the compiler encounters yield, it emits a YIELD_VALUE bytecode instruction. We can use the dis standard module to check this:
# yield.py
def g():
yield 1
val = yield 2
return 3
$ python -m dis yield.py
...
Disassembly of <code object g at 0x105b1c710, file "yield.py", line 3>:
4 0 LOAD_CONST 1 (1)
2 YIELD_VALUE
4 POP_TOP
5 6 LOAD_CONST 2 (2)
8 YIELD_VALUE
10 STORE_FAST 0 (val)
6 12 LOAD_CONST 3 (3)
14 RETURN_VALUE
YIELD_VALUE tells the evaluation loop to stop executing the frame and return the value on top of the stack (to send() in our case). It works like a RETURN_VALUE instruction produced for a return statement with one exception. It sets the f_stacktop field of the frame to the top of the stack, whereas RETURN_VALUE leaves f_stacktop set to NULL. By this mechanism, send() understands whether the generator yielded or returned the value. In the first case, send() simply returns the value. In the second case, it raises a StopIteration exception that contains the value.
When send() executes a frame for the first time, it doesn't actually sends the provided argument to the generator. But it ensures that the argument is None so that a meaningful value is never ignored:
>>> def g():
... val = yield
...
>>> g().send(42)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't send non-None value to a just-started generator
On subsequent runs, send() pushes the argument onto the stack. The argument is then assigned to a variable by STORE_FAST (or similar instruction) or just popped by POP_TOP if yield does not receive a value. If you couldn't remember before whether generators first yield or receive, you should remember now: first YIELD_VALUE, then STORE_FAST.
The compiler emits GET_YIELD_FROM_ITER, LOAD_CONST and YIELD_FROM instructions when it encounters yield from:
# yield_from.py
def g():
res = yield from another_gen
$ python -m dis yield_from.py
...
Disassembly of <code object g at 0x1051117c0, file "yield_from.py", line 3>:
4 0 LOAD_GLOBAL 0 (another_gen)
2 GET_YIELD_FROM_ITER
4 LOAD_CONST 0 (None)
6 YIELD_FROM
8 STORE_FAST 0 (res)
...
The job of GET_YIELD_FROM_ITER is to ensure that the object to yield from, which is the value on top of the stack, is an iterator. If the object is a generator, GET_YIELD_FROM_ITER leaves it as is. Otherwise, GET_YIELD_FROM_ITER replaces the object with iter(obj).
The first thing YIELD_FROM does is pop a value from the stack. Usually, this value is a value pushed by send(). But send() pushes nothing on the first run, so the compiler emits a LOAD_CONST instruction that pushes None before YIELD_FROM.
The second thing YIELD_FROM does is peek the object to yield from. If the value to send is None, YIELD_FROM calls obj.__next__(). Otherwise, it calls obj.send(value). If the call raises a StopIteration exception, YIELD_FROM handles the exception: it replaces the object on top of the stack (i.e. the object to yield from) with the result, and the frame execution continues. If the call returns a value without exceptions, YIELD_FROM stops the frame execution and returns the value to send(). In the latter case, it also sets the instruction pointer in such a way so that the next execution of the frame starts with YIELD_FROM again. What will be different on the subsequent runs is the state of the object to yield from and the value to send.
A native coroutine is basically a generator object that has a different type. The difference between the types is that the generator type implements __iter__() and __next__(), while the coroutine type implements __await__(). The implementation of send() is the same.
The compiler emits the same bytecode instructions for an await expression as for yield from except that instead of a GET_YIELD_FROM_ITER instruction it emits GET_AWAITABLE:
# await.py
async def coro():
res = await another_coro
$ python -m dis await.py
...
Disassembly of <code object coro at 0x10d96e7c0, file "await.py", line 3>:
4 0 LOAD_GLOBAL 0 (another_coro)
2 GET_AWAITABLE
4 LOAD_CONST 0 (None)
6 YIELD_FROM
8 STORE_FAST 0 (res)
...
GET_AWAITABLE checks whether the object to yield from is a native coroutine or a generator-based coroutine, in which case it leaves the object as is. Otherwise, it replaces the object with obj.__await__().
That's basically how generators and coroutines work. If you still have questions left, I recommend you study the CPython source code. See Include/cpython/code.h for the code object definition, Include/funcobject.h for the function object definition and Include/cpython/frameobject.h for the frame definition. Look at Objects/genobject.c to learn more about generators and coroutines, and look at Python/ceval.c to learn what different bytecode instructions do.
We've figured out how async/await works, but we also need an event loop to run async/await programs. You're unlikely to write your own event loops as we did in this post because that's a lot work. What you usually do instead is use some event loop library. So before we conclude this post, let me say a few words about the library you're most likely to use.
asyncio
asyncio came to the Python standard library around the same time async/await was introduced (see PEP 3156). It does a lot of things, but essentially it provides an event loop and a bunch of classes, functions and coroutines for asynchronous programming.
The asyncio event loop provides an interface similar to that of our final EventLoopAsyncAwait but works a bit differently. Recall that our event loop maintained a queue of scheduled coroutines and ran them by calling send(None). When a coroutine yielded a value, the event loop interpreted the value as an (event, socket) message telling that the coroutine waits for event on socket. The event loop then started monitoring the socket with a selector and rescheduled the coroutine when the event happened.
The asyncio event loop is different in that it does not maintain a queue of scheduled coroutines but only schedules and invokes callbacks. Nevertheless, it provides loop.create_task() and other methods to schedule and run coroutines. How does it do that? Let's see.
The event loop maintains three types of registered callbacks:
The ready callbacks. These are stored in the
loop._readyqueue and can be scheduled by calling theloop.call_soon()andloop.call_soon_threadsafe()methods.The callbacks that become ready at some future time. These are stored in the
loop._scheduledpriority queue and can be scheduled by calling theloop.call_later()andloop.call_at()methods.- The callbacks that become ready when a file descriptor becomes ready for reading or writing. These are monitored using a selector and can be registered by calling the
loop.add_reader()andloop.add_writer()methods.
The methods listed above wrap the callback to be scheduled in a Handle or a TimerHandle instance and then schedule and return the handle. Handle instances provide the handle.cancel() method that allows the caller to cancel the callback. TimerHandle is a subclass of Handle for wrapping callbacks scheduled at some future time. It implements the comparison special methods like __le__() so that the sooner a callback is scheduled the less it is. Due to TimerHandle, the loop._scheduled priority queue keeps callbacks sorted by time.
The loop._run_once() method runs one iteration of the event loop. The iteration consists of the following steps:
- Remove cancelled callbacks from
loop._scheduled. - Call
loop._selector.select()and then process the events by adding the callbacks toloop._ready. - Move callbacks whose time has come from
loop._scheduledtoloop._ready. - Pop callbacks from
loop._readyand invoke those that are not cancelled.
So, how does this callback-based event loop run coroutines? Let's take a look at the loop.create_task() method. To schedule a coroutine, it wraps the coroutine in a Task instance. The Task.__init__() method schedules task.__step() as a callback by calling loop.call_soon(). And this is the trick: task.__step() runs the coroutine.
The task.__step() method runs the coroutine once by calling coro.send(None). The coroutine doesn't yield messages. It can yield either None or a Future instance. None means that the coroutine simply wants to yield the control. This is what asyncio.sleep(0) does, for example. If a coroutine yields None, task.__step() simply reschedules itself.
A Future instance represents the result of some operation that may not be available yet. When a coroutine yields a future, it basically tells the event loop: "I'm waiting for this result. It may not be available yet, so I'm yielding the control. Wake me up when the result becomes available".
What does task.__step() do with a future? It calls future.add_done_callback() to add to the future a callback that reschedules task.__step(). If the result is already available, the callback is invoked immediately. Otherwise, it's invoked when someone/something sets the result by calling future.set_result().
Native coroutines cannot yield. Does it mean that we have to write a generator-based coroutine any time we need to yield a future? No. Native coroutines can simply await on futures, like so:
async def future_waiter():
res = await some_future
To support this, futures implement __await__() that yields the future itself and then returns the result:
class Future:
# ...
def __await__(self):
if not self.done():
self._asyncio_future_blocking = True
yield self # This tells Task to wait for completion.
if not self.done():
raise RuntimeError("await wasn't used with future")
return self.result() # May raise too.
What sets the result on a future? Let's take a function that creates a future for the socket incoming data as an example. Such a function can be implemented as follows:
- Create a new
Futureinstance. - Call
loop.add_reader()to register a callback for the socket. The callback should read data from the socket and set the data as the future's result. - Return the future to the caller.
When a task awaits on this future, it will yield the future to task.__step(). The task.__step() method will add a callback to the future, and this callback will reschedule the task when the callback from step 2 sets the result.
We know that a coroutine can wait for the result of another coroutine by awaiting on that coroutine:
async def coro():
res = await another_coro()
But it can also schedule the coroutine, get a Task instance and then await on the task:
async def coro():
task = asyncio.create_task(another_coro())
res = await task
Task subclasses Future so that tasks can be awaited on. What sets the result on a task? It's task.__step(). If coro.send(None) raises a StopIteration exception, task.__step() handles the exception and sets the task's result.
And that's basically how the core of asyncio works. There two facts about it that we should remember. First, the event loop is based on callbacks, and the coroutine support is implemented on top of that. Second, coroutines do not yield messages to the event loop but yield futures. Futures allow coroutines to wait for different things, not only for I/O events. For example, a coroutine may submit a long-running computation to a separate thread and await on a future that represents the result of the computation. We could implement such a coroutine on top of sockets, but it would be less elegant and general than the solution with a future.
Conclusion
The async/await pattern has gained popularity in recent years. Concurrency is as relevant today as ever, and traditional approaches for achieving it, such as OS threads and callbacks, cannot always provide an adequate solution. OS threads work fine in some cases, but in many other cases the concurrency can be implemented much better at the language/application level. A callback-based event loop is technically as good as any async/await solution, but who likes writing callbacks?
It's not to say that async/await is the only right approach to concurrency. Many find other approaches to be better. Take the communicating sequential processes model implemented in Go and Clojure or the actor model implemented in Erlang and Akka as examples. Still, async/await seems to be the best model we have in Python today.
Python didn't invent async/await. You can also find it in C#, JavaScript, Rust, and Swift, to name a few. I'm biased towards Python's implementation because I understand it best, but objectively, it's not the most refined. It mixes generators, generator-based coroutines, native coroutines, yield from and await, which makes it harder to understand. Nevertheless, once you understand these concepts, Python's async/await seems pretty straightforward.
asyncio is a solid library, but it has its issues. The callback-based event loop allows asyncio to provide an API for both callback-style and async/await-style programming. But an event-loop that runs coroutines directly, like those that we wrote in this post, can be much simpler in both implementation and usage. The curio and trio modules are notable alternatives to asyncio that take this approach.
To sum up, concurrency is inherently hard, and no programming model can make it easy. Some models make it manageable, though, and this post should help you master one such model – Python's async/await.
P.S.
The code for this post is available on github. The post is inspired by David Beazley's Curious Course on Coroutines and Concurrency talk and by Eli Bendersky's Concurrent Servers series.
async/await completes the list of topics I wanted to cover in the Python behind the scenes series. I'm now planning to write about other interesting things, but the series is likely to get a sequel in the future. If you want to suggest a topic for the next post, you can write me an email to victor@tenthousandmeters.com.
If you have any questions, comments or suggestions, feel free to contact me at victor@tenthousandmeters.com
Update from August 27, 2021: [1] The relationship between concurrency and parallelism is more subtle. Usually, concurrency is viewed as a property of a program and parallelism as a property of a program execution. Thus, you can have "parallelism without concurrency" – even the execution of a sequentially-looking program involves instruction-level or bit-level parallelism. Task-level parallelism is indeed a special case of concurrency.




No comments:
Post a Comment