The FIRST and LAST (a.k.a. “KEEP”) aggregate functions are very useful when you want to order a row set by one column and return the value of another column from the first or last row in the ordered set. I wrote about these functions in the past; for example here and here.
To make sure the result of the FIRST (LAST) function is deterministic, we have to define a tie-breaker for the case that multiple rows have the same first (last) value. The tie-breaker is an aggregate function that is applied on the column we want to return.
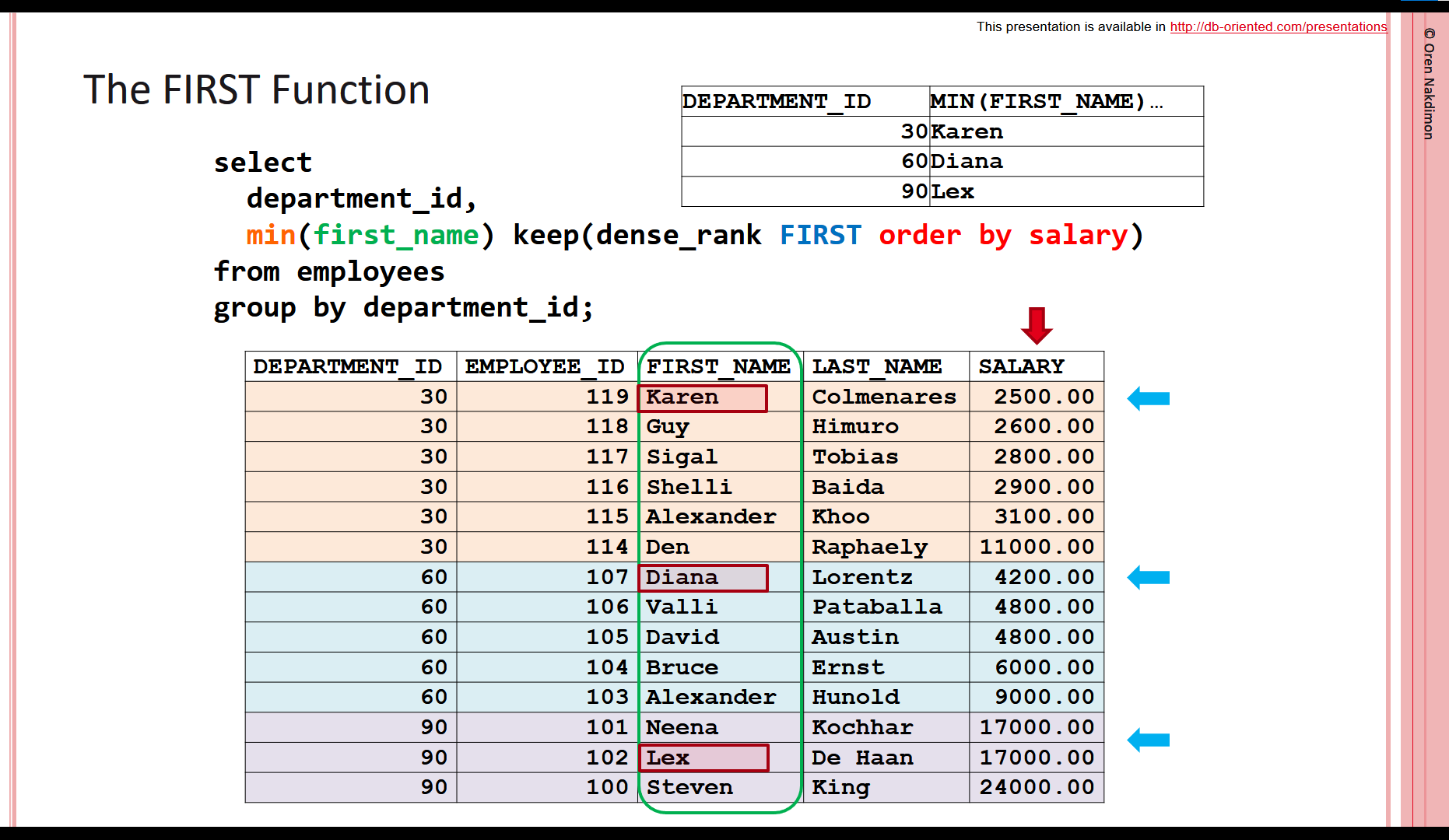
For example, the following query returns for each department the FIRST_NAME of the employee with the lowest SALARY. If there are multiple employees with the lowest salary in the same department, the query returns the “minimum” first_name – so here the MIN function is the tie-breaker. In this example the lowest salary in department 90 is 17000, and both Neena and Lex have this salary. We use MIN(FIRST_NAME), so the result is “Lex”. Many times we don’t really need a tie-breaker, because we know that there is a single first/last row. For example, if we use a unique expression in the ORDER BY clause of the function. And sometimes we simply don’t care which record is returned in case of a tie. But since the syntax requires a tie-breaker, we have to use some “random” function, like MIN or MAX.
The ANY_VALUE function (that was added in Oracle 19c) is perfect, in my opinion, for this case. It may improve performance, but – more importantly – it makes the code clearer, by better reflecting our intention. Assuming that in the previous example we don’t care which one of the employees with the lowest salary is returned, we can rewrite it like this:
select
department_id,
any_value(first_name) keep(dense_rank FIRST order by salary)
from employees
group by department_id;
One thought on “ANY_VALUE and FIRST/LAST (KEEP)”
Hi Oren,
It is interesting that the ANY_VALUE function is a “legal aggregate” for the FIRST/LAST functions, though not specified explicitly in the documentation
While it is true that the aggregate used here is usually supposed to be a “tie breaker”, just as MIN and MAX obviously are, however, the FIRST/LAST functions, as documented, also work with some “non-tie-breaker” aggregates like SUM, AVG or COUNT that may be considered as FIRST/LAST “accumulators”.
But, they do not work with other undocumented aggregates like MEDIAN or LISTAGG, which look equally legitimate as all the documented ones:
Both of the following queries return error:
select
department_id,
MEDIAN(hire_date)
keep(dense_rank FIRST order by salary)
from hr.employees
group by department_id
/
ORA-00923: FROM keyword not found where expected
select
department_id,
LISTAGG(first_name,',') WITHIN GROUP (order by first_name)
keep(dense_rank FIRST order by salary)
from hr.employees
group by department_id
/
ORA-00923: FROM keyword not found where expected
The COLLECT function, instead, does not raise an error, but wrongly returns a NULL collection when there are “ties” in the FIRST/LAST rows, as we can see here, for department_id = 90.
For groups without ties, it returns a correct collection containing the single FIRST/LAST value, similar to MIN/MAX ( we don’t see it here, because LiveSQL does not display collection types output properly, without a converting helper function ):
select
department_id,
count(*) keep(dense_rank FIRST order by salary) cnt,
min(first_name) keep(dense_rank FIRST order by salary) low,
max(first_name) keep(dense_rank FIRST order by salary) high,
COLLECT(first_name) keep(dense_rank FIRST order by salary) coll,
CASE
WHEN COLLECT(first_name) keep(dense_rank FIRST order by salary) IS NULL THEN '***'
END null_coll
from hr.employees
group by department_id
/
DEPARTMENT_ID CNT LOW HIGH COLL NULL_COLL
-----------------------------------------------------------------------------------------
10 1 Jennifer Jennifer [unsupported data type] -
20 1 Pat Pat [unsupported data type] -
30 1 Karen Karen [unsupported data type] -
40 1 Susan Susan [unsupported data type] -
50 1 TJ TJ [unsupported data type] -
60 1 Diana Diana [unsupported data type] -
70 1 Hermann Hermann [unsupported data type] -
80 1 Sundita Sundita [unsupported data type] -
90 2 Lex Neena [unsupported data type] ***
100 1 Luis Luis [unsupported data type] -
110 1 William William [unsupported data type] -
- 1 Kimberely Kimberely [unsupported data type] -
12 rows selected.
So, it looks like some documentation adjustments are still required for the FIRST/LAST functions, as well as some enhancements to allow for additional “tie accumulator” aggregates to be used.
Why do you do code reviews? Perhaps it’s company policy, just an automatic part of your process, but have you ever sat down with your team and asked what everyone hopes to get out of it?
As a developer, has it ever felt like playing a strange board game where the rules are secret and keep on changing? Or as a delivery manager, have you ever been puzzled why reviews sometimes seems to take longer than writing the code itself?
These are some of the things we were asking ourselves at BBC News a year ago. We’re not sure we’ve found all the answers yet. But we think what we’ve learned so far has improved our engineering culture and helped to make code reviews a better experience for everyone.
In this post I’ll share why we started asking these questions, and some of the things we found out along the way.
Our first taste of remote-first working
Throughout 2019 the teams working on the BBC News and World Service websites went through a period of rapid expansion and changing priorities. What had started out as a close-knit team of five building a reimagined articles page for BBC News ended up with 35 engineers across five teams contributing to the same product.
There were other changes. At the start of the year, everyone was co-located around the same bank of desks at Broadcasting House in London. Instant feedback and advice were usually available by turning to the person sat next to you, and pairing came relatively easily.
By December however, the engineers were split across six geographical locations in three time zones. While nobody could have imagined the upheavals of 2020 that lay ahead, we found ourselves having to adapt to a remote-first culture rapidly.
Growing pains
Despite the stresses of scaling sevenfold in a matter of months, the teams made a great success of the changes: by mid-2020 we had successfully rebuilt a set of sites that deliver free and impartial journalism to 35m unique visitors globally per week (for an overview of the BBC’s cloud journey see Matthew Clark’s recent post, and for the performance improvements in the new sites see Chris Hinds’ post here).
But there were definitely challenges along the way, and one area that was often raised as a source of difficulties was peer code reviews. A large influx of engineers from other teams, most of whom were learning about the codebases for the first time, started opening pull requests (PRs) to get feedback on their work.
We saw that these PRs would sometimes spend considerable time in the code review stage, often cycling between review and re-work multiple times. Approaches to giving and receiving reviews seemed inconsistent. Some developers reported that they found the process unclear, and at times stressful.
It was clear it was time to talk and reflect as an engineering community. We started asking what this ‘code review’ thing we were doing automatically was actually for. We decided we needed a kind of charter for code reviews.
The answer was twofold. Firstly, we wanted to create a shared, living document that would evolve over time as we learned more about what works and does not work for our teams.
Secondly, while existing resources offer many useful global principles, a lot of the questions we had required local answers, specific to the structure of our organisation, our codebases and the design of our automated tooling and Continuous Delivery processes. For example: who can ‘approve’ a PR? Do all types of changes get reviewed in the same way (documentation, config, infrastructure code etc.)?
As Gergely Orosz points out, having an engineer-initiated guide to code reviewing is one hallmark of organisational support for the practice. So we started an anonymous collaborative document to source ideas, frank observations and anecdotes about code reviews from engineers of all levels of experience. Then, with feedback and advice from a range of viewpoints we gradually distilled that advice into our guide.
We wanted to make sure that the guide was easy to discover and would continue to be updated, so we put it right into our repositories and linked to it from our top-level READMEs and PR templates.
And as an added bonus, the project we were working on is open source, meaning that potential contributors from outside the BBC benefit from more transparency about how we aim to review contributions.
A quick quiz
What’s the goal of doing code reviews? Is it:
To catch defects before they reach production
To share knowledge about helpful patterns and best practices
To discuss alternative approaches and viewpoints
To allow developers of all levels of experience to learn
To link to useful documentation and other resources
To distribute knowledge across the team
To ask questions and check understanding
To improve readability and maintainability of the code
To identify documentation needs
To ensure that work meets quality standards
To record the rationale for certain changes
To coach and mentor junior developers
To promote sharing ownership of the codebase
To notify other affected teams of changes that are being made
All of the above
If you answered “all of the above,” you’ve come to the same conclusion that we did.
We’ve seen over and again that a good code review can achieve all of the above and more (which is not to say that code reviews are the only way to achieve these things). Participating in code reviews in a spirit of open, egoless collaboration is the key to unlocking all of these benefits.
In fact, we sometimes wonder if catching defects isone ofthe weakest arguments for code reviews, at least in the relatively unstructured way we do them. Think about the last time a bug hit production and caused you a problem, perhaps because of something as trivial as a typo in some config. Could it realistically have been caught during code review? Was it? The truth is that busy developers are not always great at playing ‘spot the difference’.
By the way, the idea that there is a discrepancy between what we expect from code reviews and what they actually achieve is not a new one. An empirical analysis of hundreds of code reviews at Microsoft in 2013 found that sharing understanding and social communication were more common outcomes than finding defects.
What we learned from the process
A few of the most interesting themes that emerged from our reading and internal discussions are summarised below. For more context, see the full guide linked to at the end of this section.
Reviewing code is a first-class activity
We think learning to review code well is as important as learning to write it well. Code reviews are not a second-class activity, to be squeezed in between ‘real’ work. We allow sufficient time in our planning and estimates to allow it to take place, and we don’t neglect it in emergencies, as the cost of haste at these times can be even greater. We actively nurture and develop the skill of reviewing in engineers of all levels.
Communication is at the heart of code review
As mentioned earlier, often the real benefits of code reviews are communication and understanding. GitHub is a powerful collaboration tool but not the only one at our disposal. Jumping on a Zoom or Teams call to talk it through can be friendlier and more efficient than back-and-forth debates on PRs.
This is especially important for growing, distributed teams where there is greater scope for confusion and misunderstandings. We also find group (aka swarm) code reviews effective, especially for significant new abstractions.
Our primary aim in participating in code reviews is to learn from each other, increasing our understanding of the codebase we are responsible for and of the technologies we use.
Code reviews aren’t just about getting a rubber stamp of approval from someone (often written LGTM, or Looks Good To Me). Every code review is an opportunity to ask questions, share knowledge and consider alternative ways of doing things. Done properly, both authors and reviewers can expect to learn and grow from this process.
And if potential bugs are caught along the way, that’s awesome too.
Remember to be kind
Code reviews can be emotionally demanding for both sides. Pride can come into play — authors may have spent a lot of time preparing their changes, and others may be protective of a codebase.
Taking a cue from the Agile retrospectives Prime Directive, we assume that everyone did the best job they could, given what they knew at the time and the resources available. As we found, trying always to understand the other person’s perspective is particularly critical when new team members are contributing to an established codebase.
Many of us have seen cases where a review hasn’t gone so well. A high comment count, multiple revision cycles and comments that have forgotten to be kind are all warning signs that team leads should be watching out for.
Time spent on code review should be kept in proportion with other stages of the development life cycle including testing and accessibility and UX review.
We find that as a rule of thumb, if a change has spent longer in review than it took to implement the code that might also point to a wider problem that needs attention. Are team members prioritising reviews correctly? If there are lengthy conversations, perhaps some of them could have happened earlier in the process?
It may also be helpful for dev teams to regularly reflect on reviews which were harder or less effective than they should have been.
Look for every opportunity to make reviews easier
We’ve noticed that changes that have been authored by two engineers pairing or a larger group swarming often seem to spend less time in code review, with fewer review cycles. This makes sense given the above points about communication, as a lot of potential questions and concerns can be pre-empted, and the change should have already benefited from a more diverse range of skills and viewpoints.
And as April Wensel suggests, automate what you can, for example using linters effectively to minimise trivial nitpicks.
There are many potential benefits to doing code reviews, but they are not always what people expect, and there are pitfalls along the way too. Even so, not all teams will need or want to go through the process of reflection described above. Perhaps tacit assumptions about code reviews are working great for you, or you find one of the existing online resources sufficient.
But in the spirit of continuous improvement and trying to make the way we collaborate more transparent, we found writing our guide a really positive experience. And with remote working now the norm, having a clear shared understanding of these activities is more vital than ever.
The document is now part of our onboarding process for new engineers, and we’ve seen promising feedback about the cultural benefits that talking frankly about code reviews has made.
But the journey doesn’t end there — we’ll continue to update our guide as we learn more about what works for our teams. Sometimes it’s only by asking difficult questions about every stage in our development process that we can really improve the way we build software together.
Do you know that you can take the courses from MIT, Stanford, and Harvard for free? Lots of their undergraduate and graduate-level course materials are for the students around the globe to use for free. I am going to talk about some of the resources here. I know there are so many very bright and talented students in the different parts of the world who cannot go to all those great schools. But they have the potential to learn. In the tech industry, you can get a job even in Google, without a tech degree. Only the knowledge matters. If you are interested to put the time and effort, you can become a tech giant even if you cannot go to a big school. Here are the resources.
MIT
You will be amazed to know that you almost can get the course materials of all the undergraduate and graduate-level computer science courses free. You will find courses from all the areas of computer science including:
introduction to computer science and electrical engineering,
This is a huge piece of gold if you are looking to learn online in any tech field and also other fields. I am only focusing on tech learning. You can take high-quality courses from big-name universities for free.
Search for your interest area in the search bar. You can audit the courses or pay to get a certificate. If you audit the courses, you will be able to learn but won’t get a certificate. If you go to the course from the catalog page, a lot of courses will say an amount per month or audit for free.
To find the audit option, click on the ‘Take Course’ button. On this page, there is the audit option.
Coursera
Another huge resource. There is a big pool of courses from all the well-known universities and well-known professors. You can learn almost all the areas I mentioned in the edx section. You just have choices. Try both edx and Coursera. Choose which works best for you.
In Coursera also, you can pay to get a certificate or audit the course to learn only. But finding the audit option is a bit trickier here. I am explaining here.
In the course description page, you will see the ‘Enroll’ option. But do not enroll from there. It will give only 7 days for free. Scroll down to the bottom of the page. You will find another ‘Enroll’ option. Click on that. A window will pop up. At the bottom of that window, you will see a small audit option. That’s what you are looking for.
Hackr.io
You will find great quality free courses of any trending programming languages such as:
Code academy also has a very good set of courses. It is especially good for beginners. It has an inbuilt IDE where you can write your code and feedback right away. So in the beginning you even do not need to set up your own IDE. Courses are free. But you can get a subscription for $20 a month to get help from their mentors.
On this page, you will find some courses marked as free and some other paid courses. You can audit the free courses, in the same way, I explained in the edx section above. All the Harvard free courses are available in edx.
More Resources
There are a lot of other free resources as well. I am mentioning a few here.
Udacity
Udacity has a lot of nano degrees that are paid. Nt they have some good free courses as well. Those free courses are not expert level courses. They usually beginner level courses. Here is their course catalog. Search for free courses in the search bar.
Udemy also has a lot of free courses. But not necessarily they are beginner level. Sometimes you may find good courses for free. They also keep giving discounts year-round.
I am sure, you agree after seeing all the free resources that it is not necessary to pay to learn programming or computer science now. The only problem is, it can be hard to focus and stay motivated to keep learning alone at home. If you can find a friend who wants to learn with you that is best. Otherwise, just accept the challenge and go ahead!
Here are some free resources to start with
I am a python user. So I can only give ideas about machine learning in Python. If you are a complete beginner and do not know python that well, practice that one to get better first. Here is a specialization for Python. It will teach you all the python syntax and structures with a lot of practice:
After that practice python to get better. There are several great platforms to provide us with practice problems. I use leetcode and checkio to practice programming. In these platforms, you can see other people’s solutions to get better. There are so many other platforms to practice programming as well: code wars, CodeChef are two more platforms I hear about a lot.
After learning to program well, it is a good idea to learn some computation, data manipulation, and visualization libraries of python. They are essential to learning before you dive into machine learning.
Python has powerful libraries like Numpy, Pandas, Matplotlib, Seaborn, Scipy, and more for computation, data manipulation, visualization, and statistical analysis. Here is a specialization series in Coursera that has two courses on Numpy, Pandas, Matplotlib, Seaborn, Scipy and the third course in on Applied Machine learning:
The applied machine learning course in this specialization does not teach you to develop the algorithms from the scratch. But it will teach you the concepts and how to use these algorithms from the scikit-learn library in python. This is a good start for a beginner. The University of Michigan offers this specialization. The five courses that are included in this specialization are:
This course has some good projects that will add to your portfolio. Also, each week will provide you with a notebook that can be used as a cheatsheet for your future workplace. The material they provide in this course is very good.
The great part about these courses is, these courses will take a project-based approach and each week’s assignment will be a different project. At the end of this, you will have a complete portfolio to show off. The University of Washington offers this course.
CS50’s courses usually very high quality. This course is offered by Harvard University. And you know that you do not expect any less from Harvard. As the title says this is an introductory course. This course will give you some more concepts of machine learning that the previous two courses do not. After taking the previous courses if you take this one, you will learn more models and concepts and also include more projects to your portfolio.
This course will cover graph search algorithms, adversarial search, knowledge representation, logical inference, probability theory, Bayesian networks, Markov models, constraint satisfaction, machine learning, reinforcement learning, neural networks, and natural language processing.
Professor Andrew Ng is a famous professor for his great ability to break down the machine learning concepts. This course is offered by the Stanford Univesity. This course is different than the previous three courses. The three courses above teach you how to use the machine learning algorithms that are built-in python’s libraries.
But Professor Andrew Ng will teach you how to develop the machine learning algorithms from scratch. So, it is lot harder than the previous courses.
But if you can finish it, it will give you a lot of power. It is an eleven weeks long course. But you can audit this course as many times as you want for free. This course will teach you to develop linear regression, logistic regression, neural networks, support vector machine, k mean clustering, principal component analysis, anomaly detection, recommendation system development from scratch.
One thing that may be a bit different about this course that is the assignment instructions are in Matlab. But if you are good at python, you can take the concepts and do them in python. You will find the links to most of the assignments done in python in this page:
I am still working on writing tutorials on the rest of the assignments in python and will be done with them soon.
It looks like a lot! right?
But learning the machine learning libraries will be easier. After you learn to use a couple of algorithms, it will be easier for you to pick up after that. But learning the algorithms from scratch in Andrew Ng’s course will take a lot of time.
These are all the courses I wanted to share for machine learning. Some deep learning courses here.
This is also a specialization. Now they upgraded it and made it a professional certification course on Tensorflow. This series will teach you the use of TensorFlow with projects. The course is not that hard. Because it does not teach you how to develop the deep learning algorithm from scratch. it will teach you how to use the TensorFlow library.
Tensorflow is a very powerful tool for deep learning. It will take care of all the hard mathematics behind the scene. You just need to install it, call the library, and use it.
This specialization will teach you to use TensorFlow for numerical prediction, natural language processing, image classification, and time series prediction.
These are the four courses in this specialization:
This is another series of courses from Professor Andrew Ng. It is hard to avoid Professor Ng if you are trying to learn machine learning and deep learning. He is one of the pioneers!
He teaches the concepts very clearly and teaches you to develop the algorithms in detail. This course will be a bit harder because it is about developing the algorithms from scratch and know it from its core. But it will be worth it if you can finish it. It includes these following courses:
If you can dedicate your time to these courses, you are a pro in machine learning and deep learning. There are a lot of other libraries and topics out there. Because machine learning is a vast field and it is growing every day. But if you have a strong foundation you will pick up any other new libraries fast.
You have to stay open-minded about that. This is a field where learning will never end. No matter how much you learn, a new thing will come up tomorrow.
One last suggestion is that, do not jump into learning anything new to you. Master a few libraries and algorithms first. That will develop judgment in you. You will understand which one is important for you and what is your interest.





Hi Oren,
It is interesting that the ANY_VALUE function is a “legal aggregate” for the FIRST/LAST functions, though not specified explicitly in the documentation
While it is true that the aggregate used here is usually supposed to be a “tie breaker”, just as MIN and MAX obviously are, however, the FIRST/LAST functions, as documented,
also work with some “non-tie-breaker” aggregates like SUM, AVG or COUNT
that may be considered as FIRST/LAST “accumulators”.
But, they do not work with other undocumented aggregates like MEDIAN or LISTAGG,
which look equally legitimate as all the documented ones:
Both of the following queries return error:
select department_id, MEDIAN(hire_date) keep(dense_rank FIRST order by salary) from hr.employees group by department_id / ORA-00923: FROM keyword not found where expected select department_id, LISTAGG(first_name,',') WITHIN GROUP (order by first_name) keep(dense_rank FIRST order by salary) from hr.employees group by department_id / ORA-00923: FROM keyword not found where expectedThe COLLECT function, instead, does not raise an error, but wrongly returns a NULL collection
when there are “ties” in the FIRST/LAST rows, as we can see here, for department_id = 90.
For groups without ties, it returns a correct collection containing the single FIRST/LAST value, similar to MIN/MAX
( we don’t see it here, because LiveSQL does not display collection types output properly,
without a converting helper function ):
select department_id, count(*) keep(dense_rank FIRST order by salary) cnt, min(first_name) keep(dense_rank FIRST order by salary) low, max(first_name) keep(dense_rank FIRST order by salary) high, COLLECT(first_name) keep(dense_rank FIRST order by salary) coll, CASE WHEN COLLECT(first_name) keep(dense_rank FIRST order by salary) IS NULL THEN '***' END null_coll from hr.employees group by department_id / DEPARTMENT_ID CNT LOW HIGH COLL NULL_COLL ----------------------------------------------------------------------------------------- 10 1 Jennifer Jennifer [unsupported data type] - 20 1 Pat Pat [unsupported data type] - 30 1 Karen Karen [unsupported data type] - 40 1 Susan Susan [unsupported data type] - 50 1 TJ TJ [unsupported data type] - 60 1 Diana Diana [unsupported data type] - 70 1 Hermann Hermann [unsupported data type] - 80 1 Sundita Sundita [unsupported data type] - 90 2 Lex Neena [unsupported data type] *** 100 1 Luis Luis [unsupported data type] - 110 1 William William [unsupported data type] - - 1 Kimberely Kimberely [unsupported data type] - 12 rows selected.So, it looks like some documentation adjustments are still required for the FIRST/LAST functions, as well as some enhancements to allow for additional “tie accumulator”
aggregates to be used.
Cheers & Best Regards,
Iudith Mentzel