Pandas is a popular python library that enables easy to use data structures and data analysis tools. Pandas can be used for reading in data, generating statistics, aggregating, feature engineering for machine learning and much more. The Pandas library also provides a suite of tools for string/text manipulation.
In this post, we will walk through some of the most important string manipulation methods provided by pandas.
Let’s get started!
First, let’s import the Pandas library
import pandas as pd
Now, let’s define an example pandas series containing strings:
s = pd.Series(['python is awesome', 'java is just ok', 'c++ is overrated'])
Let’s print this series:
print(s)


We notice that the series has ‘dtype: object’, which is the default type automatically inferred. In general, it is better to have a dedicated type. Since the release of Pandas 1.0, we are now able to specify dedicated types. Make sure Pandas is updated by executing the following command in a terminal:
pip install -U pandas
We can specify ‘dtype: string’ as follows:
s1 = pd.Series(['python is awesome', 'java is just ok', 'c++ is overrated'], dtype='string')
Let’s print the series:


We can see that the series type is specified. It is best to specify the type, and not use the default ‘dtype: object’ because it allows accidental mixtures of types which is not advisable. For example, with ‘dtype: object’ you can have a series with integers, strings, and floats. For this reason, the contents of a ‘dtype: object’ can be vague.
Next, let’s look at some specific string methods. Let’s consider the ‘count()’ method. Let’s modify our series a bit for this example:
s = pd.Series(['python is awesome. I love python.', 'java is just ok. I like python more',
'c++ is overrated. You should consider learning another language, like java or python.'], dtype="string")
Let’s print the new series:
print(s)


Let’s count the number of times the word ‘python’ appears in each strings:
print(s.str.count('python'))


We see this returns a series of ‘dtype: int64’.
Another method we can look at is the ‘isdigit()’ method which returns a boolean series based on whether or not a string is a digit. Let’s define a new series to demonstrate the use of this method. Let’s say we have a series defined by a list of string digits, where missing string digits have the value ‘unknown’:
s2 = pd.Series(['100', 'unknown', '20', '240', 'unknown', '100'], dtype="string")
If we use the ‘isdigit()’ method, we get:
print(s2.str.isdigit())


We can also use the ‘match()’ method to check for the presence of specific strings. Let’s check for the presence of the string ‘100’:
print(s2.str.match('100'))


We can even check for the presence of ‘un’:
print(s2.str.match('un'))
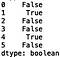
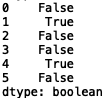
All of which is in concert with what we’d expect. We can also use methods to change the casing of the string text in our series. Let’s go back to our series containing opinions about different programming languages, ‘s1':
s1 = pd.Series(['python is awesome. I love python.', 'java is just ok. I like python more',
'c++ is overrated. You should consider learning another language, like java or python.'], dtype="string")
We can use the ‘upper()’ method to capitalize the text in the strings in our series:
s_upper = s1.str.upper()print(s_upper)


We also use the ‘lower()’ method:
s_lower = s_upper.str.lower()print(s_lower)


We can also get the length of each string using ‘len()’:
print(s1.str.len())
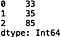

Let’s consider a few more interesting methods. We can use the ‘strip()’ method to remove whitespace. For this, let’s define and print a new example series containing strings with unwanted whitespace:
s3 = pd.Series([' python', 'java', 'ruby ', 'fortran '])
print(s3)


As you can see, there is whitespace to the left of ‘python’ and to the right of ‘ruby’ and ‘fortran’. We can remove this with the ‘strip()’ method:
print(s3.str.strip())
We can also remove whitespace on the left with ‘lstrip’:
print(s3.str.lstrip())


and on the right with ‘rstrip’:
print(s3.str.rstrip())


In the previous two examples I was working with ‘dtype=object’ but, again, try your best to remember to specify ‘dtype=strings’ if you are working with strings.
You can also use the strip methods to remove unwanted characters in your text. Often times, in real text data you have the presence of ‘\n’ which indicates a new line. Let’s modify our series and demonstrate the use of strip in this case:
s3 = pd.Series([' python\n', 'java\n', 'ruby \n', 'fortan \n'])
print(s3)


An we can remove the ‘\n’ character with ‘strip()’:
print(s3.str.strip(' \n'))


In this specific example, I’d like to point out a difference in behavior between ‘dtype=object’ and ‘dtype= strings’. If we specify ‘dtype= strings’ and print the series:
s4 = pd.Series([' python\n', 'java\n', 'ruby \n', 'fortan \n'], dtype='string')
print(s4)


We see that ‘\n’ has been interpreted. Nonetheless using ‘strip()’ on the newly specified series still works:
print(s4.str.strip(‘ \n’))


The last method we will look at is the ‘replace()’ method. Suppose we have a new series with poorly formatted dollar amounts:
s5 = pd.Series(['$#1200', 'dollar1,000', 'dollar10000', '$500'], dtype="string")
print(s5)

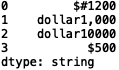
We can use the ‘replace()’ method to get rid of the unwanted ‘#’ in the first element:
print(s5.str.replace('#', ''))
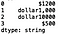

We can also replace the text ‘dollar’ with an actual ‘$’ sign:
s5 = s5.str.replace('#', '')
s5 = s5.str.replace('dollar', '$')
print(s5)
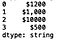
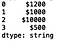
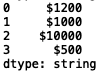
Finally, we can remove the ‘,’ from the 2nd element:
s5 = s5.str.replace(',', '')
print(s5)
I will stop here but feel free to play around with the methods a bit more. You can try applying some of the Pandas methods to freely available data sets like Yelp or Amazon reviews which can be found on Kaggle or to your own work if it involves processing text data.
To summarize, we discussed some basic Pandas methods for string manipulation. We went over generating boolean series based on the presence of specific strings, checking for the presence of digits in strings, removing unwanted whitespace or characters, and replacing unwanted characters with a character of choice.
There are many more Pandas string methods I did not go over in this post. These include methods for concatenation, indexing, extracting substrings, pattern matching and much more. I will save these methods for a future article. I hope you found this post interesting and/or useful. The code in this post is available on GitHub. Thank you for reading!




No comments:
Post a Comment